Получаем управление обратно в Jenkins Pipeline
Jenkins Pipeline Plugin очень удобная штука, чтобы организовать у себя непрерывную доставку ПО (Continuous Delivery). Плагин даёт возможность разбить доставку ПО до конечного потребителя на стадии (stage), каждой из которых можно управлять (на каком узле, что и как нужно сделать) и, в конечном счёте, визуализировать процесс доставки. Вкупе с Blueocean plugin всё это выглядит очень вкусно. В реальной же жизни подчас оказывается так, что кроме Jenkins-а есть ещё и другие системы, которые участвуют в этом процессе (workflow), и встаёт вопрос — как их интегрировать с имеющимися решениями. Примером тут может служить Jira, в которой есть некий issue падающий на тестировщика, прокликивающего интерфейс (ну или совершающего другую полезную работу), и только после его благословения, наш артефакт имеет право двигаться дальше в сторону ожидающего его клиента.
Так какие у нас есть варианты реализации?
Очевидно, что их не меньше двух:
Первый вариант как минимум неудобен тем, что нужно писать цикл, который будет что-то проверять, не забыть о его прерывании после некоторого количества времени, и, вообще, поллинг не самый крутой метод, как мне кажется. Поэтому будем смотреть сразу в сторону веб-хука.
Пошерстив документацию, фичи с названием веб-хук я не нашел, и это, на самом деле, не очень хорошо, потому что то, что есть — скорее некий workaround нежели целевое решение.
Ставить опыты будем на очень простой конфигурации сферического коня в сферическом вакууме (буквально берём пример из example-ов):
Для описания шагов последовательности действий, в плагине используется groovy-dsl. В приведённом примере у нас всё будет выполняться на одной ноде (причем это мастер, поэтому не делайте так ;)). Как видно, есть три стадии исполнения, две из которых просто пишут Hello World в консоль (какая неожиданность), а третья вызывает не менее простой job и передаёт в него параметр, который также нужно напечатать в консоли.
Если выполнить этот таск, то мы увидим в логах нечто подобное:
Ура, у нас выполнились и наши команды из скрипта, и наш дочерний таск, который мы определили отдельно.
Теперь представим, что между первой и второй стадией, нам нужно одобрение от внешней системы на продолжение исполнения работы. Для того, чтобы его реализовать, будем использовать механизм ожидания ввода данных пользователем через конструкцию input. В простейшем виде это будет выглядеть так:
Запустив наш job ещё раз, мы увидим, что с нас теперь требуют выполнить подтверждающее действие в интерфейсе: 
Но интерфейс это круто для любителей щелкать мышью, но он никак не решает нашей задачи, поэтому идём курить API. И тут с документацией не всё в порядке. Чтобы понять что и как вызвать, нужно спросить совета у знающих в чатике людей, и исследовать код.
Тут стоит обратить внимание, что реальный ID всегда будет начинаться с заглавной буквы. В итоге в моём случае запрос оказался следующим:
Дополнительной плюшкой механизма input-ов является возможность задавать дополнительные параметры, которые потом можно использовать:
Обратите внимание, что в value передаётся весь объект целиком. В случае если параметров будет несколько, необходимо указывать явно какой параметр нужно взять:
В интерфейсе у нас теперь будет как-то так:
Но нам опять таки GUI малоинтересен и идём дальше изучать API. Чтобы пробросить параметр через обычный HTTP, нужно использовать другой метод: proceed :
При этом нам нужно передать форму с параметрами и их значениями. Для этого в первую очередь сформируем правильный JSON:
Здесь name — имя параметра, а value соответственно его значение.
Не слишком красиво, но это работает. Теперь в логах мы сможем наблюдать, что действительно действия были подтверждены пользователем (в нашем случае администратором):
В случае, когда внешняя система добро не даёт, ей нужно дёрнуть метод abort :
Никакие данные передавать при этом не надо. В логах после исполнения этого запроса мы увидим, что выполнение действительно было отклонено пользователем:
Ну и напоследок. Не забывайте, что все эти запросы требуют basic-авторизации, токена и crumbs. Последние можно получить по адресу: JENKINS_ROOT_URL/crumbIssuer/api/json :
Резюме
В текущем виде Pipeline Plugin даёт возможности по встраиванию управляющих воздействий со стороны внешних систем, что открывает массу возможностей для автоматизации доставки ПО при сложных и переходных процессах внедрения. В то же время, хочется всё-таки более очевидного и красивого API для этих действий.
Jenkins Pipeline: заметки об оптимизации. Часть 1
Меня зовут Илья Гуляев, я занимаюсь автоматизацией тестирования в команде Post Deployment Verification в компании DINS.
В DINS мы используем Jenkins во многих процессах: от сборки билдов до запуска деплоев и автотестов. В моей команде мы используем Jenkins в качестве платформы для единообразного запуска смоук-проверок после деплоя каждого нашего сервиса от девелоперских окружений до продакшена.
Год назад другие команды решили использовать наши пайплайны не только для проверки одного сервиса после его обновления, но и проверять состояние всего окружения перед запуском больших пачек тестов. Нагрузка на нашу платформу возросла в десятки раз, и Jenkins перестал справляться с поставленной задачей и стал просто падать. Мы быстро поняли, что добавление ресурсов и тюнинг сборщика мусора могут лишь отсрочить проблему, но не решат ее полностью. Поэтому мы решили найти узкие места Jenkins и оптимизировать их.
В этой статье я расскажу, как работает Jenkins Pipeline, и поделюсь своими находками, которые, возможно, помогут вам сделать пайплайны быстрее. Материал будет полезен инженерам, которые уже работали с Jenkins, и хотят познакомиться с инструментом ближе.
Что за зверь Jenkins Pipeline
Jenkins Pipeline — мощный инструмент, который позволяет автоматизировать различные процессы. Jenkins Pipeline представляет собой набор плагинов, которые позволяют описывать действия в виде Groovy DSL, и является преемником плагина Build Flow.
Скрипт для плагина Build Flow исполнялся напрямую на мастере в отдельном Java-потоке, который выполнял Groovy-код без барьеров, препятствующих доступу к внутреннему API Jenkins. Данный подход представлял угрозу безопасности, что впоследствии стало одной из причин отказа от Build Flow, и послужило предпосылкой для создания безопасного и масштабируемого инструмента для запуска скриптов — Jenkins Pipeline.
Подробнее об истории создания Jenkins Pipeline можно узнать из статьи автора Build Flow или доклада Олега Ненашева о Groovy DSL в Jenkins.
Как работает Jenkins Pipeline
Теперь разберемся, как работают пайплайны изнутри. Обычно говорят, что Jenkins Pipeline — совершенно другой вид заданий в Jenkins, непохожий на старые добрые freestyle-джобы, которые можно накликать в веб-интерфейсе. С точки зрения пользователя это, может, и выглядит так, но со стороны Jenkins пайплайны — набор плагинов, которые позволяют перенести описание действий в код.
Сходства Pipeline и Freestyle джобы
Правда в том, что параметры, описанные в Pipeline, автоматически добавятся в раздел настройки в веб-интерфейсе при запуске джобы. Верить мне можно потому, что этот функционал в последней редакции писал я, но об этом подробнее во второй части статьи.
Отличия Pipeline и Freestyle джобы
Запуск Jenkins Declarative Pipeline
Процесс запуска Jenkins Pipeline состоит из следующих шагов:
При старте pipeline-джобы Jenkins создает отдельный поток и направляет задание в очередь на выполнение, а после загрузки скрипта определяет, какой агент нужен для выполнения задачи.
Для поддержки данного подхода используется специальный пул потоков Jenkins (легковесных исполнителей). Можно заметить, что они выполняются на мастере, но не затрагивают обычный пул исполнителей:
Количество потоков в данном пуле не ограничено (на момент написания статьи).
Работа параметров в Pipeline. А также триггеров и некоторых опций
Обработку параметров можно описать формулой:
Из параметров джобы, которые мы видим при запуске, сначала удаляются параметры Pipeline из предыдущего запуска, а уже потом добавляются параметры заданные в Pipeline текущего запуска. Это позволяет удалить параметры из джобы, если они были удалены из Pipeline.
Учимся разворачивать микросервисы. Часть 4. Jenkins
Это четвертая и заключительная часть серии статей «Учимся разворачивать микросервисы», и сегодня мы настроим Jenkins и создадим пайплайн для микросервисов нашего учебного проекта. Jenkins будет получать файл конфигурации из отдельного репозитория, собирать и тестировать проект в Docker-контейнере, а затем собирать Docker-образ приложения и пушить его в реестр. Последней операцией Jenkins будет обновлять кластер, взаимодействуя с Helm (более подробно о нем в прошлой части).
Ключевые слова: Java 11, Spring Boot, Docker, image optimization
Ключевые слова: Kubernetes, GKE, resource management, autoscaling, secrets
Ключевые слова: Helm 3, chart deployment
Настройка Jenkins и пайплайна для автоматической доставки кода в кластер
Ключевые слова: Jenkins configuration, plugins, separate configs repository
Jenkins — это сервер непрерывной интеграции, написанный на Java. Он является чрезвычайно расширяемой системой из-за внушительной экосистемы разнообразных плагинов. Настройка пайплайна осуществляется в декларативном или императивном стиле на языке Groovy, а сам файл конфигурации (Jenkinsfile) располагается в системе контроля версий вместе с исходным кодом. Это удобно для небольших проектов, однако, часто более практично хранить конфигурации всех сервисов в отдельном репозитории.
Код проекта доступен на GitHub по ссылке.
Установка и настройка Jenkins
Установка
Существует несколько способов установить Jenkins:
War-архив с программой можно запустить из командной строки или же в контейнере сервлетов (№ Apache Tomcat). Этот вариант мы не будем рассматривать, так как он не обеспечивает достаточной изолированности системы.
Устранить этот недостаток можно, установив Jenkins в Docker. Из коробки Jenkins поддерживает использование докера в пайплайнах, что позволяет дополнительно изолировать билды друг от друга. Запуск докера в докере — плохая идея (здесь можно почитать почему), поэтому необходимо установить дополнительный контейнер ‘docker:dind’, который будет запускать новые контейнеры параллельно контейнеру Jenkins’а.
Также возможно развернуть Jenkins в кластере Kubernetes. В этом случае и Jenkins, и дочерние контейнеры будет работать как отдельные поды. Любой билд будет полностью выполняться в собственном контейнере, что максимально изолирует выполнения друг от друга. Из недостатков этот способ имеет довольно специфичную конфигурацию. Из приятных бонусов Jenkins в Google Kubernetes Engine может быть развернут одним кликом.
Хоть третий способ и кажется наиболее продвинутым, мы выберем прямолинейный путь и развернем Jenkins в Docker напрямую. Это упростит настройку, а также избавит нас от нюансов работы со stateful приложениями в Kubernetes. Хорошая статья для любопытствующих про Jenkins в Kubernetes.
Так как проект учебный, то мы установим Jenkins на локальной машине. В реальной обстановке можно посмотреть в сторону, например, Google Compute Engine. В дополнение замечу, что изначально я пробовал использовать Jenkins на Raspberry Pi, но из-за разной архитектуры «малинки» и машин кластера они не могут использовать одни и те же Docker-образы. Это делает невозможным применение Raspberry Pi для подобных вещей.
После установки Jenkins открываем http://localhost:8080/ и следуем инструкциям. Настроить Jenkins можно через UI, либо программно. Последний подход иногда называют «инфраструктура как код» (IaC). Он подразумевает описание конфигурации сервера с помощью хуков — скриптов на Groovy. Оставим этот способ настройки за рамками данной статьи. Для интересующихся ссылка.
Плагины
Для нашего проекта нам понадобится установить два плагина: Remote File Plugin и Kubernetes CLI. Remote File Plugin позволяет хранить Jenkinsfile в отдельном репозитории, а Kubernetes CLI предоставит доступ к kubectl внутри нашего пайплайна.
Установка Helm
Глобальные переменные среды
Так как у нас два сервиса, то мы создадим два пайплайна. Некоторые данные у них будут совпадать, поэтому логично вынести их в одно место. Это можно сделать, задав глобальные переменные среды, которые будут установлены перед выполнением любого билда на сервере Jenkins. Отмечу, что не стоит с помощью этого механизма передавать пароли — для этого существуют секреты.
Секреты
| Имя секрета | Тип | Описание |
|---|---|---|
| github-creds | username with password | Логин/пароль от git-репозиториев |
| dockerhub-creds | username with password | Логин/пароль от реестра Docker-образов |
| kubernetes-creds | secret text | Токен сервисного аккаунта нашего кластера |
В предыдущей части в файле NOTES.txt нашего чарта мы описали последовательность команд для получения токена сервисного аккаунта. Вывести эти команды для кластера можно, запросив статус Helm-инсталляции ( helm status msvc-project ).
Конфигурация пайплайна
Как уже было упомянуто ранее, пайплайны описываются на Groovy, и могут быть написаны в декларативном и императивном стилях. Мы будем придерживаться декларативного подхода.
В Jenkins процесс выполнения пайплайна (билд) поделен на ряд шагов (stage). Каждый шаг выполняется определенным агентом (agent).
Наши пайплайны будут состоять из следующих шагов:
Структура файла конфигурации
Файл конфигурации будет иметь следующую структуру:
Агенты в Jenkins подчиняются типичным правилам «наследования» — если в шаге не определен агент, то будет использован агент родительского шага. Тег pipeline может рассматриваться как корневой шаг для всех остальных. Корневой шаг мы используем для объявления переменных среды и опций, которые по тому же правилу наследования будут иметь силу для всех вложенных шагов. Поэтому для тега pipeline установлен агент ‘none’. Использование этого агента подразумевает, что вложенные шаги обязаны переопределить этот агент для выполнения каких-либо полезных действий.
Агент в шагах Push Images и Trigger Kubernetes равен ‘any’. Это значит, что шаг может быть выполнен на любом доступном агенте. В простейшем случае это означает выполнение в контейнере Jenkins’а. Также эти шаги будут выполнены только для коммитов в мастер-ветку ( when < branch 'master' >).
Далее мы более пристально посмотрим на каждый из шагов, а также на блоки options и environment.
Опции
Блок опций может быть использован для настройки выполнения пайплайна или же отдельного шага. Мы используем следующие опции:
skipStagesAfterUnstable заставит Jenkins сразу прервать билд, eсли тесты были провалены. Поведение по умолчанию предусматривает установку статуса билда в UNSTABLE и продолжение выполнения. Это позволяет в сложных случаях более гибко обрабатывать подобные ситуации.
skipDefaultCheckout отключает автоматический чекаут репозитория проекта. Дефолтно Jenkins делает force чекаут репозитория для каждого шага с собственным агентом (в нашем случае Prepare Checkout, Push images и Trigger Kubernetes). То есть по сути затирает все изменения. Это может быть полезно при использовании пайплайна с несколькими различными образами. Однако нам нажно получить исходники с репозитория только единожды — на шаге Build. Применив опцию skipDefaultCheckout, мы получаем возможность произвести чекаут вручную. Также стоит заметить, что Jenkins будет автоматически переносить артефакты между шагами. Так, например, скомпилированные исходники из шага Build будут полностью доступны в шаге Test.
Переменные среды
Переменные среды могут быть также объявлены как для всего пайплайна, так и для отдельного шага. Их можно использовать, чтобы вынести какие-то редкоизменяемый свойства. В этом блоке мы определим имя файла докера и имена создаваемых Docker-образов.
В предыдущих статьях при работе с кластером мы всегда использовали наиболее свежие latest образы, но напомню, что это не лучший вариант из-за проблем при откатах к предыдущим версиям. Поэтому мы предполагаем, что в начальный момент времени кластер создается из самых свежих образов, а потом уже будет обновляться на конкретную версию. Тег IMAGE_TAG будет зависеть только от номера билда, который можно получить из предустановленной глобальной переменной среды BUILD_NUMBER. Таким образом наши версии будут составлять монотонную последовательность при условии того, что пайплайн не будет пересоздаваться (это приведет к сбросу номера билда). При неуспешных билдах BUILD_NUMBER также будет инкрементирован, следовательно последовательность версий образов может содержать «пробелы». Основное преимущество такого подхода к версионированию — его простота и удобство восприятия человеком. В качестве альтернативы можно подумать об использовании метки времени, чексуммы коммита или даже внешних сервисов.
Компиляция, тестирование, сборка
Чисто технически фазы компиляции, тестирования и сборки возможно объединить в один шаг, но для лучшей наглядности мы опишем их как отдельные шаги. С помощью плагинов Maven можно с легкостью добавлять дополнительные фазы, такие как статический анализ кода или интеграционное тестирование.
В фазе тестирования командой junit ‘**/target/surefire-reports/TEST-*.xml’ мы указываем Jenkins’у на файл с результатами тестов. Это позволит их отобразить прямо в веб-интерфейсе.
На последнем шаге мы генерируем jar-архив с нашим приложением.
Создание и отправка Docker-образа в реестр
На следующем шаге мы должны собрать Docker-образы и запушить их в реестр. Мы будем делать это средствами Jenkins, но в качестве альтернативы можно реализовать это и с помощью Maven-плагина.
Для начала нам надо доработать докер-файлы наших сервисов, которые мы разработали в первой статье цикла. Эти докер-файлы собирали приложение из исходников прямо в процессе создания образа. Сейчас же у нас имеется протестированный архив, следовательно один из шагов создания образа уже выполнен средствами Jenkins. Мы назовем этот новый файл Dockerfile-packaged.
Докер-файл для микросервиса шлюза аналогичен.
В конце шага происходит удаление установленных локально образов.
Обновление кластера Kubernetes
Финальным шагом осталось сообщить Kubernetes, что в реестре появился новый образ, и необходимо запустить процедуру обновления подов одного из микросервисов.
Итоговый Jenkinsfile
Jenkinsfile для микросервиса шлюза полностью аналогичен.
Подключение пайплайна
В Jenkins существует несколько видов пайплайнов. В данном проекте мы используем Multibranch pipeline. Как и следует из названия, билд будет запускаться для любого коммита в произвольной ветке.
Branch sources. Выбираем GitHub, в графе ‘Credentials’ выбираем секрет с логином/паролем от аккаунта и указываем URL репозитория с исходным кодом микросервиса.
Build Configuration. В Mode выбираем ‘by Remote File Plugin’, основное поле — Repository URL, в котором надо указать адрес репозитория с Jenkinsfile, а также Script Path с путем к этому файлу.
Scan Repository Triggers. В этом разделе настроим период, с которым Jenkins будет проверять, появились ли какие-то изменения в отслеживаемом репозитории. Недостаток этого подхода в том, что Jenkins будет генерировать трафик, даже когда в репозитории ничего не менялось. Более грамотный подход — настроить веб-хуки. При этом хранилище исходного кода само будет инициировать запуск билда. Очевидно, что сделать это можно, только если Jenkins доступен по сети для хранилища исходных кодов (они должны быть либо в одной сети, либо Jenkins должен иметь публичный IP-адрес). Подключение веб-хуков оставим за рамками данной статьи.
Запуск
После того как наш пайплайн настроен, можно его запустить. Наиболее удобно это сделать из меню Blue Ocean (Open Blue Ocean). Первый запуск может занять продолжительное время, так как потребуется время на загрузку Maven-зависимостей. После выполнения билда можно подключиться к кластеру и убедиться в том, что тег образа микросервиса был изменен ( helm get values msvc-project ).
В дальнейшем Jenkins будет отслеживать изменения в репозитории микросервиса и запускать билд автоматически.
Заключение
Jenkins — очень гибкая система, позволяющая реализовывать процесс непрерывной интеграции и развертывания любой сложности. В этой статье мы только коснулись этого инструмента, создав простенький пайплайн для микросервисов нашего проекта. В будущем этот пайплайн можно значительно дорабатывать и улучшать, например, добавив уведомления, дополнительные шаги, веб-хуки и многое-многое другое.
📜 Как создать свой первый пайплайн CI/CD в Jenkins?

Пошаговое руководство по созданию пайплайна Jenkins
Почему пайплайн Jenkins?
Это тот случай, где Jenkins Pipeline входит в игру.
В DevOps непрерывная интеграция и непрерывная доставка (CI / CD) достигаются с помощью пайплайна Jenkins.
Что такое пайплайн Jenkins?
Jenkins Pipeline – это сочетание заданий для непрерывной доставки программного обеспечения с использованием Jenkins.
Пайплайн Jenkins состоит из нескольких состояний или этапов, и они выполняются в последовательности один за другим.
JenkinsFile – это простой текстовый файл, который используется для создания пайплайна в виде кода в Jenkins.
Он содержит код на Groovy Domain Specific Language (DSL), который прост в написании и удобочитаем.
Вы можете запустить JenkinsFile отдельно, либо вы можете запустить этот код из Jenkins Web UI.
Существует два способа создания пайплайна с помощью Jenkins.
Создание пайплана Jenkins
Так выглядит пайплаен Jenkins, состоящий из нескольких этапов между разработкой программного обеспечения и программного обеспечения, поставляемое в производство.
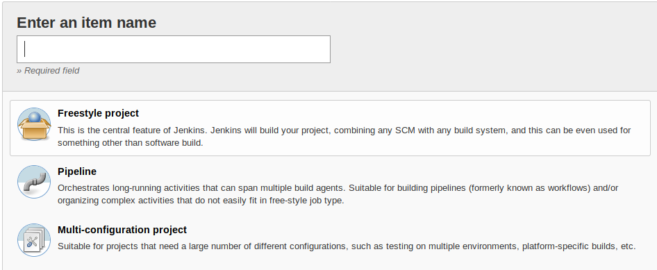
Давайте создадим декларативный пайплайн.
З атем введите имя элемента, например, «First Pipeline» и выберите проект «Pipeline». Затем нажмите ОК.
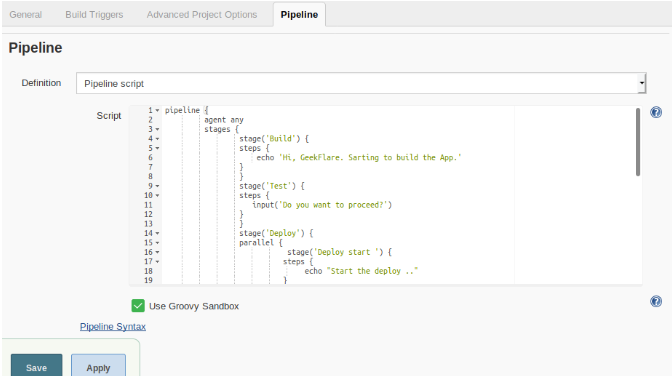
Наконец, есть стадия Prod с простым шагом echo.
Вышеописанный пайплан имеет этапы, на которых есть простые шаги, чтобы вы могли понять, как он работает.
Как только вы научитесь создавать пайплайны, вы можете добавить больше сложного в этот кода и создавать сложные конвейеры.
Получив код на вкладке Pipeline, нажмите Применить и Сохранить.
Управление задачами в Jenkins
Jenkins сейчас используется, пожалуй, практически в любой компании, где есть необходимость в автоматическом деплое приложений и инфраструктуры, а также в удобном управлении различного рода задач.
На рынке сейчас представлено много других инструментов (как платных, так и бесплатных), позволяющих построить процесс непрерывной интеграции максимально комфортно.
Jenkins является бесплатным инструментом, обладающим огромными возможностями в виде тысяч плагинов, которые постоянно добавляются и обновляются.
Базовый подход к управлению задачами предлагается нам через веб-интерфейс самого Jenkins, где мы можем что угодно сконфигурировать, но поддерживать это при большом количестве задач и их разнотипности становится сложнее.
Ниже мы рассмотрим, как упростить и ускорить создание задач в Jenkins.
Инструменты, которые будем использовать
Jenkins job builder
Это python-утилита, позволяющая описывать задачи в YAML- или JSON форматах, которые через HTTP API загружаются на сервер. Для работы достаточно установить ее на локальной машине, написать конфигурацию с подключением и описать требуемые задачи.
DSL Plugin
Это плагин для Jenkins, с помощью которого мы сможем описывать задачи на специальном языке (DSL, Domain Specific Language) и создавать их на основе этих описаний. Работает локально на самом Jenkins-сервере.
Jenkins Pipeline
Это тип задачи в Jenkins, с помощью которого мы можем описать необходимый нам процесс деплоя или сборки приложения по стадиям. Описывать pipeline мы будем в специальном Jenkinsfile, который будет храниться в репозитории проекта.
Gitlab и Gitlab CI
Наиболее популярный и развивающийся сейчас selfhosted проект, который также используется во многих компаниях. Он включает в себя версию для сообщества и энтерпрайз-решение.
Внутри имеется собственный CI, написанный на Go, который через специальные подключаемые агенты (runners) позволяет нам проводить различные стадии сборки и деплоя.
Итак, начнем
Для начала поставим необходимые инструменты. Jenkins-job-builder в нашем случае необходимо установить как на локальную машину, так и на машину, где будет работать агент gitlab. Можно обойтись просто локальной машиной gitlab.
Локально на linux и mac установим последнюю доступную версию:
Локально для описания нашего seed job мы сможем протестировать его работоспособность.
Добавлю, что seed job в терминологии DSL Plugin является задача типа Free-style project, которая создает остальные задачи из DSL-скриптов.
На gitlab-сервере установка будет ничем не отличаться от локальной установки на linux-машину:
На всякий случай запустим утилиту и проверим, что она работает:
Установка плагина
Теперь установим плагин в Jenkins. Для установки можно воспользоваться как классическим UpdateCenter в разделе Manage Jenkins → Manage Plugins → Available, так и используя установку с помощью curl/wget, скачав плагин с официальной страницы плагина:
Создание репозитория
Создадим репозитории под код с описанием задач.
Для начала подготовим наш seed job — так называется задача, которая генерирует из себя все остальные. Репозиторий будет состоять из следующих файлов:
jenkins.ini
job-generator.yml
.gitlab-ci.yml
Подключим gitlab-runner к нашему проекту. Поскольку интерфейс gitlab последнее время часто меняется, то рекомендуем обращаться к официальной документации.
После подключения он будет выглядеть примерно так:
Теперь закоммитим изменения и в разделе Jobs у нашего проекта увидим следующее:
Вся схема выглядит следующим образом:
Подготовим репозиторий с описанием задач. Создадим его с названием repo-dsl и плоской структурой. Все файлы располагаются как есть.
Положим в него файл с нашим pipeline:
И настроим webhook по запуску seed-job, который мы создали ранее.
В данной версии gitlab webhooks располагаются в проекте в разделе Settings → Integrations.
Создаем webhook на push (http://gitlab:pass@ci.org/project/job-generator). Схематично это выглядит вот так:
Теперь в нашем Jenkins есть две задачи:
В проекте с названием sample-project создадим Jenkinsfile следующего содержания:
В итоге готовый pipeline будет выглядеть следующим образом в интерфейсе blueocean в Jenkins:
Или так в классическом интерфейсе:
Для запуска этой задачи автоматически мы можем добавить webhook в проекте с docker-image, где после отправки изменений в репозиторий будет запускаться эта задача.
В заключении отметим, что данная статья описывает лишь один из множества подходов управления задачами в jenkins. За счет гибкости и функционала вы можете использовать разные подходы, которые позволят именно вам управлять задачами максимально просто и удобно исходя из ваших требований и требований инфраструктуры.



