Что такое BM25
Время чтения: 2 минуты Нет времени читать?
BM 25 (от англ. Best match) – функция ранжирования, которое используется поисковыми системами для распределения документов по их релевантности данному запросу. В поисковых системах эта функция относится к машинному обучению.
История BM25
Данная функция появилась в Лондоне 1980-1990-х годах и придумана учеными Лондонского университета Карен Спарк Джонс и Стивеном Робертсоном, где и была впервые использована.
Суть функции была в чем: документ анализируется, значения попадают в формулу, где сравниваются показатели относительно других документов и в конечном итоге выдается оценка, которая влияет на ранжирование страницы в поисковой выдаче. Сложно, но давайте разберем более подробно.
Как рассчитывается BM25
Допустим у нас есть запрос Q который содержит слова от q1 до qn. В этом случае BM25 выдаст нам оценку релевантности документа D к запросу Q

Где f (qi, D) это частота слова,
qi в документе D – длина документов (количество слов в документе)
Avgdl – средняя длина документа
K1 и b – свободные коэффициенты, обычно их выбирают как k1=2.0 и b=0.75
IDF(qi) – это обратная документная частота слова qi. Существует несколько версий относительно IDF и вариации его формулы.
Она определяется как:

N – это общее количество документов в коллекции
N(qi) – количество документов которые содержат qi.
Но чаще всего применяется более упрощенный вариант этой формулы, например, одна из таких:

Обратите внимание, что в формуле содержащая IDF есть недостаток. Слова, входящие в половину документов и более из коллекции – значение IDF для них будет отрицательным. Получается, при наличии двух почти одинаковых документов, в одном из которых есть слово, а во втором нет, второй получит большую оценку.
Часто встречающиеся слова испортят конечную оценку документа. Этого лучше избежать, но во многих приложениях формулу, которую я привел выше может быть скорректирована различными способами:
Также существует дополнительная модификация BM25F, в которой документ рассматривается как совокупность двух и более полей (заголовки, тест, ссылочный текст и тд), длины которых независимо и каждый из который несет свою значимость для итоговой оценки ранжирования страницы.
Заключение:
BM25 для SEO-специалистов темный лес (возможно даже не слышали при продвижении проектов), так как поисковые системы не могут разглашать принципы работы данной функции, иначе зачем тогда вообще SEO, если всё изначально было так предсказуемо.
Функции ранжирования в поисковых системах: Okapi BM25, BM25, BM25F

Что такое ранжирование
Ранжирование — процесс упорядочивания документов в соответствии со степенью их соответствия поисковому запросу. Главной целью ранжирования является размещение наиболее релевантных (соответствующих запросу) документов коллекции на более высокие позиции в выдаче поисковой системы. Для решения задачи поиска используются специальные функции, на основе которых и рассчитывается релевантность.

Что такое релевантность
Релевантность является функцией от набора переменных (факторы ранжирования). В качестве таких факторов выступают различные числовые характеристики документа, при помощи которых можно различать релевантные документы и не релевантные. Количество факторов ранжирования не является фиксированным числом и может изменяться. К примеру, Google в настоящее время при ранжировании не учитывает мета-тег «keywords» — хотя ранее он имел значение.
Функции ранжирования
Поисковые системы Yandex и Google используют значительно больше таких факторов — функция ранжирования учитывает более чем 150 компонентов на сегодняшний день. Большая часть этих факторов представляет собой простые числовые характеристики документа. Ключевым моментом в ранжировании является способ комбинации факторов — вид функции релевантности.
Okapi BM25
В современных поисковых системах расчет релевантности документов базируется на функции Okapi BM25, основанной на вероятностной модели, разработанной в 1970-х и 1980-х годах Стивеном Робертсоном и Карен Спарк Джоунс.
BM25 и BM25F
BM25 и его более современные модификации (например, BM25F) представляют собой TF-IDF-подобные функции ранжирования. TF-IDF (от англ. TF — term frequency, IDF — inverse document frequency) — статистическая мера, которая используется для оценки важности слова в контексте документа (являющегося в свою очередь частью определенной коллекции документов). Вес некоторого слова пропорционален количеству употребления этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции.
К примеру, если в документе содержится 100 слов и слово «дерево» встречается в нём 5 раз, то частота слова (TF) для слова «дерево» в документе будет 0,05 (5/100). Частоту документа (DF) определяют как количество документов, содержащих слово «дерево», разделенное на количество всех документов. Т.е., если слово «дерево» содержится в 1000 документов из 10 000 000 документов, то DF для него будет равен 0,0001 (1000/10000000). Для окончательного расчета веса слова TF делят на DF. В нашем примере, TF-IDF вес для слова «дерево» будет 500 (0,05/0,0001).
В реальном веб-поиске эти функции ранжирования зачастую входят как компоненты в гораздо более сложную функцию ранжирования. BM25F — модификация BM25, в которой документ рассматривается уже как совокупность нескольких полей (заголовки, основной текст, ссылочный текст и т.д.), каждому из которых присваивается своя степень значимости в конечном виде функции ранжирования.
Коммерческая тайна
Полный список критериев, как и конкретный вид модифицированной формулы ранжирования Okapi BM25, был и остаётся главной коммерческой тайной крупных поисковых систем. Это вызвано естественным сопротивлением поисковых систем заинтересованности оптимизаторов в данной информации с целью воздействия на алгоритмы ранжирования с максимальной эффективностью.
Алгоритм bm25

В 1970х и 1980х годах британскими учеными (как бы забавно это ни звучало), Стивеном Робертсоном и Карен Спар Джоунс, был разработан вероятностно-поисковой механизм. Их труды легли в основу bm25, алгоритма ранжирования, о котором мы сегодня поговорим. Суть функции заключается в определении релевантности документа к поисковому запросу. Т. е. документ анализируется, значения проставляются в формулу, где идет расчет относительно других документов в коллекции и выдается некая конечная оценка, которая влияет на ранжирование документа в поисковой выдаче. Сложновато.
Данную функцию еще часто называют «Okapi bm25», в честь поисковой системы, которая была создана в Лондонском городском университете в 1980х, 1990х годах.
Как ведется расчет
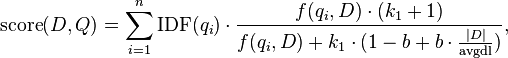
Мы не будем разбирать всю формулу bm25 полностью, но пройдемся по основным значениям.
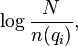
где N обозначает суммарное количество документов в коллекции, а n (q i ) — показывает числовое значение документов, которые содержат q i. Но в основном применяются более адаптированные варианты формулы, одна из них выглядит так:
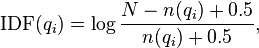
Стоит обратить внимание, что в данной формуле IDF есть один недостаток. Для слов, которые входят более чем в половину документов из коллекции — значение IDF будет отрицательным. Простыми словами, это означает, что два почти одинаковых документа, в одном из которых есть определенное слово, а в другом нет — то второй документ может получить оценку больше чем первый. Другими словами, если слова часто встречаются в документе, то это отрицательно повлияет на окончательную оценку документа. Это является нежелательным эффектом при расчете вм25, поэтому во многих приложениях данная формула корректируется следующими способами:
BM25 °F — это модификация BM25, где документ анализируется как совокупность нескольких блоков (например, ссылочный текст, заголовки h1-h3, основная часть текста) длины которых независимо нормализуются, а каждому участку назначается своя степень значимости в итоговой функции ранжирования.
К сожалению, полный список критериев, а также конкретный вид формулы вм25 до сих пор коммерческая тайна поисковых систем. Что вполне естественно, ведь, владея точной информацией оптимизаторы могут воздействовать на алгоритм в своих интересах.

– Только качественный трафик из Яндекса и Google
– Понятная отчетность о работе и о планах работ
– Полная прозрачность работ
Алгоритм Okapi BM25 – модификация формулы TF-IDF ранжирования документов
BM25 – функция расчета текстовой релевантности документов, разработанная британцами Стивеном Робертсоном и Карен Спарк Джоунс, опубликованная в 1994 году. Основана на эмпирических данных при попытке улучшить результаты работы критерия TF-IDF. Наилучшее соответствие между ожидаемым результатом и рассчитанным показал 25 алгоритм в списке, за что и получил свое название «Best matching», или BM25. Впервые был реализован в поисковой системе Okapi (Окапи), а в дальнейшем – положен в основу текстовых анализаторов современных поисковых машин.
Что такое TF-IDF
TF-IDF – формула оценки значимости определенного слова в документе относительно всей выборки. Разработана Джорджом Солтоном в середине 70-х годов. Согласно TF-IDF, вес слова пропорционален количеству употреблений в текущем документе и обратно пропорционален частоте употребления слова в других документах выборки. Если слово используется в этом документе чаще, чем в других, то оно имеет большую значимость для него – именно такой критерий релевантности документа по запросу был у первых анализаторов поисковых систем.
Расшифровка TF-IDF
TF (term frequency) – это частотность слова, показывающая, насколько часто оно употребляется в документе. В длинном тексте вхождений термина может быть значительно больше, чем в коротком, хотя это вовсе не означает, что он точнее отвечает требованиям посетителей. Чтобы уравнять шансы длинных и коротких документов, используется отношение количества употребления слова к общему количеству слов в документе.

IDF (inverse document frequency) – обратная частота употребления слова в документе. Вводится в формулу для снижения веса часто употребляемых слов в выборке. После расчета TF мы получили только частотность, но слова сами по себе еще равнозначны. Часто употребляемые предлоги и союзы не могут быть сопоставимы по важности с другими словам, так как не несут смысловой нагрузки, поэтому, чтобы перераспределить вес значимости, вводится множитель IDF. Редкие слова получают более высокую значимость, а часто употребляемые – низкую.
Основание логарифма может быть любым, так как IDF является относительной мерой. Итоговая формула выглядит следующим образом:
Расчет TF-IDF
Возьмем условный документ X, состоящий из 456 слов и содержащий 2 вхождения термина «компьютер». TF для этого слова будет составлять:
Вычислим IDF, предположив, что у нас всего 210420 документов в выборке и 10241 из них содержат термин «компьютер»:
| TF | ||
| Количество слов в документе | 456 | 0,004386 |
| Количество вхождений термина в документ | 2 | |
| IDF | ||
| Всего документов в выборке | 210420 | 1,312745 |
| Количество документов c вхождением термина | 10241 | |
| TF-IDF | 0,005758 |
Умножив TF на IDF, получаем оценку важности термина «компьютер» для документа X: TFIDF=0,004386·1,312745=0,005758. Рассмотрим другой пример. У нас есть 4 условных документа, имеющих следующее содержание:
| 1 | Текстовая релевантность – это соответствие текста страницы или целого сайта конкретному поисковому запросу. Чем выше текстовая релевантность, тем больше у вашей странички шансов попасть на первую строку выдачи поисковиков при равенстве прочих факторов. |
| 2 | Текстовая релевантность в поиске – это мера соответствия совокупности внутритекстовых факторов страницы запросу, поставленному пользователем. К внутритекстовым факторам относятся: заголовки, текстовое содержание, форматирование текста, атрибуты тегов. |
| 3 | Релевантность в общем смысле – это соответствие документа ожиданиям пользователя. Таким образом, релевантность в поиске – это степень удовлетворения пользователя показанными в ответ на его запрос поисковыми результатами. Высчитывается с помощью алгоритмов поисковых систем. |
| 4 | Соответствие документа запросам пользователей, а также соблюдение правил поисковых систем позволяют данному сайту занимать более высокие позиции в поиске. |
Рассчитаем TF-IDF для данных документов по ключевым словам:
Посчитаем общее количество слов в документах, а также количество вхождений каждого слова из запроса в документ.
| № документа | Всего слов | Текстовая | Релевантность | Документа | Поиске |
|---|---|---|---|---|---|
| 1 | 25 | 2 | 2 | 0 | 0 |
| 2 | 22 | 1 | 1 | 0 | 1 |
| 3 | 26 | 0 | 3 | 1 | 1 |
| 4 | 17 | 0 | 0 | 1 | 1 |
| Итого: | 2 | 3 | 2 | 3 | |
Рассчитаем множители TF и IDF для каждого слова:
| Cлова | TF | IDF | |||
|---|---|---|---|---|---|
| 1 док | 2 док | 3 док | 4 док | ||
| Текстовая | 0,080 | 0,045 | 0,000 | 0,000 | 0,301 |
| Релевантность | 0,080 | 0,045 | 0,115 | 0,000 | 0,125 |
| Документа | 0,000 | 0,000 | 0,038 | 0,059 | 0,301 |
| Поиске | 0,000 | 0,045 | 0,308 | 0,059 | 0,125 |
В итоге получаем TF-IDF равным:
| Cлова | TF-IDF | |||
|---|---|---|---|---|
| 1 док | 2 док | 3 док | 4 док | |
| Текстовая | 0,024 | 0,014 | 0,000 | 0,000 |
| Релевантность | 0,010 | 0,006 | 0,014 | 0,000 |
| Документа | 0,000 | 0,000 | 0,012 | 0,018 |
| Поиске | 0,000 | 0,006 | 0,005 | 0,007 |
Вес запросов относительно документов рассчитаем как сумму TF-IDF каждого слова из запроса:
| Запросы | Σ(TF·IDF) | |||
|---|---|---|---|---|
| 1 док | 2 док | 3 док | 4 док | |
| Релевантность | 0,010 | 0,006 | 0,014 | 0,000 |
| Текстовая релевантность | 0,034 | 0,020 | 0,014 | 0,000 |
| Текстовая релевантность документа | 0,034 | 0,020 | 0,026 | 0,018 |
| Текстовая релевантность документа в поиске | 0,034 | 0,026 | 0,031 | 0,025 |
Запрос «Релевантность» наиболее значимый в 3 документе, что не удивительно, ведь в нем, больше всего вхождений. По аналогичной причине запрос «Текстовая релевантность» более значим в 1 документе. Дальше интереснее – первый текст вовсе не содержит слов «Документа», «Поиске», но при этом все равно выигрывает у других по оценке TF-IDF. Стоит отметить, что абсолютно все слова, по которым идет поиск, не содержит ни один документ. Больше всего, а именно 3 слова из 4, содержит третий документ. Добавим недостающее слово «Текстовая» в третий текст и посмотрим на результаты:
| Запросы | Σ(TF·IDF) | |||
|---|---|---|---|---|
| 1 док | 2 док | 3 док | 4 док | |
| Релевантность | 0,010 | 0,006 | 0,014 | 0,000 |
| Текстовая релевантность | 0,020 | 0,011 | 0,010 | 0,000 |
| Текстовая релевантность документа | 0,020 | 0,011 | 0,031 | 0,018 |
| Текстовая релевантность документа в поиске | 0,020 | 0,017 | 0,036 | 0,025 |
Ситуация ожидаемо изменилась в пользу документа 3, за ним идет документ 4, а первый – только на третьем месте. При этом в документы 4 и 1 никаких изменений не вносилось. Уберем предыдущее изменение и добавим слово «Релевантность» в документ 4. IDF по этому запросу равен 0, т.к. запрос встречается во всех документах. За счет этого документ 4 выигрывает оценку TF-IDF по запросу «Текстовая релевантность документа в поиске».
| Запросы | Σ(TF·IDF) | |||
|---|---|---|---|---|
| 1 док | 2 док | 3 док | 4 док | |
| Релевантность | 0,000 | 0,000 | 0,000 | 0,000 |
| Текстовая релевантность | 0,024 | 0,014 | 0,000 | 0,000 |
| Текстовая релевантность документа | 0,024 | 0,014 | 0,012 | 0,018 |
| Текстовая релевантность документа в поиске | 0,024 | 0,019 | 0,016 | 0,025 |
Скачать Пример расчета TF-IDF При увеличении вхождений ключевого слова в документ пропорционально увеличивается значение TF. Таким образом, добавление вхождений ключевых слов на страницу значительно повышает ее релевантность. Функция BM25 должна была устранить этот недостаток.
Расшифровка BM25
Робертсон хоть и утверждает, что для получения формулы использовалась вероятностная модель, но некоторые специалисты считают ее «подгонкой» под нужный результат. В функцию БМ25 внедрены свободные коэффициенты, которые могут принимать различные значения. Они подбираются так, чтобы «подогнать» результат работы поиска под заранее имеющиеся данные. Документы сначала оценивают асессоры, которые и говорят что плохо, а что хорошо. Затем на основании этих данных выбирают упомянутые коэффициенты, чтобы расположить документы так же, как это сделали асессоры – так называемый «принцип обезьянки». Оценка релевантности документа
используется сглаженная формула:
Релевантность по запросу Q равна сумме релевантностей по всем словам qi=q1,q2…qn из запроса. На первый взгляд, принцип работы такой же, как и TF-IDF:
Процентный рост BM25 от числа вхождений
| Число вхождений | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Рост Score в процентах | — | 50% | 20% | 11,1% | 7,1% | 5,0% | 3,7% | 2,9% | 2,3% | 1,9% |



Зависимость Score от объема текста (TF уменьшается).
| Объем текста (слов) | 50 | 150 | 250 | 350 | 450 | 550 | 650 | 750 | 850 |
|---|---|---|---|---|---|---|---|---|---|
| Падение Score в процентах | — | -4,60% | -4,40% | -4,20% | -4,10% | -3,90% | -3,80% | -3,60% | -3,50% |
Немногие помнят «золотую эру SEO», когда вебмастера спамили ключевыми словами, достигали более высокой релевантности за счет их количества и, добавив ко всему этому тысячу сапо-ссылок, за пару недель выходили в ТОП.
Расчет BM-25
Возьмем те же тексты и рассчитаем количество документов, содержащих слова из запроса, и среднюю длину документа.
| Текстовая | Релевантность | Документа | Поиске | ||
|---|---|---|---|---|---|
| Количество документов содержащих слово | 2 | 3 | 2 | 3 | |
| Док.1 | Док.2 | Док.3 | Док.4 | Средняя | |
| Длина документа | 25 | 22 | 26 | 17 | 22,5 |
Далее найдем IDF для каждого слова из запроса
| Слова из запроса | |||||
| Текстовая | Релевантность | Документа | Поиске | ||
| Док.1 | Частота слова | 0,080 | 0,080 | 0,000 | 0,000 |
| Док.2 | 0,045 | 0,045 | 0,000 | 0,045 | |
| Док.3 | 0,000 | 0,115 | 0,038 | 0,038 | |
| Док.4 | 0,000 | 0,000 | 0,059 | 0,059 | |
| IDF | 0 | -0,368 | 0 | -0,368 | |
В итоге получаем следующее значение TF и оценку Score по запросу «Текстовая релевантность документа в поиске»:
| Текстовая | Релевантность | Документа | Поиске | ||||
|---|---|---|---|---|---|---|---|
| Док.1 | TF | 0,107 | 0,107 | 0,000 | 0,000 | Score | 0,00107 |
| Док.2 | TF | 0,068 | 0,068 | 0,000 | 0,068 | Score | 0,00136 |
| Док.3 | TF | 0,000 | 0,147 | 0,051 | 0,051 | Score | 0,00198 |
| Док.4 | TF | 0,000 | 0,000 | 0,104 | 0,104 | Score | 0,00104 |
Скачать Пример расчета BM25 Наглядный пример, того как IDF может принимать отрицательные значения для слов, которые встречаются больше чем в половине документов. Вместо отрицательного значения IDF брали фиксированное IDF=0,01. Наибольшую оценку получил «документ 3», хотя в классической TF-IDF формуле – документ 1, который теперь имеет самую низкую оценку Score по BM25. Распределение оценок по различным запросам:
| BM25 | Запросы | |||
|---|---|---|---|---|
| № документа | Релевантность | Текстовая релевантность | Текстовая релевантность документа | Текстовая релевантность документа в поиске |
| Док.1 | ||||
| Док.2 | ||||
| Док.3 | ||||
| Док.4 | ||||
| BM25 | Запросы | |||
|---|---|---|---|---|
| № документа | Релевантность | Текстовая релевантность | Текстовая релевантность документа | Текстовая релевантность документа в поиске |
| Док.1 | ||||
| Док.2 | ||||
| Док.3 | ||||
| Док.4 | ||||
До этого мы рассматривали ограниченную выборку, в которой заранее известно, что документы околотематические. Для лучшего понимания формулы рассмотрим пример с нетематической коллекцией документов. Найдем Score в выборке из 20 000 документов.

IDF для слова «документа» значительно больше, чем для слов «релевантность» и «текстовая». Теперь увеличим частоту слова «документа» в док2 с 2% до 5%.

Видим значительный рост TF и Score при неизменном IDF. Увеличим частоту «текстовая» до 6% в док 1.

Сумма частот каждого слова из запроса в документе 1 и документе 2 одинаковая и составляет 13%, но термин «документа» меньше употребляется в коллекции. Из итоговой оценки и можно говорить, что значимость узкоспециализированных слов значительно выше, чем других терминов из запроса.
Тошнота документа по Минычу
В 2006-2007 годах по методике пользователя под ником Миныч на форуме Searchengines решили, что в Яндексе при расчете релевантности использовались похожие формулы:
Видим, что по данной формуле максимальная релевантность достигается, когда продвигаемый запрос ti является самым частотным в документе n(ti,d)=nmax, а плотность ключевого слова вообще не влияет на оценку. Миныч – первый, кто ввел понятие «Тошнота». В его методике тошнота W=max(√7,√nmax) – квадратный корень от частоты самого употребляемого слова nmax в документе. Если nmax меньше 7, то W=√7. При превышении некоторого порога спамности для конкретного слова, например W>25, накладывалась пессимизация документа.
Недостатки TF-IDF и BM-25
Используемая модель «bag-of-words» (мешок слов) не учитывает:
Поэтому одна лишь формула BM25 в чистом виде для оценки релевантности документа не использовалась.
Текстовые факторы ранжирования Яндекса (РОМИП-2006)
На РОМИП-2006 представители Яндекса несколько приоткрыли завесу тайны по используемым текстовым факторам ранжирования:
Вот несколько цитат:
При подсчете количества вхождений слова в документ мы проводим предварительную лемматизацию слов запроса и слов документа. Использование в качестве меры длины документа максимальной TF среди всех лемм документа ухудшает результат.
Помимо учета количества слов в документе можно учитывать html-форматирование и позицию слова в документе. Мы учитываем это в виде отдельного слагаемого. Учитывается наличие слова в первом предложении, во втором предложении, внутри выделяющих html тегов.
Пара учитывается, когда слова запроса встречаются в тексте подряд (+1), через слово (+0.5) или в обратном порядке (+0.5). Плюс еще специальный случай, когда слова, идущие в запросе через одно, в тексте встречаются подряд (+0.1).
На 2010 год, по словам Дена Расковалова, в Яндексе учитывалось более 420 факторов ранжирования, а приведенные выше – это только малая часть из них.
Модифицированная формула BM25F
Все указанные достоинства и недостатки TF-IDF подобных формул были учтены при создании действующих алгоритмов ранжирования. В 2009 году Яндекс внедрил машинное обучение Матрикснет. Научился понимать морфологию запроса, учитывать наличие синонимов (тезаурусов) в документе, регулярно внедряет новые технологии для улучшения качества поиска. Сегодня релевантность определяется отдельно для зон документа, а за неестественное или чрезмерное количество ключей благополучно накладываются текстовые пост-фильтры. Границы текстовой переоптимизации могут довольно часто сдвигаться, причем независимо для каждой зоны документа. Сегодня документ попал в «зеленую зону» и вы в ТОПе, завтра границы сдвинулись и вы вылетели. BM25 field (BM25F) – функция расчета релевантности по зонам документа:
Для оценки влияния ссылочных факторов существуют отдельные функции: LF-IDF, LinkBM25. Современная SEO-оптимизация – это непрерывные эксперименты с количеством вхождений, словоформой, положением ключевых слов в документе и т.п. Знание и понимание таких основ текстового ранжирования, как TF-IDF, BM25 существенно облегчают жизнь оптимизатора, внося долю ясности в непознанный мир Платонов Щукиных.



