Soft — Consulting
Построение запросов (ORACLE)
Оглавление:
Структуры данных для примеров.
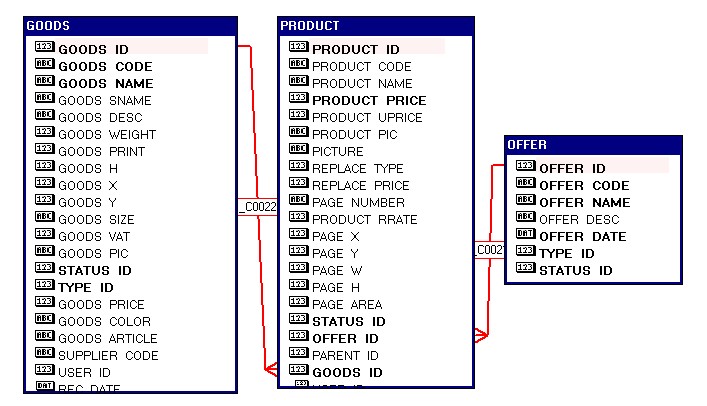
Рекомендации по оптимизации запросов
Данные рекомендации взяты мной из руководства Oracle по настройке базы данных, со временем они практически не меняются, посмотреть их можно здесь, это глава 11.5. Ссылка может не работать, все зависит от того, как долго Oracle решит хранить этот фрагмент документации в интернете.
Не используйте SQL-функции в предикатах. Любое выражение в котором используется колонка (expression), например функция, использующая колонку, как аргумент, приведет к тому, что индекс для данной колонки (если он есть) использоваться не будет, даже если это уникальный индекс. Хотя, если для колонки имеется составной индекс (function-based) на основе применяемой в предикате функции, то он может быть использован.
где numexpr выражение числового типа, то Oracle преобразует ваше условие в:
и индекс использован не будет.
Где по числовой колонке numcol построен индекс.
План запроса.
Практически любую задачу по получению каких-либо результатов из базы данных можно решить несколькими способами, т.е. написать несколько разных запросов, которые дадут один и тот же результат. Это, однако не означает, что база данных эти запросы будет выполнять по-разному. Также неверно мнение о том, что структура запроса может повлиять на то, как Oracle будет его выполнять, это касается порядка временных таблиц, JOINS и условий отбора в WHERE. Решение о том, как построить запрос принимает оптимизатор Oracle. Алгоритм получения сервером данных для конкретного запроса называют планом запроса.
Практически все продукты для работы с базой данных Oracle позволяют просмотреть план конкретного запроса. Так как слушатели этих лекций используют PL/SQL Developer, то для получения плана запроса в нем необходимо сделать следующее:
Существует стандартный механизм получения плана запроса. Для этого используется конструкция (команда) EXPLAIN PLAN FOR:
План запроса будет выведен в виде таблицы с одним полем, выглядит он так:
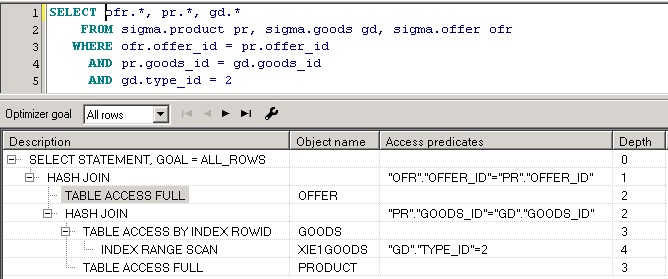
План всегда имеет иерархическую структуру. Операция соединения результирующих наборов оперирует парами дочерних операций. Операция получения данных может использовать вспомогательную операцию, такую, например, как сканирование индекса.
Данные результирующих наборов получаются в порядке следования этих наборов в плане запроса. Операция получения данных результирующего набора может состоять из нескольких шагов, которые характеризуются глубиной операции (колонка Depth).
При анализе плана в первую очередь необходимо обращать внимание на способы, с помощью которых получены данные результирующих наборов.
Некоторые термины в плане запроса.
План запроса имеет форму таблицы, один из столбцов которой описывает тип производимых сервером операций. Вот некоторые из них, которые встречаются наиболее часто:
Анализ плана запроса.
При анализе плана запроса вам необходимо примерно представлять объемы записей в таблицах и наличие у них индексов, которые могут пригодиться при фильтрации записей. Для доступа к данным Oracle использует несколько стратегий, какие из них выбраны для каждой из таблиц можно понять из плана запроса. При просмотре плана, вам необходимо решить, правильная ли выбрана стратегия в том или ином случае. Ниже приведены краткие описания способов доступа и механизмов отбора записей при соединениях результирующих наборов.
Full Table Scan (Table Access Full).
Может показаться, что доступ к данным таблицы быстрее осуществлять через индекс, но это не так. Иногда дешевле прочитать всю таблицу целиком, чем прочитать, например, 80% записей таблицы через индекс, так как чтение индекса тоже требует ресурсов. Очень не желательна ситуация, когда эта операция стоит первой в объединении наборов записей и таблица, которая читается полностью, большая. Еще хуже ситуация с большой таблицей на второй позиции в объединении, это означает, что она также будет прочитана полностью, как минимум, один раз, а если объединение производится через NESTED LOOPS, то таблица будет читаться несколько раз, поэтому запрос будет работать очень долго.
Nested Loops.
Такое соединение может использоваться оптимизатором, когда небольшой основной набор записей (стоит первым в плане запроса) объединяется с помощью условия, позволяющего эффективно выбрать записи из второго набора. Важным условием успешного использования такого соединения является наличие связи между основным и второстепенным набором записей. Если такой связи нет, то для каждой записи в первом наборе, из второго набора будут извлекаться одни и те же записи, что может привести к значительному увеличению времени запроса. Если вы видите, что в плане запроса применен NESTED LOOPS, а соединяемые наборы не удовлетворяют этому условию, то налицо ошибка.
Hash Joins.
Используется при соединении больших наборов данных. Оптимизатор использует наименьший из наборов данных для построения в памяти хэш-таблицы по ключу соединения. Затем он сканирует большую таблицу, используя хэш-таблицу для нахождения записей, которые удовлетворяют условию объединения.
Оптимизатор использует HASH JOIN, если наборы данных соединяются с помощью операторов и ключевых слов эквивалентности (=, AND) и если присутствует одно из условий:
■ Необходимо соединить наборы данных большого объема.
■ Большая часть небольшого набора данных должна быть использована в соединении.
Sort Merge Join.
Данное соединение может быть применено для независимых наборов данных. Обычно Oracle выбирает такую стратегию, если наборы данных уже отсортированы ранее, и если дальнейшая сортировка результата соединения не требуется. Обычно это имеет место для наборов, которые соединяются с помощью операторов , >=. Для этого типа соединения нет понятия главного и вспомогательного набора данных, сначала оба набора сортируются по общему ключу, а затем сливаются в одно целое. Если какой-то из наборов уже отсортирован, то повторная сортировка для него не производится.
Cartesian Joins.
Это соединение используется, когда одна и более таблиц не имеют никаких условий соединения с какой-либо другой таблицей в запросе. В этом случае произойдет объединение каждой записи из одного набора данных с каждой записью в другом. Такое соединение может быть выбрано между двумя небольшими таблицами, а в дальнейшем этот набор данных будет соединен с другой большой таблицей. Наличие такого соединения может обозначать присутствие серьезных проблем в запросе, особенно, если соединяемые таблицы по MERGE JOIN CARTESIAN. В этом случае, возможно, упущены дополнительные условия соединения наборов данных.
Хинты.
Хинт — это ключевое слово, иногда с набором параметров, которое может повлиять на оптимизатор при составлении плана запроса. Другими словами, с помощью хинтов вы можете попытаться изменить способ с помощью которого будут получены или обработаны данные (хинты есть не только у операторов SELECT).
Если у вас есть желание более детально ознакомиться с хинтами, то я рекомендовал бы вам просмотреть эту статью.
Использование хинтов.
Хинт ставится после ключевого слова, которое определяет некую цельную конструкцию запроса, в данном разделе речь пойдет о хинтах в запросах к данным, т.е. тех, которые оформляются оператором SELECT и ключевых словах, используемых в сочетании с ним. Хинт указывается в закрытом комментарии после оператора:
В данном примере используется хинт RULE.
Этот хинт официально не поддерживается с версии Oracle 10G. При его успешном применении включается оптимизация по определенным правилам (RBO — Rule Based Optimization). Данный хинт может быть полезен, если у вас сложный запрос с неэффективным планом выполнения и использование других хинтов может занять время, которого мало. Если в запросе не пропущены какие-то JOINS или условия и вы считаете, что он написан верно, то есть достаточно большая вероятность, что RBO построит верный план.
В 11G этот хинт пока работает с некоторыми ограничениями, важны для практической работы следующие:
■ В запросе не должны использоваться другие хинты.
■ Не должен использоваться синтаксис ANSI (left join | full outer join …)
FIRST_ROWS.
Данный хинт дает указание оптимизатору выбрать такой план запроса при котором первые записи результатов будут получены максиально быстрым способом. Хорош при отладке запроса, чтобы убедиться, что выдается то, что необходимо. Если предполагается, что запрос вернет много записей, то при использовании такого хинта он может работать дольше.
ORDERED / LEADING.
При использовании этого хинта оптимизатор соединяет наборы данных в том порядке, в каком они следуют после оператора FROM. Вот пример разных последовательностей:
Порядок наборов данных необходимо выбирать аккуратно, чтобы соединяемые объекты имели какое-то условие связи в WHERE или после ключевого слова ON. Например в приведенном выше примере 4 версия списка во FROM приведет к перемножению таблиц GOODS и OFFER, так как они не связаны друг с другом условиями.
Данный хинт часто бывает полезен, если статистика по таблицам не собрана, план запроса не верный, и вам точно известно, как должны соединяться таблицы. При использовании данного хинта старайтесь выстроить порядок соединения так, чтобы тяжесть обработки данных следовала в сторону увеличения, т.е. сначала соедините наборы поменьше или с хорошими условиями отбора, чтобы результат их соединения был наименьшим по количеству записей, затем подключайте наборы данных большего размера.
Более удобен в использовании хинт LEADING. Он позволяет соединить наборы данных в порядке перечисления их (или их алиасов) в списке аргументов хинта:
MATERIALIZE.
Дает указание оптимизатору построить временную таблицу (материализовать результаты) для запроса, к которому этот хинт применяется, работает только в конструкции WITH. Очень полезен при обработке больших объемов данных, так как позволяет разбить запрос на части, в этом случае улучшается читабельность запроса, а также может быть получен правильный план. Пример использования:
План запроса выглядит так:
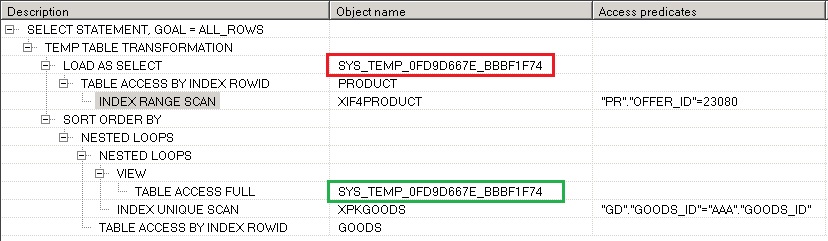
Красным цветом помечена таблица при ее создании, зеленым ее использование в соединении.
INDEX.
Дает указание оптимизатору использовать индекс при чтении данных из таблицы. Полезен тем, что может предотвратить чтение всего содержимого таблицы, если вы считаете, что этого делать не нужно. Пример использования:
Этот хинт сработает в том случае, если у таблицы есть указываемый индекс, и его можно использовать на основе одного или нескольких условий при получении данных таблицы. В приведенном примере в составе индекса есть поле OFFER_ID на второй позиции и он может быть использован, план запроса выглядит в этом случае так:

Комбинации хинтов.
Использование комбинации хинтов допустимо. Нужный эффект можно получить, если хинты в одном запросе не протеворечат друг другу. При записи хинты разделяются пробелами:
В данном примере используется хинт для установки порядка соединения наборов данных и способа доступа к таблице, противоречия в их использовании нет.
Oracle mechanics
Операции CBO
Описание некоторых методов доступа к данным (access path), соединения наборов данных (join method) и преобразований запросов (query transformation) используемых оптимизатором / в планах выполнения запросов Oracle
Методы доступа и соединения наборов данных
Index Full Scan
«… full index scan исключает сортировку, поскольку по одному блоку считывает упорядоченные по индексному ключу данные…»
Используется для эффективной замены табличного доступа при выполнении сортировок (ORDER BY), группировок (GROUP BY) и операции sort merge join (вместо традиционных full table scan с последующей сортировкой) при выполнении определённых условий
Index Fast Full Scan
INDEX SKIP SCAN
«Index Skip Scan использует разделение составного индекса на логические части (subindexes). Такое сканирование используется в случаях, когда первый столбец составного индекса не входит в условия запроса. Другими словами, первый столбец пропускается (skipped) [при выполнении этой операции] … [Oracle] определяет количество таких логических частей (subindexes) по числу неповторяющихся значений (distinct values) первого столбца составного индекса. Такое сканирование является предпочтительным в случаях, когда первый столбец составного индекса имеет малое количество неповторяющихся значений, а следующий стобец — большое … [CBO] может предпочесть операцию index skip scan если первый столбец составного индекса не входит в условия запроса (query predicate)…»
Практический пример использования оптимизатором index skip scan при наличии составного индекса IX_AA_AFLID_DATE_INS по столбцам AA(AFFILIATE_ID, DATE_INSERT)
FILTER
Фильтрация по условию набора строк (row set), полученного в рез-тате предыдущей операции доступа к данным. Отражается в секции predicate info:
, или отдельной операцией плана выполнения, например, в случаях:
filter(NULL IS NOT NULL)
специальный случай операции FILTER, используемый для исключения из универсального плана выполнения избыточных операций с данными при наличии невыполнимых условий
Например, если для ненулевого по определению поля EMP.EMPNO указать в в запросе невыполнимое условие empno is null:
При этом в трейсе оптимизатора финальное уточнение стоимости выглядит след.образом:
CONCATENATION
Операция выбора путей доступа к данным / объединения результатов.
В первом случае применяется в случаях, когда план выполнения запроса выбирается динамически, например, в зависимости от значения связанной переменной:
при этом, несмотря на то, что запрос будет выполняться либо с использованием полного сканирования всех блоков таблицы (TABLE ACCESS FULL), либо — по уникальному индексу (TABLE ACCESS BY INDEX ROWID), общая стоимость плана (и ожидаемое кол-во строк Rows/Bytes) просто складываются из альтернативных стоимостей вариантов доступа:
8 = 7+1
В секции Predicate Information можно видеть малодокументированную функцию SYS_OP_MAP_NONNULL, используемую внутри DECODE для успешного сравнения (с результатом TRUE) нулевых значений
функция эта встречается, например, также в описании старого бага Oracle В другом случае в результате применения OR-expansion transformation операция CONCATENATION используется в плане для обозначения объединения результатов вместо UNION ALL:
CARTESIAN JOIN
«… используется в случаях, когда одна или несколько таблиц не имеют никаких условий (join conditions) для соединения с другими таблицами запроса. Оптимизатор соединяет каждую строку первого источника данных с каждой строкой другого, создавая картезианское произведение (Cartesian product) двух наборов данных»
В последнем примере благодаря подсказке ORDERED оптимизатор вынужден первым делом соедиить таблицы DEPT и BONUS, не имеющие по условиям запроса никаких условий для соединения (join keys) и, следовательно, единственной возможной операцией для такого безусловного соединения оказывается картезианское произведение (Join Cartesian) В случае, когда две небольшие таблицы (DEPT и BONUS) соединяются через условия d.deptno = e.deptno and b.ename = e.ename к «большой» таблице EMP и имеются дополнительные условия на столбцы небольших таблиц (фильтры dept.loc = ‘CHICAGO’ and bonus.comm > 30), оптимизатор по соображениям улучшения избирательности (selectivity) и уменьшения стоимисти без всяких подсказок может выбрать Merge Join Cartesian небольших таблиц с последующим соединением (Hash join) с большой таблицей:
Начиная с Oracle 10g использование картезианского произведения на уровне системы, сессии, запроса может быть запрещено параметрами с разной степенью эффективности:
HASH JOIN
«… используется для соединения больших наборов данных (data sets). Оптимизатор использует меньшую из двух таблиц — источников данных для посторения хэш-таблицы ключа соединения (join key) в памяти. Затем сканирует бОльшую таблицу, сравнивая по ключу с хэш-таблицой для получения результирующего набора строк»
Управление использованием hash join с помощью oracle events на уровне сессии/системы:
или скрытым, начиная с 10g, параметром:
Right Join – The secret of swapping join input — про hash join swapping и испольхование хинта SWAP_JOIN_INPUTS
HASH UNIQUE / SORT UNIQUE
From10Gr2, HASH UNIQUE Operation Returns Results in UNSORTED ORDER by Default [ID 341838.1]: «Начиная с 10gR2 при выполнении SELECT DISTINCT при настройках по умолчанию [оптимизатор] отдаёт предпочтение операция HASH UNIQUE вместо SORT UNIQUE, в результате которой [в отличие от операции SORT UNIQUE] данные возвращаются в неотсортированном виде»
или же для исключения использования операции HASH UNIQUE и возвращения к «старому поведению» (использованию SORT UNIQUE) можно установить параметр optimizer_features_enableв значение 9.2.0 и ниже:
Sort join: Оба источника входных данных / таблицы сортируются по ключу соединения (join key)
Merge join: Совместная обработка / объдинение (merging) отсортированных списков
В случае, если источник данных уже отсортирован по столбцу[ам] условия соединения (join column), операция sort join не производится для этого источника данных» Например, при использовании оператора сравнения «>» несвязанных столцов видим по одной операции SORT JOIN для каждой таблицы и объединённую операцию MERGE JOIN:
В случае с отсортироваными значениями одна из операций SORT JOIN исключается за ненадобностью:
SORT UNIQUE NOSORT
операция последовательной сортировки результатов одноблочного чтения для получения набора неповторяющихся значений, применяемая при выполнении SELECT DISTINCT
LOAD AS SELECT
отражает операции параллельной или непараллельной прямой загрузки данных (direct-path DML|DDL) при операциях: CREATE TABLE AS SELECT, INSERT …SELECT,…
Julian Dyke отмечает, что в ранних версиях операция наблюдалась только при выполнении EXPLAIN PLAN, и не наблюдается при реальном выполнении (AUTOTRACE или V$SQL_PLAN), начиная с Oracle 10.2 операцию можно наблюдать в выполняемых планах оптимизатора
INDEX MAINTENANCE
«… производится перестроение индекса по окончании операций direct-path INSERT [в т.ч. в составе parallel MERGE]… Перестроение индекса выполняется PX процессами при parallel direct-path INSERT, либо клиентским процессом при непараллельном / serial direct-path INSERT. Для уменьшения влияния этой операции на производительность DML можно сделать индекс(ы) unusable перед загрузкой данных в таблицу (INSERT) с последующим перестроением индекс(ов)»
PX COORDINATOR FORCED SERIAL
Появление этой операции означает, что план или его часть, первоначально рассчитанные для параллельного выполнения, переключёны в последовательный режим (serial execution) по причине использования в запросе функций, не допускающих параллельного выполнения или других видов зависимостей от «непараллельных» функций (например, пользовательских типов в таблицах) — см. тестскейс http://oracle-randolf.blogspot.com/2011/03/px-coordinator-forced-serial-operation.html
Трейс оптимизатора при этом рапортует:
В случаях, когда Oracle не в состоянии самостоятельно определить безопасность PL/SQL кода для параллельного выполнения, рекомендуются следующие способы пометить функции, как пригодные для параллельного выполнения: How To Enable Parallel Query For A Function? [ID 1093773.1]:
1) предпочтительный метод — использовать PARALLEL_ENABLE в определении функции:
2) допустимый / устаревающий метод, пригодный только для определения функции в составе пакета:
TEMP TABLE TRANSFORMATION
Преобразование промежуточного набора данных во временную таблицу во время выполнения запроса, может использоваться:
В случаях subquery factoring (WITH clause) временная таблица формируется при использовании подсказки /*+ MATERIALIZE*/ или без подсказки при выполнении определённых условий (например, количество использований таблицы-подзапроса в запросе):
Временная таблица SYS_TEMP_% строится на следующих шагах плана:
И затем, на шагах 6 и 8 сканируется только подготовленная временная таблица SYS_TEMP_% (исключая таким образом избыточный доступ к исходной таблице T)
MAT_VIEW CUBE ACCESS
Операция доступа к агрегированным данным MOLAP куба (Oracle OLAP Option), созданного с возможностями материализованного представления — cube materialized view.
Используется при выполнении query rewrite, доступа с версии 11.1
На примере тестовой схемы OLAPTRAIN без query rewrite запрос выполняется дорого с полным доступом к таблицам:
При использовании query rewrite данные получаются напрямую из куба CB$SALES_CUBE, значительно уменьшая стоимость и воемя выполнения:
Те же данные можно получить прямым запросом к кубу, например через mview с вышеуказанными в Predicate Information условиями:
PARTITION LIST EMPTY
Операция не предполагает выполнения последующих / дочерних операций ни с одной из партиций
Наблюдалась в 11.2.0.3 при ошибочном применении преобразования Table Expansion в виде:
доступ к партициям при этой операции определялся следующими противоречивыми предикатами по ключу партицирования:
Методы преобразования запросов (query transformation)
Join Elimination (JE)
При наличии ограничений целостности на столбцах, по которым выполняется соединение таблиц в запросе [например, PK->FK], трансформация типа join elimination может исключать из запроса таблицу в случае, когда сам факт соединения таблиц не влияет на результат запроса [т.е. правильное выполнение запроса не требует обращения к исключаемой таблице]
First K Rows Optimization
Применяется в процессе построения плана запроса, использующего функцию ROWNUM в условиях (rownum predicate)
Query Slow With Rownum Predicate [ID 833286.1] — на уровне сессии/системы управляется параметром:
— на уровне запроса с использованием подсказки OPT_PARAM параметр (в 11.2.0.3) не меняется
Star Transformation (ST)
преобразование запроса с целью исключения обработки большого количества строк таблиц с фактическими данными (fact table) за счёт комбинированного индексного доступа по подготовленному набору внешних ключей, полученных из сканирования/фильтрации небольших справочных таблиц (dimension table)
Для выполнения этой трансформации поля таблицы фактов, по которым выполняется соединение должны быть проиндексированы — по этим индексаи будет выполняться доступ к большой таблице (fact) с использованием ключей, полученных в результате bitmap операций (BITMAP AND, BITMAP MERGE, BITMAP KEY ITERATION, …) над битовыми картами ключей, полученными из bitmap-индексов или регулярных B-tree индексов справочных таблиц (dimension)
Set to Join Conversion (SJC)
Filter Push-Down (FPD)
преобразование, позволяющее не только «опускать» условия внешнего запроса в используемые Inline View (аналогично Complex View Merging), но и логически генерировать дополнительные предикаты, которые могут быть использованы, например, для Partition Pruning:
Методы преобразования запросов на основе стоимости (Cost-Based QueryTtransformation | CBQT)
Complex View Merging
Group by Placement
— обратное по отношению к Complex View Merging преобразование
Distinct Aggregate Transformation
Table Expansion
Преобразование, позволяющее при выполнении запросов к партиционированным таблицам использовать отличные пути доступа в зависимости от состояния (USABLE/UNUSABLE) партиций локальных индексов
Отображается в плане в виде VIEW VW_TE_2, цифра отражает номер итерации:
Понравилось это:
2 комментария »
Хороший FAQ, почерпнул много нового.
комментарий от blacksaifer — 28.08.2012 @ 08:06 | Ответить
Спасибо за статью. Все по методоам доступа в одном месте. За вторую книжку в списке литературы — отдельный респект!



