Небольшие лайфхаки с Proxmox

Система виртуализации Proxmox, работающая на базе гипервизора KVM — неплохое Open Source решение, которое позваляет создавать кластеры, аналогичные VMware. Установка и использование данного продукта в целом не вызывает лишних сложностей и отличается последовательностью и логичностью. Однако, в процессе эксплуатации, нужно быть готовым к небольшим доработкам и донастройкам самой системы виртуализации. Небольшие лайфхаки, которые приходилось использовать в практике, хотелось бы опубликовать в этой статье. Они позволят избежать очевидных небольших «недоработок» в системе при ее использовании с чистого листа. Информация изложенная в статье актуальна для версии Proxmox-VE 6.2.
Отключаем платные источники пакетов Proxmox
После установки системы виртуализации Proxmox-VE на конкретный физический хост по умолчанию включены apt источники пакетов для Enterprise версии. Однако, данная версия требует покупки подписок, и если их не купить, будет постоянно появляться ошибка в веб интерфейсе системы управления. Для того, чтобы избавиться от нее в случае использования бесплатной версии программы, нам нужно скорректировать файл источников установки пакетов в системе — /etc/apt/sources.list.d/pve-enterprise.list. Комментируем в данном файле единственную содержащуюся строчку и получаем следующий контент внутри этого фала.
Теперь выполним команду apt update в консоли системы и сможем использовать Proxmox без постоянного вывода ошибок об отсутствии платных подписок.
Включаем бесплатные источники пакетов Proxmox
По умолчанию в системе не настроены источники пакетов apt, специфичные для Proxmox-VE, которые могут использоваться для установки без покупки Enterprise подписок. Чтобы не нарушать целостность системы и не устанавливать аналогичные пакеты из других источников, рекомендуется добавить источники оригинальные для Proxmox. Для этого создаем в консоли файл /etc/apt/sources.list.d/pve-no-subscription.list и добавляем в него одну следующую строчку, указанную ниже.
Аналогично, после создания и редактирования вышеуказанного файла, выполняем команду apt update, по итогу выполнения которой, можем полноценно устанавливать новые необходимые пакеты в систему.
Используем утилиту ifupdown2
Для управления сетевыми интерфейсами из командной строки рекомендуется в системе Proxmox-VE использовать строго утилиту ifupdown2. Так, если в консоли попытаться перезагрузить настройки сетевой подсистемы с помощью systemctl restart networking, то можно получить проблемы с доступом в сеть из виртуальных машин на данном хосте. Поэтому желательно при первоначальной настройке системы установить сразу пакет ifupdown2 с помощью команды:
Теперь, чтобы перезагрузить настройки сетевой подсистемы из консоли мы просто выполняем следующую команду.
Особенности использования внешнего CEPH хранилища
Сам по себе Proxmox поддерживает CEPH внутри себя и позволяет создавать гиперконвергентные кластеры. Однако, в случае использования внешней системы хранения CEPH через протокол RBD могут возникать лишние оповещения и ошибки в работе отдельных утилит. Чтобы этого избежать, проводим небольшие манипуляции. Первым делом создаем файл /etc/ceph/ceph.conf, если его не было в системе. После чего добавляем в данный файл описание сервисов внешних мониторов CEPH, которые используются при подключение по протоколу RBD. Пример содержания данного файла привожу ниже.
Когда мы завершим выполнение данных манипуляций, использование внешнего кластера CEPH в системе Proxmox не будет вызывать непонятных ошибок и сообщений.
Заключение
Показал в статье небольшие донастройки в системе Proxmox-VE, которые позваляют более комфортно ее эксплуатировать. При этом сам базовый функционал данной системы виртуализации нормально работает из коробки и позволяет использовать ее как хорошую альтернативу VMware vSphere.
Сeph — от «на коленке» до «production»
Выбор CEPH. Часть 1
У нас было пять стоек, десять оптических свичей, настроенный BGP, пару десятков SSD и куча SAS дисков всех цветов и размеров, а ещё proxmox и желание засунуть всю статику в собственное S3 хранилище. Не то чтобы это всё было нужно для виртуализации, но раз начал использовать opensource — то иди в своём увлечении до конца. Единственное, что меня беспокоило — это BGP. В мире нет никого более беспомощного, безответственного и безнравственного, чем внутренняя маршртутизация по BGP. И я знал, что довольно скоро мы в это окунёмся.

Задача стояла банальная — имелся CEPH, работал не очень хорошо. Надо было сделать «хорошо».
Доставшийся мне кластер был разнородным, настроенным на скорую руку и практически не тюнингованным. Он состоял из двух групп разных нод, с одной общей сеткой выполняющей роль как cluster так и public network. Ноды были набиты четырьмя типами дисков — два типа SSD, собранными в два отдельных placement rule и два типа HDD разного размера, собранными в третью группу. Проблема с разными размерами была решена разными весами OSD.
Саму настройку разделили на две части — тюнинг операционной системы и тюнинг самого CEPH и его настроек.
Прокачка OS
Network
Высокое latency сказывалось как при записи, так и при балансировке. При записи — потому, что клиент не получит ответ об успешной записи, пока реплики данных в других плейсмент группах не подтвердят успех. Поскольку правила распределения реплик в CRUSH map у нас были по одной реплике на хост, то сеть использовалась всегда.
Потому первым делом решил слегка настроить текущую сеть, параллельно пытаясь убедить переехать на раздельные сети.
Для начала покрутил настройки сетевых карт. Начал с настройки очередей:
Видно, что current параметры далеки от maximums. Увеличил:
Руководствуясь отличной статьей
увеличил длинну очереди отправки txqueuelen с 1000 до 10 000
Ну и следуя документации самого ceph
увеличил MTU до 9000.
Добавил в /etc/network/interfaces, чтоб все вышеперечисленное грузилось при старте
После чего, следуя этой же статье, начал вдумчиво накручивать ручки ядра 4.15. Учитывая, что на нодах 128G RAM, получился некий файл конфигурации для sysctl
Сluster network была выделена на отдельных 10Gbps сетевых интерфейсах в отдельную плоскую сеть. На каждой машине были поставлены сетевые двухпортовые карты mellanox 10/25 Gbps, воткнутые в два отдельных 10Gbps свича. Агрегация осуществлялась с помощью OSPF, поскольку бондинг с lacp почему-то показал суммарную пропускную способность максимум в 16 Gbps, в то время как ospf успешно утилизировал полностью обе десятки на каждой машине. В дальнейших планах было воспользоваться ROCE на этих меланоксах, для уменьшения лэтэнси. Как настраивали эту часть сети:
Подробнее по настройке OSPF: Основная задача — агрегировать два линка и иметь fault tolerance.
два сетевых интерфейса настроены в две простых плоских сети — 10.10.10.0/24 и 10.10.20.0/24
по которым машины друг друга видят.
Следующим шагом решил оптимизировать работу дисков. Для SSD поменял планировщик на noop, для HDD — deadline. Если грубо — то NOOP работает по принципу «кто первый встал — того и тапки», что по английский звучит как «FIFO (First In, First Out)». Запросы встают в очередь по мере их поступления. DEADLINE более заточен на чтение, плюс процесс из очереди получает практически монопольный доступ к диску на момент операции. Для нашей системы это отлично подходит — ведь с каждым диском работает только один процесс — OSD daemon.
(Желающие погрузится в планировщик ввода-вывода могут почитать о нем тут:
http://www.admin-magazine.com/HPC/Articles/Linux-I-O-Schedulers
Предпочитающие читать на русском: https://www.opennet.ru/base/sys/linux_shedulers.txt.html)
В рекомендациях по тюнингу линукса советуют так-же увеличить nr_request
nr_requests
The value of nr_requests determines the amount of I/O requests that get buffered before the I/O scheduler sends / receives data to the block device, if you are using a RAID card / Block Device that can handle a larger queue than what the I/O scheduler is set to, raising the value of nr_requests may help to improve throughout and reduce server load when large amounts of I/O occur on the server. If you are using Deadline or CFQ as the scheduler, it is suggested that you should set the nr_request value to 2 times the value of queue depth.
НО! Сами граждане разработчики CEPH убеждают нас, что их система приоритетов работает лучше

WBThrottle и/или nr_requests
Файловое хранилище использует для записи буферизованные операции ввода/ вывода; это привносит целый ряд преимуществ если журнал файлового хранения находится на более быстром носителе. Запросы клиентов получают уведомления как только данные записаны в журнал, а затем сбрасываются на сам диск данных в более позднее время пользуясь стандартной функциональностью Linux. Это делает возможным для OSD шпиндельных дисков предоставлять латентность записи аналогичную SSD при записях малыми пакетами. Такая задержанная отложенная запись также позволяет самому ядру перестраивать запросы операций ввода/ вывода к диску с надеждой либо слить их воедино, либо позволить имеющимся головкам диска выбрать некий более оптимальный путь поверх своих пластин. Конечный эффект состоит в том, что вы можете выжать слегка больше операций ввода/ вывода из каждого диска чем это было бы возможно при прямых или синхронных операциях ввода/ вывода.
Однако, возникает определённая проблема если объём приходящих записей в данный кластер Ceph будут опережать все возможности лежащих в основе дисков. При таком сценарии общее число находящихся в рассмотрении операций ввода/ вывода в ожидании записи на диск могут неконтролируемо расти и иметь результатом очереди операций ввода/ вывода, заполняющую весь диск и очереди Ceph. Запросы на чтение воздействуют в особенности плохо, так как они застревают между запросами записи, которые могут требовать нескольких секунд для сброса на основной диск.
Для победы над этой проблемой Ceph имеет встроенный в файловое хранение механизм дросселирования отложенной записи (writeback) с названием WBThrottle. Он разработан для ограничения общего объёма операций ввода/ вывода отложенной записи, которые могут выстраиваться в очередь и начинать свой процесс сброса раньше чем чем это произошло бы естественным образом за счёт включения самим ядром. К сожалению, тестирование демонстрирует, что установленные по умолчанию значения всё ещё могут не урезать имеющееся поведение до уровня, который может уменьшать такое воздействие на латентность операций чтения. Регулировка может изменить это поведение и уменьшить общие длины очередей записи и сделать возможным не сильным такое воздействие. Однако имеется некий компромисс: уменьшая общее максимальное число разрешённых к постановке в очередь записей, вы можете снизить возможность самого ядра максимизировать свою эффективность упорядочения поступающих запросов. Стоит немного задуматься что вам более необходимо для вашего конкретного случая применения, рабочих нагрузок и регулировать под соответствие им.
Чтобы управлять глубиной такой очереди отложенной записи, вы можете либо уменьшать общее максимальное количество невыполненных операций ввода/ вывода, применяя установки WBThrottle, либо уменьшая максимальное значение для невыполненных операций на самом блочном уровне своего ядра. И то, и другое могут эффективно управлять одним и тем же поведением и именно ваши предпочтения будут в основе реализации данной настройки.
Также следует отметить, что имеющаяся в Ceph система приоритетов операций является более эффективной для более коротких запросов на дисковом уровне. При сокращении общей очереди к данному диску основное местоположение нахождения в очереди перемещается в Ceph, где он имеет большее управление над тем какой приоритет имеет операция ввода/ вывода. Рассмотрим следующий пример:
COMMON
И еще несколько настроек ядра, позволяющие сделать вашу тачку мягкой и шелковистой выжать еще немного производительности из железа
Deploy Hyper-Converged Ceph Cluster
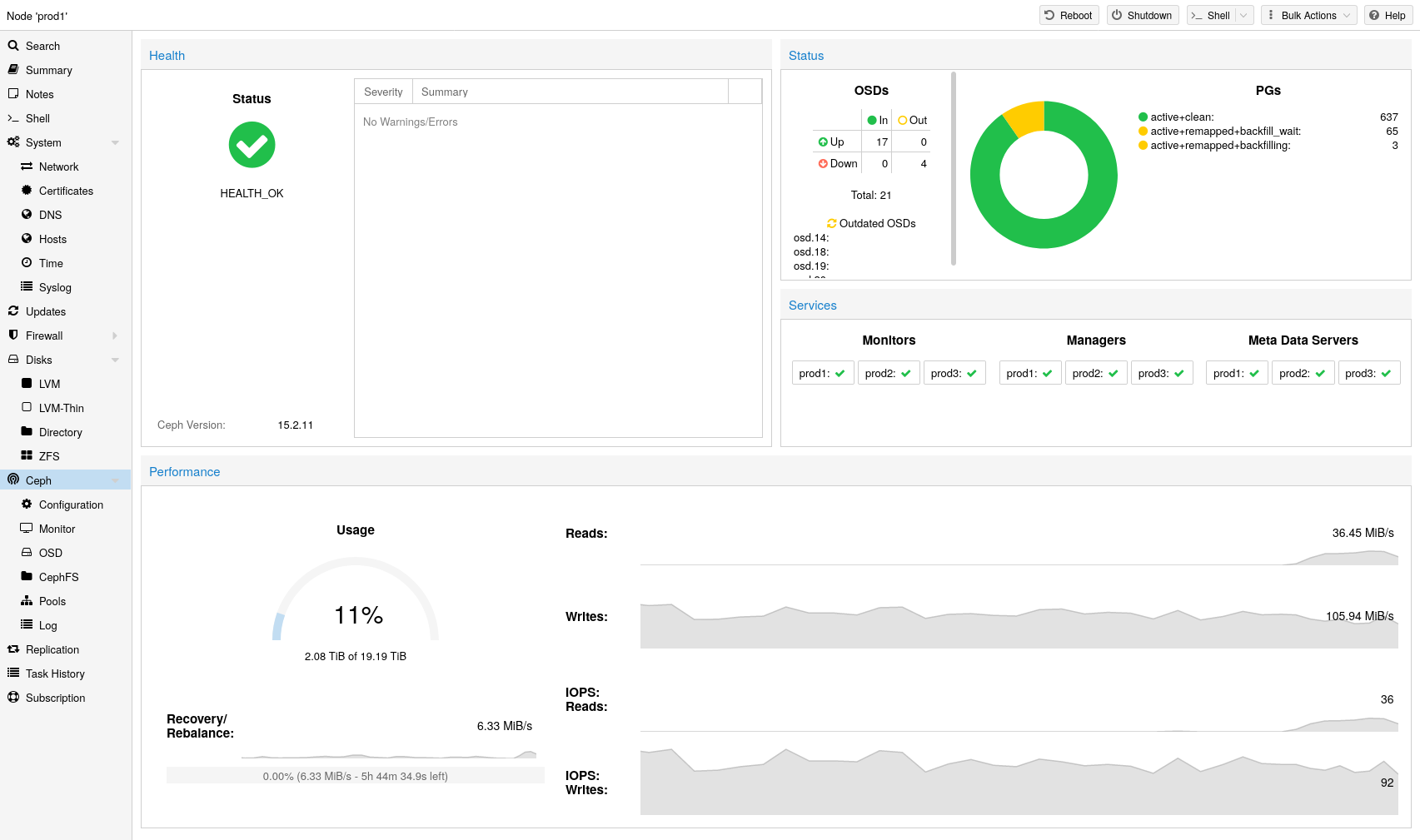
Proxmox VE unifies your compute and storage systems, that is, you can use the same physical nodes within a cluster for both computing (processing VMs and containers) and replicated storage. The traditional silos of compute and storage resources can be wrapped up into a single hyper-converged appliance. Separate storage networks (SANs) and connections via network attached storage (NAS) disappear. With the integration of Ceph, an open source software-defined storage platform, Proxmox VE has the ability to run and manage Ceph storage directly on the hypervisor nodes.
Ceph is a distributed object store and file system designed to provide excellent performance, reliability and scalability.
Easy setup and management via CLI and GUI
Scalable to the exabyte level
Setup pools with different performance and redundancy characteristics
Data is replicated, making it fault tolerant
Runs on commodity hardware
No need for hardware RAID controllers
For small to medium-sized deployments, it is possible to install a Ceph server for RADOS Block Devices (RBD) directly on your Proxmox VE cluster nodes (see Ceph RADOS Block Devices (RBD)). Recent hardware has a lot of CPU power and RAM, so running storage services and VMs on the same node is possible.
Ceph Monitor (ceph-mon)
Ceph Manager (ceph-mgr)
Ceph OSD (ceph-osd; Object Storage Daemon)
| We highly recommend to get familiar with Ceph [Ceph intro https://docs.ceph.com/en/nautilus/start/intro/] , its architecture [Ceph architecture https://docs.ceph.com/en/nautilus/architecture/] and vocabulary [Ceph glossary https://docs.ceph.com/en/nautilus/glossary] . |
Precondition
To build a hyper-converged Proxmox + Ceph Cluster, you must use at least three (preferably) identical servers for the setup.
Check also the recommendations from Ceph’s website.
A high CPU core frequency reduces latency and should be preferred. As a simple rule of thumb, you should assign a CPU core (or thread) to each Ceph service to provide enough resources for stable and durable Ceph performance.
Memory
Especially in a hyper-converged setup, the memory consumption needs to be carefully monitored. In addition to the predicted memory usage of virtual machines and containers, you must also account for having enough memory available for Ceph to provide excellent and stable performance.
As a rule of thumb, for roughly 1 TiB of data, 1 GiB of memory will be used by an OSD. Especially during recovery, re-balancing or backfilling.
The daemon itself will use additional memory. The Bluestore backend of the daemon requires by default 3-5 GiB of memory (adjustable). In contrast, the legacy Filestore backend uses the OS page cache and the memory consumption is generally related to PGs of an OSD daemon.
Network
We recommend a network bandwidth of at least 10 GbE or more, which is used exclusively for Ceph. A meshed network setup
[Full Mesh Network for Ceph https://pve.proxmox.com/wiki/Full_Mesh_Network_for_Ceph_Server]
is also an option if there are no 10 GbE switches available.
The volume of traffic, especially during recovery, will interfere with other services on the same network and may even break the Proxmox VE cluster stack.
Furthermore, you should estimate your bandwidth needs. While one HDD might not saturate a 1 Gb link, multiple HDD OSDs per node can, and modern NVMe SSDs will even saturate 10 Gbps of bandwidth quickly. Deploying a network capable of even more bandwidth will ensure that this isn’t your bottleneck and won’t be anytime soon. 25, 40 or even 100 Gbps are possible.
Disks
When planning the size of your Ceph cluster, it is important to take the recovery time into consideration. Especially with small clusters, recovery might take long. It is recommended that you use SSDs instead of HDDs in small setups to reduce recovery time, minimizing the likelihood of a subsequent failure event during recovery.
In general, SSDs will provide more IOPS than spinning disks. With this in mind, in addition to the higher cost, it may make sense to implement a class based separation of pools. Another way to speed up OSDs is to use a faster disk as a journal or DB/Write-Ahead-Log device, see creating Ceph OSDs. If a faster disk is used for multiple OSDs, a proper balance between OSD and WAL / DB (or journal) disk must be selected, otherwise the faster disk becomes the bottleneck for all linked OSDs.
Aside from the disk type, Ceph performs best with an even sized and distributed amount of disks per node. For example, 4 x 500 GB disks within each node is better than a mixed setup with a single 1 TB and three 250 GB disk.
You also need to balance OSD count and single OSD capacity. More capacity allows you to increase storage density, but it also means that a single OSD failure forces Ceph to recover more data at once.
Avoid RAID
As Ceph handles data object redundancy and multiple parallel writes to disks (OSDs) on its own, using a RAID controller normally doesn’t improve performance or availability. On the contrary, Ceph is designed to handle whole disks on it’s own, without any abstraction in between. RAID controllers are not designed for the Ceph workload and may complicate things and sometimes even reduce performance, as their write and caching algorithms may interfere with the ones from Ceph.
| The above recommendations should be seen as a rough guidance for choosing hardware. Therefore, it is still essential to adapt it to your specific needs. You should test your setup and monitor health and performance continuously. |
Initial Ceph Installation & Configuration
Using the Web-based Wizard
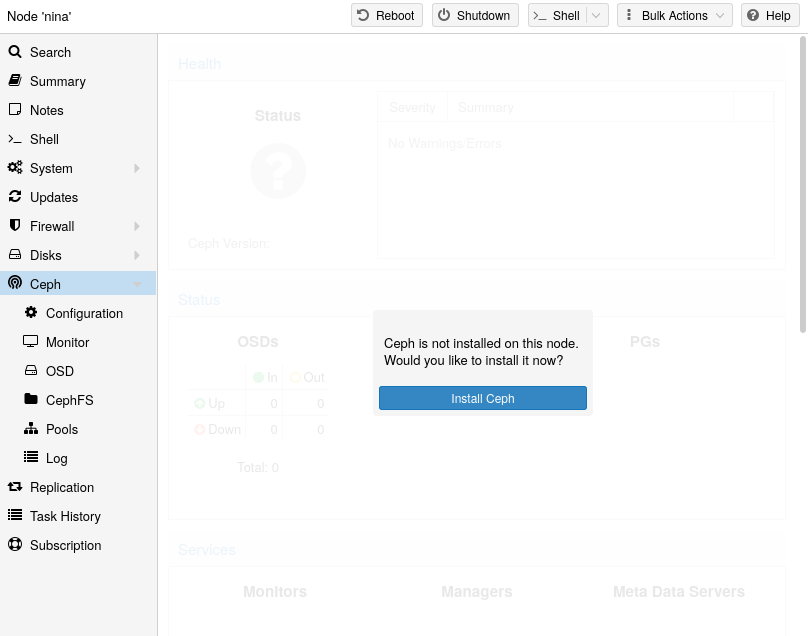
With Proxmox VE you have the benefit of an easy to use installation wizard for Ceph. Click on one of your cluster nodes and navigate to the Ceph section in the menu tree. If Ceph is not already installed, you will see a prompt offering to do so.
The wizard is divided into multiple sections, where each needs to finish successfully, in order to use Ceph.
First you need to chose which Ceph version you want to install. Prefer the one from your other nodes, or the newest if this is the first node you install Ceph.
After starting the installation, the wizard will download and install all the required packages from Proxmox VE’s Ceph repository.
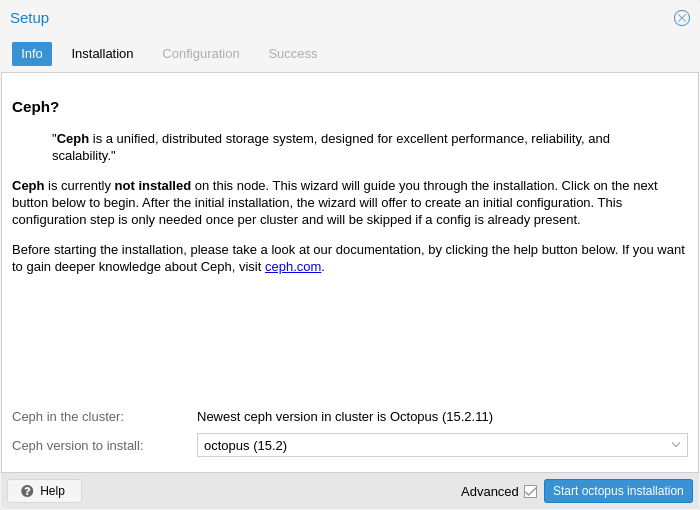
After finishing the installation step, you will need to create a configuration. This step is only needed once per cluster, as this configuration is distributed automatically to all remaining cluster members through Proxmox VE’s clustered configuration file system (pmxcfs).
The configuration step includes the following settings:
Public Network: You can set up a dedicated network for Ceph. This setting is required. Separating your Ceph traffic is highly recommended. Otherwise, it could cause trouble with other latency dependent services, for example, cluster communication may decrease Ceph’s performance.
Cluster Network: As an optional step, you can go even further and separate the OSD replication & heartbeat traffic as well. This will relieve the public network and could lead to significant performance improvements, especially in large clusters.
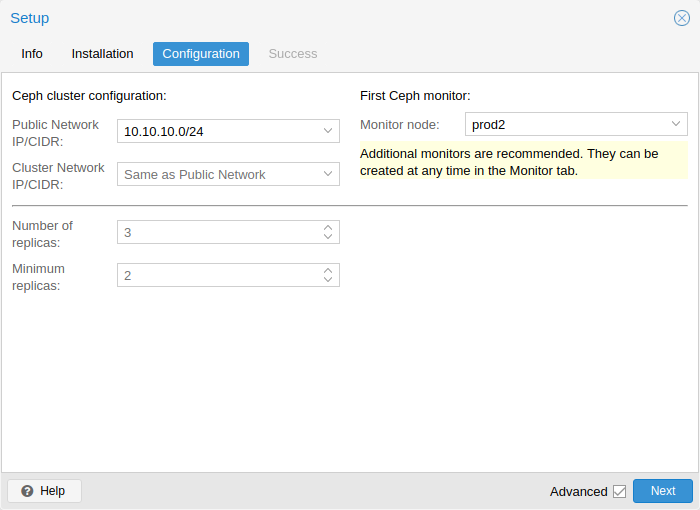
You have two more options which are considered advanced and therefore should only changed if you know what you are doing.
Number of replicas: Defines how often an object is replicated
Minimum replicas: Defines the minimum number of required replicas for I/O to be marked as complete.
Additionally, you need to choose your first monitor node. This step is required.
That’s it. You should now see a success page as the last step, with further instructions on how to proceed. Your system is now ready to start using Ceph. To get started, you will need to create some additional monitors, OSDs and at least one pool.
The rest of this chapter will guide you through getting the most out of your Proxmox VE based Ceph setup. This includes the aforementioned tips and more, such as CephFS, which is a helpful addition to your new Ceph cluster.
CLI Installation of Ceph Packages
Alternatively to the the recommended Proxmox VE Ceph installation wizard available in the web-interface, you can use the following CLI command on each node:
This sets up an apt package repository in /etc/apt/sources.list.d/ceph.list and installs the required software.
Initial Ceph configuration via CLI
Use the Proxmox VE Ceph installation wizard (recommended) or run the following command on one node:
Ceph Monitor
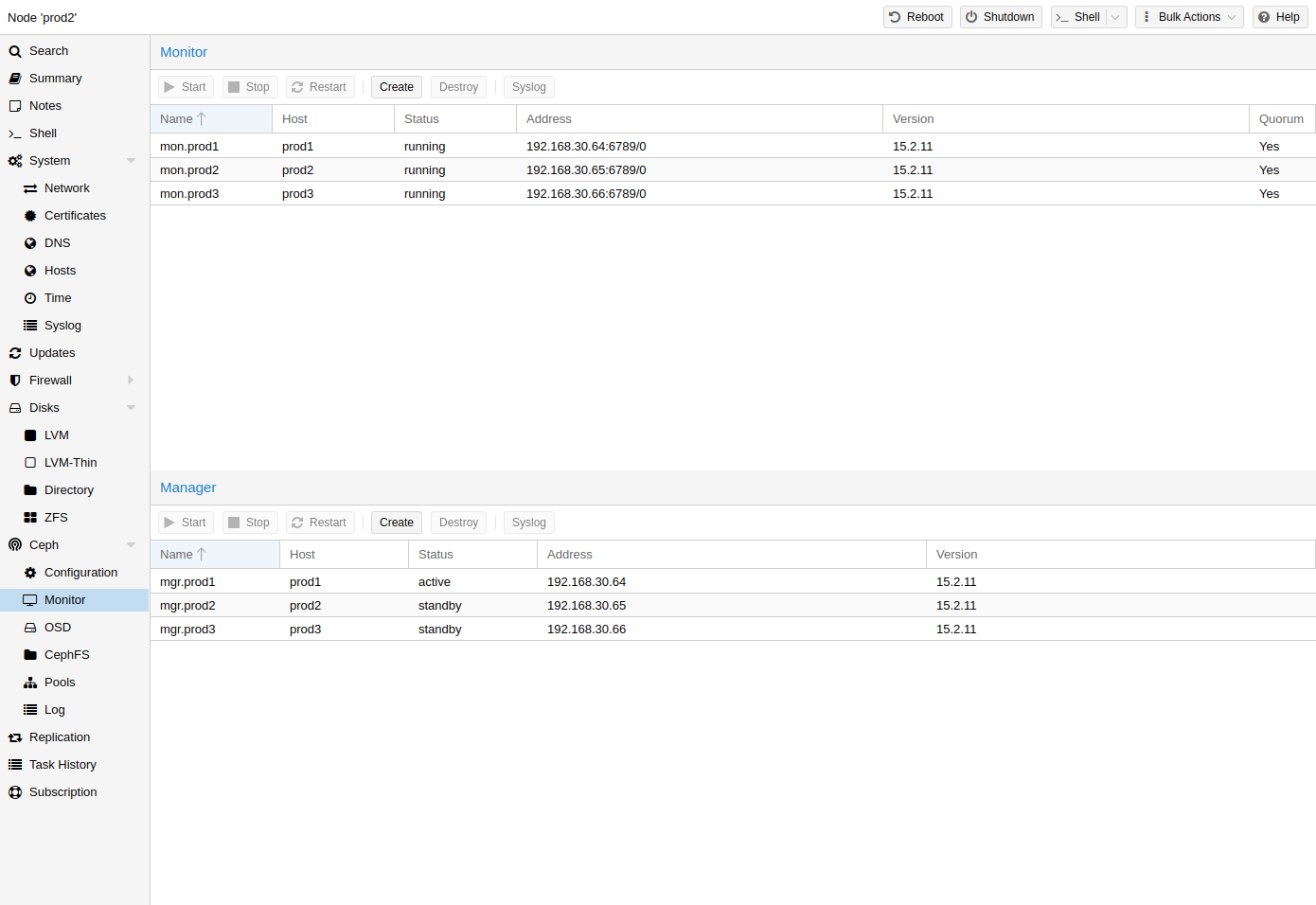
The Ceph Monitor (MON)
[Ceph Monitor https://docs.ceph.com/en/nautilus/start/intro/]
maintains a master copy of the cluster map. For high availability, you need at least 3 monitors. One monitor will already be installed if you used the installation wizard. You won’t need more than 3 monitors, as long as your cluster is small to medium-sized. Only really large clusters will require more than this.
Create Monitors
On each node where you want to place a monitor (three monitors are recommended), create one by using the Ceph → Monitor tab in the GUI or run:
Destroy Monitors
To remove a Ceph Monitor via the GUI, first select a node in the tree view and go to the Ceph → Monitor panel. Select the MON and click the Destroy button.
To remove a Ceph Monitor via the CLI, first connect to the node on which the MON is running. Then execute the following command:
Ceph Manager
The Manager daemon runs alongside the monitors. It provides an interface to monitor the cluster. Since the release of Ceph luminous, at least one ceph-mgr
[Ceph Manager https://docs.ceph.com/en/nautilus/mgr/]
daemon is required.
Create Manager
Multiple Managers can be installed, but only one Manager is active at any given time.
| It is recommended to install the Ceph Manager on the monitor nodes. For high availability install more then one manager. |
Destroy Manager
To remove a Ceph Manager via the GUI, first select a node in the tree view and go to the Ceph → Monitor panel. Select the Manager and click the Destroy button.
To remove a Ceph Monitor via the CLI, first connect to the node on which the Manager is running. Then execute the following command:
| While a manager is not a hard-dependency, it is crucial for a Ceph cluster, as it handles important features like PG-autoscaling, device health monitoring, telemetry and more. |
Ceph OSDs
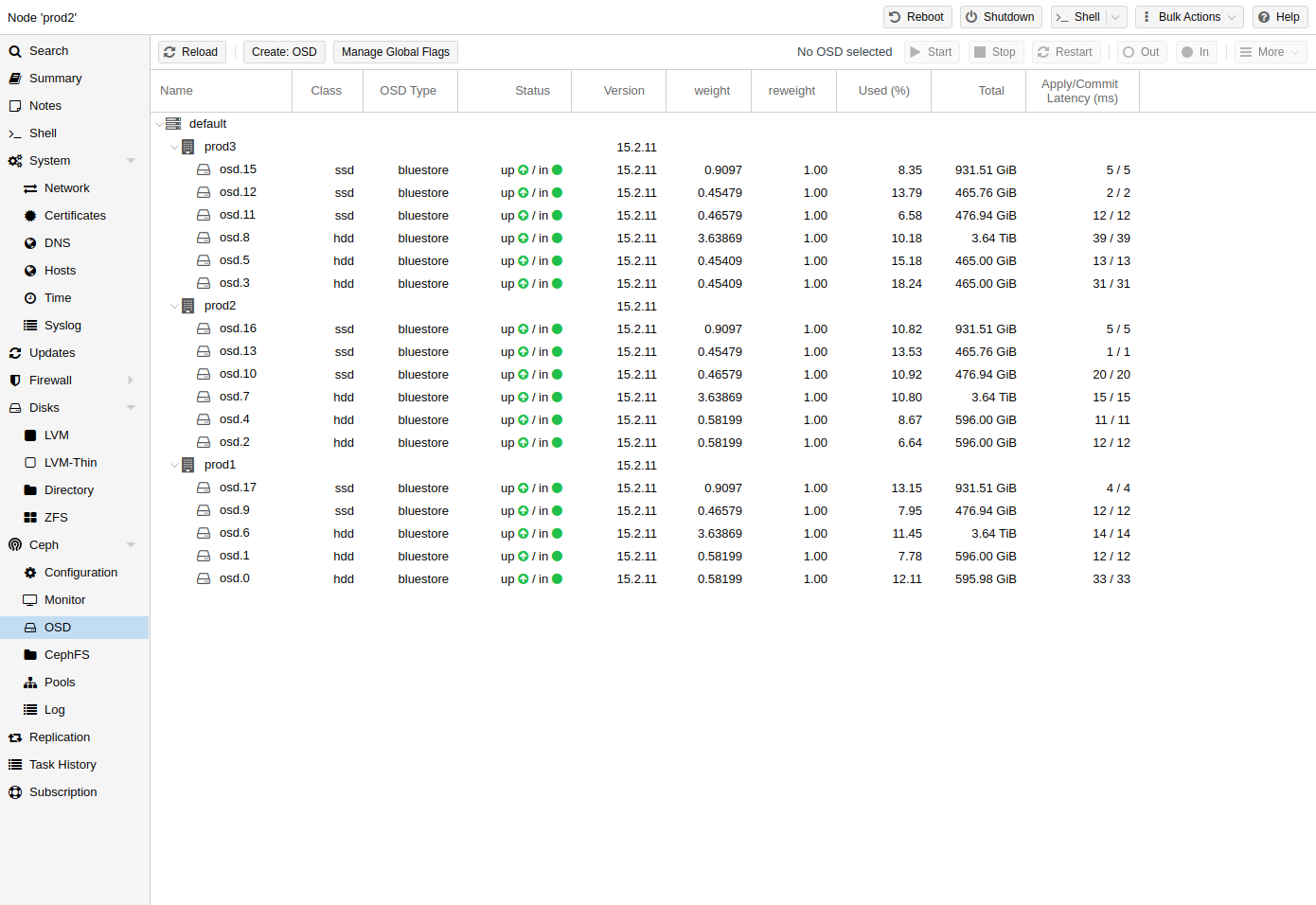
Ceph Object Storage Daemons store objects for Ceph over the network. It is recommended to use one OSD per physical disk.
Create OSDs
| We recommend a Ceph cluster with at least three nodes and at least 12 OSDs, evenly distributed among the nodes. |
If the disk was in use before (for example, for ZFS or as an OSD) you first need to zap all traces of that usage. To remove the partition table, boot sector and any other OSD leftover, you can use the following command:
Ceph Bluestore
Starting with the Ceph Kraken release, a new Ceph OSD storage type was introduced called Bluestore
[Ceph Bluestore https://ceph.com/community/new-luminous-bluestore/]
. This is the default when creating OSDs since Ceph Luminous.
Block.db and block.wal
If you want to use a separate DB/WAL device for your OSDs, you can specify it through the -db_dev and -wal_dev options. The WAL is placed with the DB, if not specified separately.
You can directly choose the size of those with the -db_size and -wal_size parameters respectively. If they are not given, the following values (in order) will be used:
bluestore_block_
… database, section osd
… database, section global
… file, section global
10% (DB)/1% (WAL) of OSD size
| The DB stores BlueStore’s internal metadata, and the WAL is BlueStore’s internal journal or write-ahead log. It is recommended to use a fast SSD or NVRAM for better performance. |
Ceph Filestore
Before Ceph Luminous, Filestore was used as the default storage type for Ceph OSDs. Starting with Ceph Nautilus, Proxmox VE does not support creating such OSDs with pveceph anymore. If you still want to create filestore OSDs, use ceph-volume directly.
Destroy OSDs
To remove an OSD via the CLI run the following commands.
| The first command instructs Ceph not to include the OSD in the data distribution. The second command stops the OSD service. Until this time, no data is lost. |
The following command destroys the OSD. Specify the -cleanup option to additionally destroy the partition table.
Ceph Pools
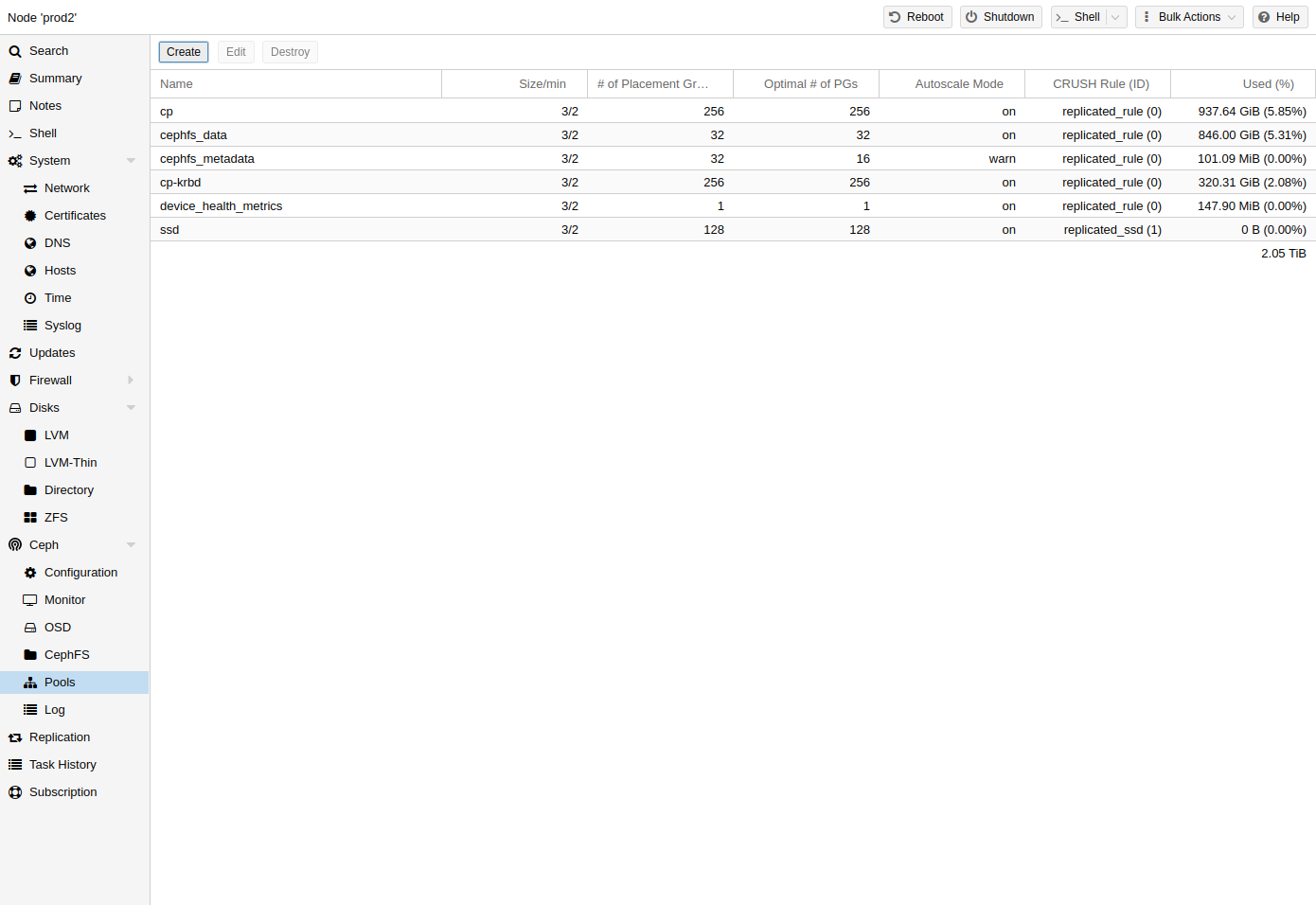
Create and Edit Pools
You can create and edit pools from the command line or the web-interface of any Proxmox VE host under Ceph → Pools.
When no options are given, we set a default of 128 PGs, a size of 3 replicas and a min_size of 2 replicas, to ensure no data loss occurs if any OSD fails.
| Do not set a min_size of 1. A replicated pool with min_size of 1 allows I/O on an object when it has only 1 replica, which could lead to data loss, incomplete PGs or unfound objects. |
It is advised that you either enable the PG-Autoscaler or calculate the PG number based on your setup. You can find the formula and the PG calculator
[PG calculator https://web.archive.org/web/20210301111112/http://ceph.com/pgcalc/]
online. From Ceph Nautilus onward, you can change the number of PGs
[Placement Groups https://docs.ceph.com/en/nautilus/rados/operations/placement-groups/]
after the setup.
The PG autoscaler
[Automated Scaling https://docs.ceph.com/en/nautilus/rados/operations/placement-groups/#automated-scaling]
can automatically scale the PG count for a pool in the background. Setting the Target Size or Target Ratio advanced parameters helps the PG-Autoscaler to make better decisions.
| If you would also like to automatically define a storage for your pool, keep the ‘Add as Storage’ checkbox checked in the web-interface, or use the command line option —add_storages at pool creation. |
Pool Options
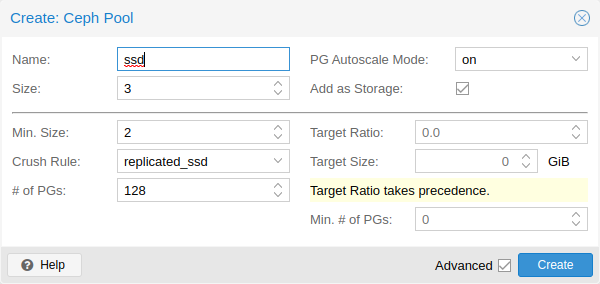
The following options are available on pool creation, and partially also when editing a pool.
The name of the pool. This must be unique and can’t be changed afterwards.
Configure a VM or container storage using the new pool. Default: true (only visible on creation).
The rule to use for mapping object placement in the cluster. These rules define how data is placed within the cluster. See Ceph CRUSH & device classes for information on device-based rules.
The ratio of data that is expected in the pool. The PG autoscaler uses the ratio relative to other ratio sets. It takes precedence over the target size if both are set.
The estimated amount of data expected in the pool. The PG autoscaler uses this size to estimate the optimal PG count.
The minimum number of placement groups. This setting is used to fine-tune the lower bound of the PG count for that pool. The PG autoscaler will not merge PGs below this threshold.
Further information on Ceph pool handling can be found in the Ceph pool operation
[Ceph pool operation https://docs.ceph.com/en/nautilus/rados/operations/pools/]
manual.
Destroy Pools
To destroy a pool via the GUI, select a node in the tree view and go to the Ceph → Pools panel. Select the pool to destroy and click the Destroy button. To confirm the destruction of the pool, you need to enter the pool name.
Run the following command to destroy a pool. Specify the -remove_storages to also remove the associated storage.
| Pool deletion runs in the background and can take some time. You will notice the data usage in the cluster decreasing throughout this process. |
PG Autoscaler
The PG autoscaler allows the cluster to consider the amount of (expected) data stored in each pool and to choose the appropriate pg_num values automatically. It is available since Ceph Nautilus.
You may need to activate the PG autoscaler module before adjustments can take effect.
The autoscaler is configured on a per pool basis and has the following modes:
A health warning is issued if the suggested pg_num value differs too much from the current value.
The pg_num is adjusted automatically with no need for any manual interaction.
No automatic pg_num adjustments are made, and no warning will be issued if the PG count is not optimal.
| By default, the autoscaler considers tuning the PG count of a pool if it is off by a factor of 3. This will lead to a considerable shift in data placement and might introduce a high load on the cluster. |
Ceph CRUSH & device classes
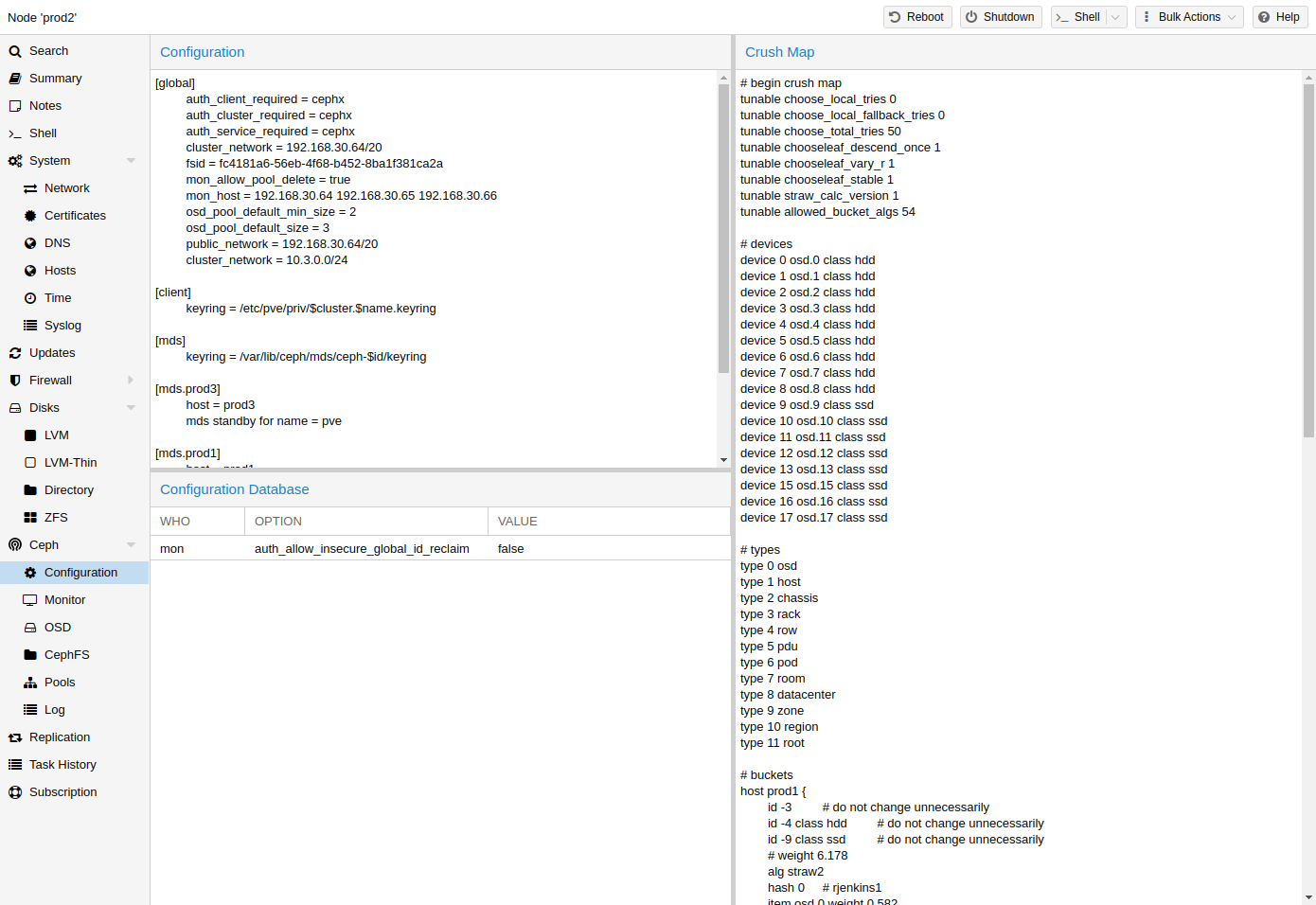
The
[CRUSH https://ceph.com/wp-content/uploads/2016/08/weil-crush-sc06.pdf]
(Controlled Replication Under Scalable Hashing) algorithm is at the foundation of Ceph.
CRUSH calculates where to store and retrieve data from. This has the advantage that no central indexing service is needed. CRUSH works using a map of OSDs, buckets (device locations) and rulesets (data replication) for pools.
| Further information can be found in the Ceph documentation, under the section CRUSH map [CRUSH map https://docs.ceph.com/en/nautilus/rados/operations/crush-map/] . |
This map can be altered to reflect different replication hierarchies. The object replicas can be separated (e.g., failure domains), while maintaining the desired distribution.
A common configuration is to use different classes of disks for different Ceph pools. For this reason, Ceph introduced device classes with luminous, to accommodate the need for easy ruleset generation.
The device classes can be seen in the ceph osd tree output. These classes represent their own root bucket, which can be seen with the below command.
Example output form the above command:
To instruct a pool to only distribute objects on a specific device class, you first need to create a ruleset for the device class:
name of the rule, to connect with a pool (seen in GUI & CLI)
which crush root it should belong to (default ceph root «default»)
at which failure-domain the objects should be distributed (usually host)
what type of OSD backing store to use (e.g., nvme, ssd, hdd)
Once the rule is in the CRUSH map, you can tell a pool to use the ruleset.
| If the pool already contains objects, these must be moved accordingly. Depending on your setup, this may introduce a big performance impact on your cluster. As an alternative, you can create a new pool and move disks separately. |
Ceph Client
Following the setup from the previous sections, you can configure Proxmox VE to use such pools to store VM and Container images. Simply use the GUI to add a new RBD storage (see section Ceph RADOS Block Devices (RBD)).
You also need to copy the keyring to a predefined location for an external Ceph cluster. If Ceph is installed on the Proxmox nodes itself, then this will be done automatically.
CephFS
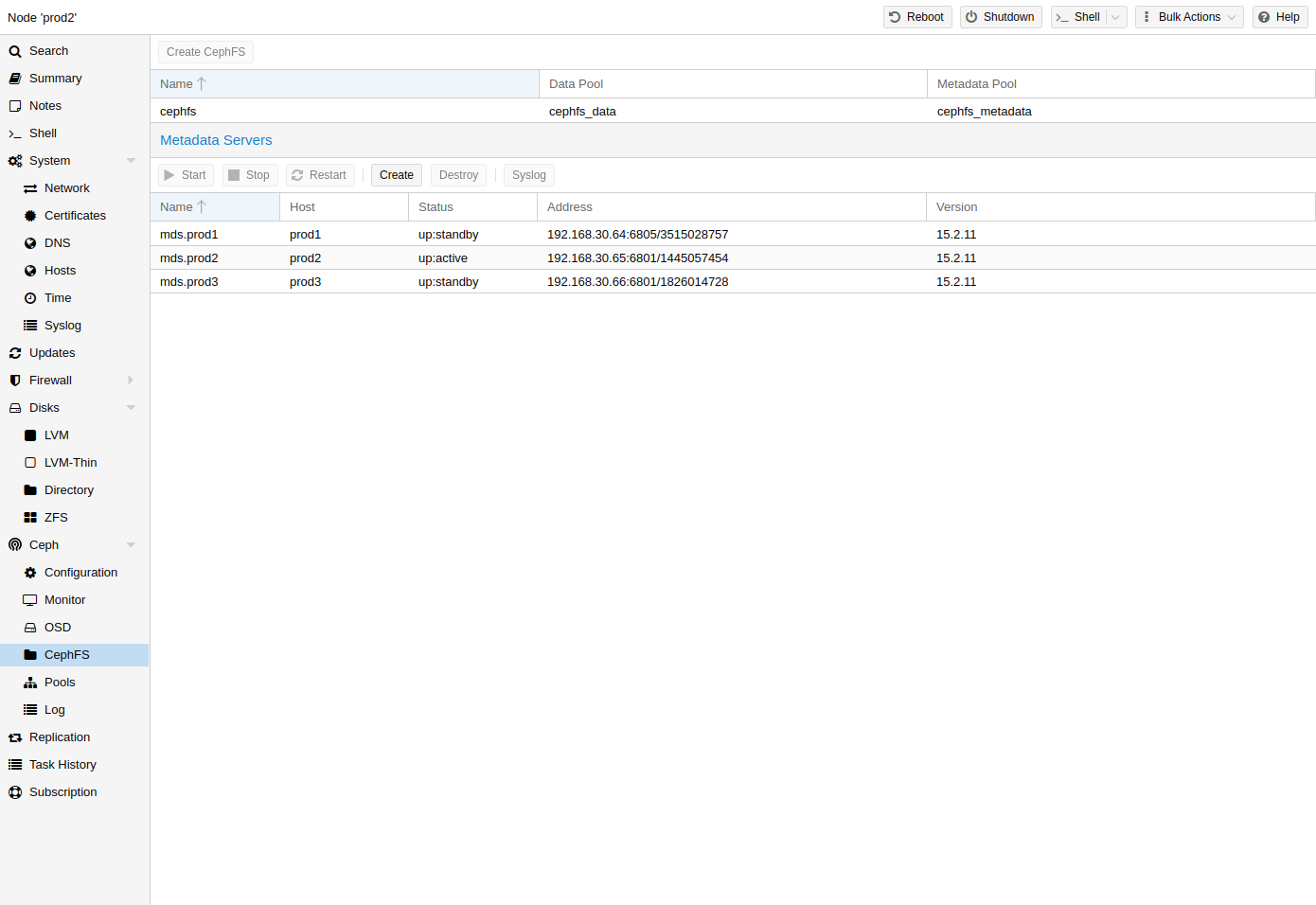
Proxmox VE supports both creating a hyper-converged CephFS and using an existing CephFS as storage to save backups, ISO files, and container templates.
Metadata Server (MDS)
Multiple Active MDS
Since Luminous (12.2.x) you can have multiple active metadata servers running at once, but this is normally only useful if you have a high amount of clients running in parallel. Otherwise the MDS is rarely the bottleneck in a system. If you want to set this up, please refer to the Ceph documentation.
[Configuring multiple active MDS daemons https://docs.ceph.com/en/nautilus/cephfs/multimds/]
Create CephFS
With Proxmox VE’s integration of CephFS, you can easily create a CephFS using the web interface, CLI or an external API interface. Some prerequisites are required for this to work:
This creates a CephFS named cephfs, using a pool for its data named cephfs_data with 128 placement groups and a pool for its metadata named cephfs_metadata with one quarter of the data pool’s placement groups ( 32 ). Check the Proxmox VE managed Ceph pool chapter or visit the Ceph documentation for more information regarding an appropriate placement group number ( pg_num ) for your setup
[placement_groups]
. Additionally, the —add-storage parameter will add the CephFS to the Proxmox VE storage configuration after it has been created successfully.
Destroy CephFS
| Destroying a CephFS will render all of its data unusable. This cannot be undone! |
To completely and gracefully remove a CephFS, the following steps are necessary:
Disconnect every non-Proxmox VE client (e.g. unmount the CephFS in guests).
Disable all related CephFS Proxmox VE storage entries (to prevent it from being automatically mounted).
Remove all used resources from guests (e.g. ISOs) that are on the CephFS you want to destroy.
Unmount the CephFS storages on all cluster nodes manually with
Where is the name of the CephFS storage in your Proxmox VE.
Now make sure that no metadata server ( MDS ) is running for that CephFS, either by stopping or destroying them. This can be done through the web interface or via the command line interface, for the latter you would issue the following command:
Note that standby servers will automatically be promoted to active when an active MDS is stopped or removed, so it is best to first stop all standby servers.
Now you can destroy the CephFS with
This will automatically destroy the underlying ceph pools as well as remove the storages from pve config.
After these steps, the CephFS should be completely removed and if you have other CephFS instances, the stopped metadata servers can be started again to act as standbys.
Ceph maintenance
Replace OSDs
One of the most common maintenance tasks in Ceph is to replace the disk of an OSD. If a disk is already in a failed state, then you can go ahead and run through the steps in Destroy OSDs. Ceph will recreate those copies on the remaining OSDs if possible. This rebalancing will start as soon as an OSD failure is detected or an OSD was actively stopped.
| With the default size/min_size (3/2) of a pool, recovery only starts when ‘size + 1` nodes are available. The reason for this is that the Ceph object balancer CRUSH defaults to a full node as `failure domain’. |
To replace a functioning disk from the GUI, go through the steps in Destroy OSDs. The only addition is to wait until the cluster shows HEALTH_OK before stopping the OSD to destroy it.
On the command line, use the following commands:
You can check with the command below if the OSD can be safely removed.
Once the above check tells you that it is safe to remove the OSD, you can continue with the following commands:
Replace the old disk with the new one and use the same procedure as described in Create OSDs.
Trim/Discard
It is good practice to run fstrim (discard) regularly on VMs and containers. This releases data blocks that the filesystem isn’t using anymore. It reduces data usage and resource load. Most modern operating systems issue such discard commands to their disks regularly. You only need to ensure that the Virtual Machines enable the disk discard option.
Scrub & Deep Scrub
Ceph ensures data integrity by scrubbing placement groups. Ceph checks every object in a PG for its health. There are two forms of Scrubbing, daily cheap metadata checks and weekly deep data checks. The weekly deep scrub reads the objects and uses checksums to ensure data integrity. If a running scrub interferes with business (performance) needs, you can adjust the time when scrubs
[Ceph scrubbing https://docs.ceph.com/en/nautilus/rados/configuration/osd-config-ref/#scrubbing]
are executed.
Ceph Monitoring and Troubleshooting
It is important to continuously monitor the health of a Ceph deployment from the beginning, either by using the Ceph tools or by accessing the status through the Proxmox VE API.
The following Ceph commands can be used to see if the cluster is healthy (HEALTH_OK), if there are warnings (HEALTH_WARN), or even errors (HEALTH_ERR). If the cluster is in an unhealthy state, the status commands below will also give you an overview of the current events and actions to take.



