ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Полный курс по Сетевым Технологиям
В курсе тебя ждет концентрат ТОП 15 навыков, которые обязан знать ведущий инженер или senior Network Operation Engineer

Установление метки VLAN
Коммутатор, к которому подключен IP – телефон, по протоколу CDP устанавливает соединение, которое позволяет телефону отправлять VoIP пакеты в отдельном VLAN (голосовом, то есть только для телефонов). Это позволяет изолировать трафик IP – телефонов от трафика сети Интернет.
Установление параметров CoS
Благодаря протоколу CDP, коммутатор может установить тип устройства и определить метку CoS (Class of Service) для него. Значение по умолчанию это CoS нулевого уровня, а максимальное значение CoS уровня 5.
Подключение компьютера в Cisco IP – телефон
Полный курс по Сетевым Технологиям
В курсе тебя ждет концентрат ТОП 15 навыков, которые обязан знать ведущий инженер или senior Network Operation Engineer
Cdp протокол что это
Если вы считаете, что её стоило бы доработать как можно быстрее, пожалуйста, скажите об этом.
Cisco Discovery Protocol (CDP) — проприетарный протокол Cisco, который позволяет сетевым устройствам анонсировать в сеть информацию о себе и о своих возможностях, а также собирать эту информацию о соседних устройствах.
Содержание
[править] CDP в Cisco
[править] Просмотр информации о соседях
Информация о соседях:
[править] Изменение настроек CDP
Указание с какого интерфейса будет взят IP-адрес, который передается в CDP пакетах:
Изменение частоты отправки пакетов CDP (в секундах):
[править] CDP на коммутаторах ProCurve
Коммутаторы ProCurve поддерживают протоколы LLDP и CDP. Однако, LLDP-сообщения они могут и генерировать и принимать, а CDP — только принимать.
В коммутаторах ProCurve таблицы LLDP и CDP взаимно пополняют друг друга. То есть, командами просмотра соседей обнаруженных по LLDP, можно увидеть и CDP-соседей. И наоборот.
По умолчанию на коммутаторах ProCurve включен CDP. В этом состоянии коммутатор принимает сообщения CDP.
Если на коммутаторе выключить CDP, то коммутатор начинает передавать сообщения CDP далее. Это может привести к тому, что топология будет отображать некорректно.
Например, если между двумя коммутаторами Cisco будет находиться коммутатор ProCurve с выключенным CDP, то коммутаторы Cisco «увидят» друг друга напрямую, как-будто ProCurve нет.
Настройки CDP на коммутаторе (по умолчанию CDP включен):
Информация о соседях CDP:
Более подробная информация о соседях CDP:
Коммутаторы ProCurve не принимают сообщения CDP версии 2. Если на коммутаторе Cisco включена версия 2, то он не будет отображаться в списке CDP-соседей на коммутаторе ProCurve.
Урок 23. Описание и настройка протокола CDP (Cisco Discovery Protocol)
Краткая теория и описание протокола
С помощью данного протокола можно получить следующую информацию о соседнем устройстве:
По умолчанию каждое устройство отправляет анонсы с информацией о себе каждые 60 с. Данные анонсы не пересылаются дальше по сети, то есть они не маршрутизируются и не коммутируются. Информация с принятых анонсов сохраняется в таблице CDP. По умолчанию запись в таблице сохраняется в течении 180 с, пока не поступит новое обновление от соседнего устройства. Значения всех таймеров можно настроить по своему усмотрению либо можно полностью отключить протокол CDP на определенном интерфейсе либо на всем устройстве.
Протокол может быть полезен для поиска неисправностей на канальном уровне. Существует открытый подобный протокол LLDP (Link Layer Discovery Protocol), который описывается стандартом IEEE 802.1AB-2009.
Настройка и просмотр информации о сети
По умолчанию CDP включен. Для просмотра информации, собранной протоколом воспользуйся следующими командами:
Switch# show cdp neighbours [details]
Switch# show cdp entry *

Для просмотра значений таймеров:

Для изменений значений таймеров:
Switch(config)# cdp timer значение
Switch(config)# cdp holdtime значение
Настройка протокола обнаружения Cisco на маршрутизаторах Cisco и на коммутаторах с Cisco IOS
Параметры загрузки
Об этом переводе
Этот документ был переведен Cisco с помощью машинного перевода, при ограниченном участии переводчика, чтобы сделать материалы и ресурсы поддержки доступными пользователям на их родном языке. Обратите внимание: даже лучший машинный перевод не может быть настолько точным и правильным, как перевод, выполненный профессиональным переводчиком. Компания Cisco Systems, Inc. не несет ответственности за точность этих переводов и рекомендует обращаться к английской версии документа (ссылка предоставлена) для уточнения.
Содержание
Введение
В этом документе поясняется порядок настройки протокола обнаружения Cisco (CDP) на маршрутизаторах Cisco и коммутаторах с программным обеспечением Cisco IOS®. В частности описаны процедуры включения, проверки и отключения CDP на устройствах Cisco и некоторые известные проблемы, связанные с CDP.
CDP является собственным протоколом Cisco уровня 2, который независим от сред и протоколов и используется на всем оборудовании производства Cisco, включая:
Устройство Cisco, на котором настроен протокол CDP, периодически отправляет на групповой адрес новую информацию о своем интерфейсе, чтобы сообщить о себе соседним узлам. Поскольку это протокол уровня 2, эти пакеты (кадры) не маршрутизируются. Использование протокола SNMP вместе с базой MIB протокола CDP позволяет приложениям для управления сетью распознавать тип устройства и адрес агента SNMP соседних устройств, а также отправлять запросы SNMP этим устройствам. CDP использует CISCO-CDP-MIB.
Предварительные условия
Требования
Для этого документа отсутствуют особые требования.
Используемые компоненты
Настоящий документ не имеет жесткой привязки к каким-либо конкретным версиям программного обеспечения и оборудования. Этот документ применяется ко всем маршрутизаторам и коммутаторам Cisco, использующим программное обеспечение Cisco IOS, а также модулям маршрутизации, например WS-X4232-L3, RSM, и MSFC.
Сведения, представленные в этом документе, были получены от устройств, работающих в специальной лабораторной среде. Все устройства, описанные в этом документе, были запущены с чистой (стандартной) конфигурацией. В рабочей сети необходимо изучить потенциальное воздействие всех команд до их использования.
Условные обозначения
Настройка протокола Cisco Discovery Protocol
Разблокирование/блокирование тракта данных кэш памяти в устройстве Cisco IOS
CDP доступен на маршрутизаторах Cisco по умолчанию. Если функция CDP не требуется, отключите ее командой no cdp run. Для того чтобы снова включить протокол CDP, используйте команду cdp run в режиме глобальной настройки.
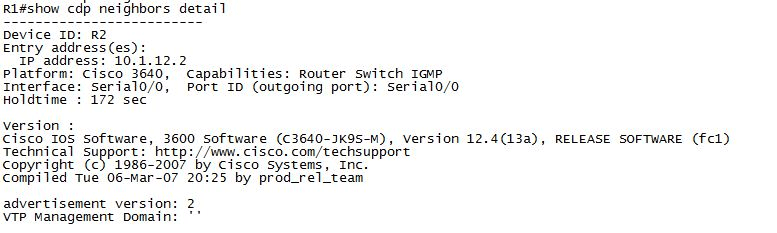
При помощи команды show cdp neighbors можно проверить, включен или выключен CDP в устройстве Cisco.
Эти выходные данные команды указывают, что протокол CDP работает на данном устройстве, но ни одно соседнее устройство не обнаружено и не подключено к этому устройству.
Эти выходные данные команды указывают, что протокол CDP работает на этом устройстве и что он обнаружил некоторые соседние устройства.
Команда show cdp neighbors выводит следующую информацию:
тип обнаруживаемого устройства
номер и тип локального интерфейса (порта)
кол-во секунд, в течение которых объявление CDP действительно для данного порта
Команды show cdp neighbors detail и show cdp entry выводят дополнительную информацию о соседних устройства, в том числе версию протокола сетевого уровня и информацию о нем.
Включение/отключение CDP на интерфейсе
Когда протокол CDP включается глобально с помощью команды cdp run, он по умолчанию активируется на всех поддерживаемых интерфейсах (за исключением дочерних многоточечных интерфейсов Frame Relay) для отправки и приема информации о CDP. С помощью команды no cdp enable протокол CDP можно отключить на совместимом интерфейсе.
На этом маршрутизаторе протокол CDP включен на интерфейсах Serial 1 и Ethernet 0. Отключите протокол CDP на интерфейсе Serial 1 и проверьте, будет ли обнаружено соседнее устройство на этом последовательном интерфейсе. Используйте приведенные далее выходные данные:
Маршрутизатор не удаляет запись для соседнего узла на отключенном интерфейсе CDP до истечения времени удержания. В выходных данных указано, что маршрутизатор обнаружил соседнее устройство только на интерфейсе Ethernet 0.
Используйте команду show running-config, чтобы определить, включен или отключен протокол CDP на определенном интерфейсе вашего устройства.
Примечание. Протокол CDP можно включать и выключать на интерфейсе, только если он включен глобально с помощью команды cdp run.
Известные проблемы на CDP
CDP может израсходовать всю память маршрутизатора
Когда отправляется большое количество объявлений протокола CDP для соседних устройств, вся память доступного устройства может быть занята. Это приводит к сбою или другому нештатному поведению. Дополнительные сведения см. в разделе Ответ Cisco на проблемы протокола CDP:
Veeam CDP для самых маленьких
Вот об этом мы сегодня и поговорим: что это за магия такая, как она работает и как мы её реализовали в Veeam Backup & Replication v11.

Зачем CDP нужен этому миру
Начинаем по порядку: а какие проблемы может решить CDP и кому он нужен?
CDP удобнее всего сравнивать с асинхронной репликацией стораджей. То есть ваши виртуалочки спокойно работают, а где-то там далеко внизу одно хранилище реплицирует данные на другое, как бы гарантируя вам, что в случае сбоя вы потеряете минимум информации и просто продолжите работать в новом месте.
Так что если снапшоты можно исключить, их надо исключить.
Как работает CDP
Хотелось бы так, но нет. На практике всё несколько сложнее. Давайте разбираться.

Вот так выглядит общая схема работы. Для видавшего виды VBR пользователя здесь знакомо только слово Proxy. И, пожалуй, да, на прокси вся схожесть с классическими схемами работы и заканчивается.
Координатор. Умывальников начальник и мочалок командир. Управляет всеми процессами, отвечает за связь с vCenter, говорит другим компонентам, что делать, и всячески следит, чтобы всё было хорошо. На местах выглядит как Windows сервис. Единственный, кто знает про существование таких вещей, как vCenter и виртуальные машины. Все остальные работают только с дисками. Поэтому всё, что не связано с репликацией контента, делает координатор. Например, создаёт виртуалку на таргете, к которой мы прицепим реплицируемые диски.
Source filter. Та самая штука, которая занимается перехватом IO запросов. Соответственно, работает уже на ESXi. Дабы повысить надёжность и производительность, один инстанс фильтра работает с одним виртуальным диском. Фильтры держат связь с демоном.
Зачем нужна прокладка в виде демона и почему бы фильтру самому не работать с прокси? Это ограничение технологии со стороны VMware, не позволяющее фильтру работать с внешней сетью. То есть фильтр с демоном связь установить может, а с прокси нет. Это называется by design, и ничего с этим не поделаешь. Во всяком случае, сейчас. И напомню: демон не знает ни про какие виртуальные машины. Он работает с потоками данных от дисков. И ничего другого в его мире не существует. Поэтому диски одной машины могут обрабатываться сразу несколькими прокси. Мы, конечно, стараемся отвозить диски одной машины через один прокси, но если она не справляется, то подключится другая. И это нормально!
Source Proxy. Агрегирует в себе всю информацию, полученную от фильтров через демонов. Хранит всё строго в RAM, с возможностью подключения дискового кэша, если оперативка кончилась. По этому очень (ОЧЕНЬ!) требователен к RAM, дисковому кешу и задержкам на сети. Так что только SSD и прочее адекватное железо.
Прокси занимается составлением так называемых микроснапшотов, которые отправляются дальше. Данные перед передачей обязательно дедуплицируются: если в каком-то секторе произошло 100500 перезаписей, то до прокси дойдут все, но с самого прокси будет отправлена только одна последняя. Так же, само собой, всё сжимается и шифруется. На местах прокси представляют собой Windows машины, которые могут взаимозаменять друг друга, переключать нагрузку и так далее.
Target Proxy. Всё то же самое, но в обратном порядке. Принимает трафик от сорсных проксей, расшифровывает, разжимает, отправляет дальше. Так же может быть как физический, так и виртуальный.
Target Daemon. Занимается записью данных на датастор. Полная копия сорсного демона.
Target Filter. В нормальном состоянии находится в выключенном виде. Начинает работать только во время фейловера и фейлбека, но об этом позже.
Таргетные компоненты от сорсных в данном случае отличаются только названием и своим местом в логической схеме. Технически они абсолютно идентичны и могут меняться ролями на ходу. И даже одновременно работать в двух режимах, чтобы одна машина реплицировалась с хоста, а другая на хост. Но я вам ничего такого не говорил и делать не советовал. Также в момент переключения реплики в фейлбек таргеты переключаются на роль сорсов, а в логах появится соответствующая запись.
Немного промежуточных деталей
Сейчас хочется немного отвлечься на разные детали, понимание которых даст нам более полную картину в будущем.
Как мы видим, процессы, связанные с CDP, довольно плотно интегрированы в сам хост. Так что при выполнении многих операций надо быть предельно внимательным. Например, апгрейд/удаление VAIO драйвера происходит строго через maintenance mode. Установка, что хорошо, такого не требует. На случай отсутствия DRS предусмотрена защита, которая не даст запуститься процессу, однако это же IT, и бывает тут всякое. Поэтому действовать надо осторожно и внимательно.
И ловите бонус: фильтр с хоста можно удалить командой:
И дальше по обстановке.
И, конечно же, не забудем обрадовать ненавистников разного рода устанавливаемых на гостевую ОС агентов и сервисов. Для CDP ничего такого делать не надо, и даже админские креды никому больше не нужны (если только вы готовы отказаться от VSS точек с application consistent состоянием). Наконец-то угнетатели повержены и можно спать спокойно. Всё работает исключительно за счёт магии VAIO API.
Retention
На длинной дистанции мы используем Long-term retention, гарантирующий консистентность на уровне приложений(application aware). Делается это с помощью VSS и требует предоставления админской учётки от гостевой ОС. Выглядит это как создание точек отката с определённой периодичностью (например, раз в 12 часов), которые хранятся несколько дней.
Расписание, само собой, гибко настраивается, позволяя, например, обеспечивать crash-consistent только в офисное время, а в ночное переключаться на редкие, но application-consistent точки.
Если подходить глобально, то вариантов сделать фейловер у нас два: прямо сейчас по кнопке Failover now… или создав Failover Plan. Соответственно, если случилась авария, то мы можем сделать фейловер нашей реплики в следующих режимах:
Откат на последнее состояние (crash-consistent)
Восстановиться на нужный нам момент времени в режиме Point-in-time (crash-consistent)
Откатиться на Long term точку (здесь можно выбрать между application-aware и crash-consistent)
А failback и permanent failover делаются по правилам обычных старомодных реплик, так что останавливаться на этом не буду. Всё есть в документации.
Совет: в выборе нужного момента времени при Point-in-time ресторе очень удобно двигать ползунок стрелочками на клавиатуре 😉
Как работает CDP ретеншн
И прежде чем мы начнём обсуждать, почему вы поставили хранить три точки отката, а на диске их двадцать восемь, давайте посмотрим, что вообще будет храниться на таргетной датасторе.
.VMDK Тут без сюрпризов. Обычный диск вашей машины, который создаётся в момент первого запуска репликации.
Short-term retention
Теперь рассмотрим, как это работает.
В первый момент времени на таргете нет ничего, поэтому, чтобы начать работать, нам надо взять и в лоб поблочно скопировать VMDK файл с сорса на таргет.
Совет: если тащить по сети огромный VMDK вам нет никакого удовольствия, то Seeding и Mapping вам в помощь. Они позволяют перевести ваши файлы на таргетный хост хоть на флешке в кармане, в дальнейшем подключив их к заданию.
Возникает закономерный вопрос: каков размер этих самых блоков? Он динамический и зависит от размера диска. Для простоты можно считать, что 1 Тб диска соответствует 1 Мб блока.
Как только VMDK перевезён, можно начинать создавать дельта диски. Для чего фильтр и демон начинают отслеживать IO машины, отправляя по сети всё, что пишется на машине.
Этот поток сознания, приходя на сорс прокси, проходит через процедуру отбрасывания лишних блоков. То есть если некий блок за период репликации был перезаписан несколько раз, то в дельту уйдёт исключительно последнее его состояние, а не вообще все. Это позволяет сохранять вагон ресурсов и два вагона пропускной способности вашей сети.
Рядом с дельта диском создаётся транзакцонный лог.
Если лог становится слишком большим, то создаётся новый дельта диск.
И так всё работает до достижения выбранного Retention policy. После чего Veeam смотрит на содержимое лога.
Если это просто устаревшая точка восстановления, которая нам больше не нужна, то данные из неё вносятся в наш базовый диск, и файлы удаляются.
Если оказывается, что в логе нет вообще ничего, необходимого для создания новых точек восстановления, такой файл сразу удаляется.
Примечание: Соблюдение Retention Policy довольно важно. Однако поддержка CDP реплики в боевом состоянии ещё важнее. Поэтому в механизм заложена потенциальная возможность временного расширения периода хранения до 125% от первоначального.
Long-term retention

Служит логическим продолжением short-term retention. То есть всё работает ровно так, как и написано выше, пока не наступает момент создать long-term точку.
В этот момент создаётся особый дельта диск. Внешне он не отличается от других, однако во внутренней логике он помечается как long-term delta.
Репликация продолжает идти своим чередом.
Когда подходит время для срабатывания short term, то все предыдущие логи и дельта диски (если их несколько) просто удаляются.
Теперь всё считается от этой long-term точки. Она остаётся нетронутой и высится как глыба.
Затем создаётся новая long-term точка, и цикл замыкается.
Когда подходит время, то самая первая long-term точка инжектируется в базовый VMDK.
Про логику транзакций
Путь данных с оригинальной машины до реплицированной можно разбить на два логических участка, водораздел которых проходит по source proxy.
Отсюда два важных следствия:
Если мы не успеваем передать данные на участке фильтр-демон-прокси, они считаются безвозвратно потерянными, и сделать с этим уже ничего нельзя.
На втором участке задержка уже не критична. Если даже в какой-то момент времени мы не успеваем получить подтверждение от таргетного демона, то данные остаются в кеше сорсного и таргетного прокси и будут переданы ещё раз. Если кажется, что такое кеширование избыточно, то это кажется. Сети сейчас, конечно, быстрые, но зачем лишний раз лезть далеко, если можно попросить данные ближе? В логе джобы в этот момент возникнет предупреждение, что RPO нарушено, но ничего критичного ещё не случилось. Позднее данные будут довезены до таргета.
Что под капотом у фильтров
Теперь, когда мы разобрались на базовом уровне в устройстве и принципах работы CDP, давайте посмотрим более внимательно на работу отдельных компонентов. А именно фильтров. Ведь именно от их красивой работы зависит всё остальное. И как мы все прекрасно понимаем, ровно и красиво может быть только в лабораторных условиях. Именно там у нас всегда стабильный поток IO операций, нет резких всплесков нагрузки, сетевые пакеты никуда не пропадают, и все графики выглядят как прямая рельса, уходящая за горизонт.
Вот так вот можно изобразить на любимых всеми квадратиках с буквами режимы работы. В данном примере у нас установлено RPO 10 секунд, из которых пять секунд (половина RPO) мы отслеживаем изменения данных, а вторую половину времени пытаемся передать последнее их состояние. То есть, промежуточные, как я говорил выше, нас не интересуют.
А вот что случается, когда мы не получаем подтверждение доставки от таргета. Данные мы собрали, однако передать их не можем. В этот момент Veeam начинает сохранять в сторонку номера таких блоков. И только номера, никаких данных. Почему? Потому что когда связь восстановится, нам надо передать актуальное состояние блоков.
Примечание: Чтобы администратор спал спокойней, предусмотрены два оповещения, скрывающихся под кнопкой RPO Reporting. Фактически они просто считают, сколько данных за указанный промежуток времени мы можем потерять. И бьют в набат, если что-то пошло не так.
Инфраструктура
Обычно, когда заходит речь о проработке какой-либо инфраструктуры, все сразу начинают думать про CPU и RAM. Но только не в этот раз! Здесь надо начинать с поиска вашего сетевика, чтобы он сделал вам сеть с наикратчайшим маршрутом, с 10 Gbit+ линками, и не забыл включить MTU 9000 (Release Jumbo frames. ) на всём протяжении маршрута. Согласно нашим тестам, такой набор нехитрых действий позволяет добиться прироста производительности почти на 25%. Неплохо, да?
И общий совет на все случаи жизни: десять маленьких CDP политик всегда будут работать лучше и стабильней, чем одна большая. Что такое маленькая политика? Это до 50 машин или 200 дисков. В мире большого энтерпрайза это считается за немного. Технически, опять же, здесь ограничений нет, и проводились успешные тесты аж до 1500 машин и 5000 дисков. Так что лучше, опять же, протестировать на месте и найти оптимальный для себя вариант.
Немного о прокси
И хотя кажется, что прокси серверам в схеме CDP отведена роль тупых молотильщиков трафика, без их успешного взаимодействия всё остальное теряет смысл. И задачи там решаются достаточно серьёзные, так что не будем принижать их вклад в общее дело.
Что хочется сказать про этих ребят:
Не надо заставлять один и тот же прокси сервер выступать в роли сорсного и таргетного. Ничего хорошего из этого не выйдет. Запретить вам так сделать мы не можем, однако будем долго отговаривать.
Да и вообще, общая логика такова, что чем больше вы сможете развернуть прокси серверов, тем лучше будет результат. Особенно если речь идёт о репликации между удалёнными дата центрами.
Также самые внимательные заметят, что на шаге назначения проксей есть кнопка Test с таинственным набором цифр внутри.
Давайте разбираться что же это такое и откуда оно взялось. Все эти скорости и количества являются ничем иным, как усреднёнными максимумами за последний час, полученными от vCenter. То есть это не мы что-то там померили в моменте, ловко запустив какие-то таинственные тесты, а такова родная статистика хостов за последний час.
Давайте теперь пройдёмся по строчкам.
Source Proxy CPU: количество ядер CPU на всех доступных проксях, которые могут работать в качестве сорса. Видим vCPU, но читаем как ядра CPU.
Source Proxy RAM. Здесь уже посложней будет. Цифра перед скобками показывает, сколько оперативки нам может понадобиться для данной CDP политики.
Формула расчёта довольно простая: RPO* пропускную способность.
Пропускную способность кого/чего? Да всех дисков всех вируталок, участвующих в этой политике. Напоминаю, что берётся максимальное значение за последний час.
Source Proxy Bandwidth. Здесь опять всё просто. Число перед скобками мы получаем от vCenter, а число в скобках считается на основе доступного количества ядер с округлением до целого. Если мы шифруем трафик, то это 150 Мб/с на ядро. Если не шифруем, то 200 Мб/с на ядро.
Target Proxy CPU. Всё ровно так же, как у сорса: взяли и посчитали все доступные ядра на доступных проксях.
Target Proxy RAM. Хочется, как и в предыдущем пункте, сказать, что всё такое же, но нет. Здесь в формулу для расчёта внесён поправочный коэффициент 0.5. А значит, что если мы за те же 15 секунд хотим обработать 150 Мб/c от дисков, то понадобится нам уже только 1125 RAM (вместо 2250, как это было с сорсом).
И помним важное: таргет и прокси меняются ролями в момент фейловера. То есть вся схема начинает работать в обратную сторону. Поэтому на таргете и есть неактивный фильтр, который оживает в момент фейловера. А фильтр на бывшем сорсе, соответственно, выключается.
Быстрое Ч.А.В.О. в конце
Как добавить в CDP Policy выключенную машину?
Никак. Виртуалка выключена > фильтр не работает > передавать нечего.
Какие версии vSphere поддерживаются?
Хочу минимальное RPO, чтобы ну вообще ничего не потерялось.
Если у вас железо хорошее (прям хорошее-хорошее, а не вам кажется, что хорошее), то вполне реально добиться RPO в 2 секунды. А так, в среднем по больнице, вполне реально обеспечивать 10-15 секунд.
А что с vRDM?
Всё отлично поддерживается.
А можно CDP прокси назначить и другие роли?
Назначайте, мы не против. Только следите за соответствием доступных ресурсов предполагаемым нагрузкам.
А можно CDP реплику, как и обычную, использовать для создания бекапов?
Нет. Во всяком случае сейчас.
Я могу запустить CDP реплику из консоли vCenter?
Нет. С точки зрения vCenter там какой-то фарш из дельта дисков, поэтому он выдаст ошибку зависимостей.
А если я руками удалю CDP реплику из Inventory в vCenter?
Умрут все id и всё сломается. А вы чего ожидали?
А если таргетная стора будет чем-то очень загружена?
Veeam будет присылать на почту уведомления, что очень старается, но у вас ботлнек на принимающей стороне и нельзя впихнуть невпихуемое.
А что с Hyper-V?
Это вопрос к Microsoft.
Немного полезных ESXi команд
Убить daemon сервис:
Остановить/запустить daemon сервис:
Полюбопытствовать насчет последних логов демона:
Выяснить, сколько памяти потребили все демоны:
Проверить установку пакета фильтра. Он выглядит как обычный vib



