Question: Q: blob_storage | GPUcache
I have two folders on my HD that I want to delete.
iMac 27″, macOS 10.14
Posted on Apr 5, 2019 12:19 AM
All replies
Loading page content
Page content loaded
On Blob, are you using any of this.
On GPU cache, are youn using Maya or such?
Apr 5, 2019 11:57 AM
No, I use none of those.
Apr 18, 2019 1:03 AM
blob storage = Microsoft Azure Storage Explorer // or Gladinet Cloud Desktop // or a driver to emulate HFS
Apr 18, 2019 2:07 AM
Thanks, looks like they shouldn’t delete them. 🙂
Apr 18, 2019 8:11 AM
What I can add is in my testing, each folder is instantly re-created at user log-in (after being deleted). This stuff only started happening in the past week or two. No autodesk software of any kind has ever been run on my system. No updates to ANY M$ software has been made in months and months. I HAVE recently installed DropBox, but that was AFTER I started noticing these 2 folders appear in my HD root. Yes, I do have some Adobe software (and I am about to delete Reader because it is constantly calling out to maybe half a dozen different servers), but again, none has had any updates in a long while.
Can’t consider this any kind of finished issue.
Whoops, just noticed this is in a Mohave forum, forgive but I can not install Mohave as I have a GTX 980 video card. So it looks like it isn’t specific to any specific OS as I’m running Sierra right now.
Well, Sierra is a lot easier to live with than later OS versions.
And I don’t want a degree in computer science to find out why this is happening.
Thanks for any response.
May 10, 2019 7:21 AM
Indeed, BTW, it seems you know Tiapriestess over @ WoW (had some nice things to say about you)! There are things that worked 100% reliably back in the OS9 days that are broken, but that’s a whole ‘nother story.
May 10, 2019 7:33 AM
Jay, over on another forum I have a long thread going about this. First, both seem attributable to adobe, and apparently are an issue on the M$ side. Was told there ay be solutions there, but not for Mac users. The oddity is that I simply do NOT have much of any adobe software anymore (an old version of Photoshop and Reader). There has been no updates to Photoshop in years and the last update I remember to Reader was quite a while ago. As the appearance of these folders is very recent, there has to be some adobe process running causing them, not necessarily tied to their software.
Now I kinda doubt either or them is really going to cause any kind of damage, BUT it really is the principle of the thing. It sure appears adobe is working surreptitiously behind our backs. Sure one COULD ask over on their forums, but I have had other issues AND posted there AND gotten zip for any response. so clearly Mac-hostile. Must be time to purge anything and everything from adobe. although I’d sure like to still has access to Photoshop, I’ve spent a LOT of money keeping it updated for so many years.
Хранение архива изображений для сайта в Azure BLOB storage
В статье рассказано про опыт организации бюджетного хранения архива изображений для сайта с миллионами объявлений.

Под изображениями в моем случае понимаются фотографии квартир, домов, участков и т.д. У меня есть собственный проект который представляет из себя сайт с объявлениями о продаже и аренде недвижимости. Сайту уже что-то около 6 лет и за это время скопилось достаточно большое количество объявлений. На каждой карточке объекта отображаются фотографии, в среднем 8 фотографий на объявление. Собственно эти фотографии я и собираюсь хранить в облаке чтобы потом показывать их посетителям на карточках объектов.
Как я хранил их раньше? — никак. Я не хранил у себя изображения кроме тех которые были размещены вручную. В большинстве же случаев объявления попадают на сайт через партнеров посредством автоматической загрузки фида. В фиде для каждого объекта есть ссылки на фотографии — вот ссылки я и храню, и отдаю посетителю фотографию напрямую от партнера. Эта схема прекрасно работает и экономит кучу ресурсов.
Фотографии которые видят посетители в подборке объявлений или в карточке объекта на самом деле подгружаются со сторонних ресурсов.
Есть один нюанс связанный со спецификой сайта — архивные объекты не удаляются никогда. Т.е. после того как объявление снято с публикации, оно конечно пропадает из поисковой выдачи, но по прямой ссылке доступно всегда (без контактов продавца). Какое-то время ссылки на фотографии еще живут, бывает что годами, но рано или поздно они умирают. Архивные объекты имеют ценность потому что на них продолжают приходить посетители из поисковых систем. Также по архиву строится карта цен (я уже писал про нее), а еще я случайно открыл дополнительный источник дохода для проекта в виде продажи контактных данных архивных объектов. Зачем они их покупают — я точно не знаю, но предполагаю, что посетители хотят получить контакты потому что думают что объявление снято с публикации случайно или по ошибке. Также наверное бывает что хотят узнать что-то у предыдущих владельцев. Так или иначе, объявление с фотографиями в данном случае имеет больше шансов на то чтобы быть купленным. Ценность фотографий возрастает после осознания этого нюанса.
Объемы данных которые я собираюсь хранить в облаке составляют около 3-4 терабайт. Плюс ежедневный прирост в несколько гигабайт. Учитывая что напрямую данное нововведение денег не принесет, а лишь косвенно может повлиять на принятие решения посетителем, бюджет в который я хотел уложиться очень скромный — это 1000-2000 р. в месяц. Хорошо бы вообще бесплатно, но такой возможности я не нашел.
Azure
Azure предлагает BLOB-storage с тремя уровнями хранилища: Hot, Cool и Archive. Цены на всех уровнях разные. В общих словах, чем горячее — тем дешевле чтение\запись и дороже ежемесячная плата за хранение, и наоборот. На Hot — выгодно много писать\читать и удалять, но дорого долго хранить. А на Archive дешево хранить но дорого читать\писать. Также на архивном и холодном уровнях есть плата за раннее удаление — это означает что если я удаляю (или перевожу на другой уровень) объект раньше чем определенный срок, то с меня все-равно возьмут плату как за весь этот срок. Для архивного уровня — это 180 дней, для холодного — 30.
Я сравнил со стоимостью в Amazon и Google, получается что в Azure дешевле.
| Azure | Amazon (S3) | ||
| Hot | $0.0196 | $0.024 | $0.026 |
| Cool | $0.01 | $0.01 | $0.01 |
| Archive | $0.0023 | $0.0045 | $0.007 |
Помимо стоимости хранения необходимо учитывать стоимость операций — они тоже на всех уровнях разные. Цены приводятся за 10 000 операций.
Логика работы
Пока объявление активно, фотографии в нем отображаются по ссылкам со сторонних ресурсов (от партнеров). После снятия объявления с публикации, оно становится архивным, но ссылки на фотографии еще какое-то время живы. Рано или поздно они умирают, и нужно позаботиться чтобы к этому времени была в наличии архивная копия.
Процесс обработки фотографий можно описать следующими шагами:
Первый запуск
Когда процесс был написан и протестирован, настало время опытной эксплуатации, и тут ожидаемо возникли неприятности. В очереди на тот момент было около 10 миллионов объектов, я решил начать миграцию с 30 000 объектов в день. Настроил красивые графики на дашборде и стал наблюдать. В статистике я увидел странные “выпады” с запросами GetBlobProperties. Они происходят с примерно равным интервалом в один час, начинаются всегда спустя примерно полтора часа после запуска миграции, и длятся еще какое-то время после ее завершения.
Количество таких запросов было слишком большим чтобы не обращать на них внимание. Я смотрел логи и видел что эти запросы идут не от моего сервера а с иностранных IP-адресов. Платить за них мне совсем не хотелось.
Я искал на стэке и в документации, но безрезультатно. Написал вопрос на Stackoverflow и в техподдержку. В итоге после длительной переписки с техподдержкой, и предоставления им логов, они мне сообщили что могут воспроизвести ситуацию и это баг на их стороне.
Интересный нюанс, что на мой вопрос на Stackoverflow был дан ответ не объясняющий причин, а только подтверждающий что я буду платить за эти запросы, но человек давший ответ настойчиво просил чтобы я пометил его как правильный. Он также вскользь намекнул мне что у них (в поддержке) не приветствуется распространяться об ошибках в собственных продуктах. Я дал ему понять что не сделаю этого пока он не напишет правду. Я мог бы написать это сам, но подумал что у сотрудников техподдержки наверняка результативность измеряется в том числе и количеством подтвержденных ответов, так что я предложил ему написать истинную причину и в этом случае отмечу его ответ как правильный. После недолгих колебаний, он согласился и дополнил свой комментарий сообщением о баге. В целом мне понравилось как работает техподдержка — меня даже перевели на русскую девушку которая до сих пор держит меня в курсе изменений по этой проблеме.
Факт признания бага меня удовлетворил только морально, но мне хотелось запустить механизм в работу, и при этом не платить деньги за левые запросы. Особенно учитывая что я нормально так заморочился чтобы максимально снизить количество запросов и тем самым стоимость.
В техподдержке мне посоветовали подождать с запуском а спустя пару недель написали что баг исправлен, но когда будет релиз с исправлением — неизвестно. Предложили включить логирование и работать так, а после релиза запросить компенсацию в Microsoft. Собственно, в таком режиме это пока и работает. Я ежедневно запускаю миграцию небольшого количества объектов и жду релиза.
Заключение
Стоимость ежедневных 30000 объектов обходится пока в 900 р. в месяц — и это вполне приемлемо. Большая часть расходов — это операции записи. Так что когда вся очередь будет обработана и наступит этап плановой работы, будет понятно какова реальная стоимость такого хранилища. Но по моим подсчетам это произойдет примерно через год.
Когда будет релиз в Azure Blob-storage я допишу здесь удалось ли получить компенсацию. Относительно ежемесячных трат — это около 10% стоимости.
Blob storage что это wow
На вкладке Основные выберите подписку, в которой будет создана учетная запись хранения.
Введите имя группы ресурсов и учетной записи.
Дождитесь окончания развертывания. Нажмите Перейти к ресурсу.
Загрузите файлы в контейнер
Чтобы войти в контейнер, нажмите на его имя.
Выберите файлы на компьютере.
Внимание. В имени файлов не должно быть пробелов. Файлы будут недоступны по ссылке.
Что такое хранилище BLOB-объектов Azure?
Хранилище BLOB-объектов Azure — это решение корпорации Майкрософт для хранения объектов в облаке. Хранилище BLOB-объектов оптимизировано для хранения огромных объемов неструктурированных данных. Неструктурированные данные — это данные, которые не соответствуют определенной модели данных или определению, например текстовых или двоичных данных.
Сведения об Azure Data Lake Storage 2-го поколения
Хранилище BLOB-объектов поддерживает Azure Data Lake Storage 2-го поколения, решение аналитики больших данных корпорации Майкрософт, предназначенное для облака. Azure Data Lake Storage 2-го поколения предлагает иерархическую файловую систему, а также преимущества хранилища BLOB-объектов:
Общие сведения об Azure Data Lake Storage 2-го поколения см. в этой статье.
Хранение архива изображений для сайта в Azure BLOB storage
В статье рассказано про опыт организации бюджетного хранения архива изображений для сайта с миллионами объявлений.

Под изображениями в моем случае понимаются фотографии квартир, домов, участков и т.д. У меня есть собственный проект который представляет из себя сайт с объявлениями о продаже и аренде недвижимости. Сайту уже что-то около 6 лет и за это время скопилось достаточно большое количество объявлений. На каждой карточке объекта отображаются фотографии, в среднем 8 фотографий на объявление. Собственно эти фотографии я и собираюсь хранить в облаке чтобы потом показывать их посетителям на карточках объектов.
Как я хранил их раньше? — никак. Я не хранил у себя изображения кроме тех которые были размещены вручную. В большинстве же случаев объявления попадают на сайт через партнеров посредством автоматической загрузки фида. В фиде для каждого объекта есть ссылки на фотографии — вот ссылки я и храню, и отдаю посетителю фотографию напрямую от партнера. Эта схема прекрасно работает и экономит кучу ресурсов.
Фотографии которые видят посетители в подборке объявлений или в карточке объекта на самом деле подгружаются со сторонних ресурсов.
Есть один нюанс связанный со спецификой сайта — архивные объекты не удаляются никогда. Т.е. после того как объявление снято с публикации, оно конечно пропадает из поисковой выдачи, но по прямой ссылке доступно всегда (без контактов продавца). Какое-то время ссылки на фотографии еще живут, бывает что годами, но рано или поздно они умирают. Архивные объекты имеют ценность потому что на них продолжают приходить посетители из поисковых систем. Также по архиву строится карта цен (я уже писал про нее), а еще я случайно открыл дополнительный источник дохода для проекта в виде продажи контактных данных архивных объектов. Зачем они их покупают — я точно не знаю, но предполагаю, что посетители хотят получить контакты потому что думают что объявление снято с публикации случайно или по ошибке. Также наверное бывает что хотят узнать что-то у предыдущих владельцев. Так или иначе, объявление с фотографиями в данном случае имеет больше шансов на то чтобы быть купленным. Ценность фотографий возрастает после осознания этого нюанса.
Объемы данных которые я собираюсь хранить в облаке составляют около 3-4 терабайт. Плюс ежедневный прирост в несколько гигабайт. Учитывая что напрямую данное нововведение денег не принесет, а лишь косвенно может повлиять на принятие решения посетителем, бюджет в который я хотел уложиться очень скромный — это 1000-2000 р. в месяц. Хорошо бы вообще бесплатно, но такой возможности я не нашел.
Скопируйте ссылки
Все ссылки на файлы создаются по одному шаблону.
Ссылка выглядит так:
Ссылка в папке выглядит так:
Чтобы быстро получить ссылки на другие файлы, скопируйте ссылку на один из них и подставьте вместо имена других загруженных файлов.
В TSV-файле с заданиями вставьте ссылки в столбец, который соответствует полю входных данных, куда надо передать эти данные.
Сведения о хранилище BLOB-объектов
Хранилище BLOB-объектов предназначено для следующих задач:
Заключение
Стоимость ежедневных 30000 объектов обходится пока в 900 р. в месяц — и это вполне приемлемо. Большая часть расходов — это операции записи. Так что когда вся очередь будет обработана и наступит этап плановой работы, будет понятно какова реальная стоимость такого хранилища. Но по моим подсчетам это произойдет примерно через год.
Когда будет релиз в Azure Blob-storage я допишу здесь удалось ли получить компенсацию. Относительно ежемесячных трат — это около 10% стоимости.
Логика работы
Пока объявление активно, фотографии в нем отображаются по ссылкам со сторонних ресурсов (от партнеров). После снятия объявления с публикации, оно становится архивным, но ссылки на фотографии еще какое-то время живы. Рано или поздно они умирают, и нужно позаботиться чтобы к этому времени была в наличии архивная копия.
Процесс обработки фотографий можно описать следующими шагами:
Создайте контейнер
Введите имя контейнера.
Windows Azure Blob-storage: поддержка CORS
Недавно вышло много обновлений Windows Azure. Среди них долгожданная поддержка Cross-Origin Resource Sharing для хранилищ. Я плотно использую в работе blob-storage (файловое хранилище) и в этом посте опишу как сделать загрузку файлов простой и приятной.
Чтобы начать работать с хранилищем (blob-storage) с помощью CORS, нужно решить следующие подзадачи:
1. Создать хранилище
2. Разрешить поддержку CORS
3. Создать временный ключ для записи (Shared Access Signature)
4. Написать загрузчик
Создание хранилища

После того, как хранилище будет создано нам потребуется его название, точка доступа и ключ доступа.


Теперь нужно сделать контейнер, его можно создать в портале или из кода.

Включение поддержки CORS для сервиса файлового хранилища
На каждый сервис хранилища (блоб, таблицы и очередь) можно создать до пяти CORS-правил. Для наших целей хватит и одного. У правила есть несколько свойств.
Разрешенные домены
Разрешенные заголовки
Если в запросе будут присутствовать заголовки не указанные в списке, он не пройдет. Для загрузки файлов нам потребуется два стандартных заголовка: accept и content-length, и специфичные для блобов: x-ms-blob-type, x-ms-blob-content-type и x-ms-blob-cache-control.
Разрешенные методы
Список методов, которые будут приниматься хранилищем. Для отправки файлов нужен метод PUT.
Срок жизни
Время, которое браузер должен кэшировать предварительный запрос (preflight request), из которого он узнает настройки CORS. Учитывая, что все успешные запросы к хранилищу тарифицируются, стоит его сделать достаточно большим.
Cors-правило
Подключение правила к сервису
Получение временного ключа.
С этим все тоже просто: ключ – это строка передаваемая в параметрах адреса при обращении к хранилищу. Действует в пределах объекта, на который дано разрешение. В нашем случае это будет контейнер. Формируется следующим способом:
Загрузчик
Теперь, после проведения всех подготовительных мероприятий, можно приступить к созданию загрузчика.
В Windows Azure имеются два типа блобов – блочные и страничные. Страничные оптимизированы для хранения потоковых данных (видео, аудио, т.п.) и режутся на страницы в 512 байт. Их максимальный размер – 1 Тб. В этом примере будут использоваться блочные блобы, с максимальным размером в 400Гб. Для загрузчика важно, что в одной операции загрузки он может передать не более 64Мб. Т.е. файл режется на блоки не превышающие 64Мб и финальной операцией блоки склеиваются. В примере файлы будут загружаться кусками по 512Кб.
Соответственно, алгоритм работы загрузчика будет следующим.
Логика загрузчика довольно простая, но, поскольку в нашем мире всё стало асинхронным, нужно быть внимательным.
Чтение файлов будем осуществлять с помощью нового и удобного FileReader.
Создадим для него обработчик, который по прочтению блока будет отправлять его в хранилище:
А так выглядит функция, собственно, чтения файла:
Когда чтение файла завершено и все блоки отправлены, нужно сообщить об этом хранилищу, чтобы оно склеило блоки.
На этом всё. Используя возможности CORS, теперь можно загружать файлы напрямую в хранилища, почти не привлекая свои сервера. И это хорошо: меньше делает сервер, меньше их надо, больше денег остается на всё остальное.
Первый запуск
Когда процесс был написан и протестирован, настало время опытной эксплуатации, и тут ожидаемо возникли неприятности. В очереди на тот момент было около 10 миллионов объектов, я решил начать миграцию с 30 000 объектов в день. Настроил красивые графики на дашборде и стал наблюдать. В статистике я увидел странные “выпады” с запросами GetBlobProperties. Они происходят с примерно равным интервалом в один час, начинаются всегда спустя примерно полтора часа после запуска миграции, и длятся еще какое-то время после ее завершения.

Количество таких запросов было слишком большим чтобы не обращать на них внимание. Я смотрел логи и видел что эти запросы идут не от моего сервера а с иностранных IP-адресов. Платить за них мне совсем не хотелось.
Я искал на стэке и в документации, но безрезультатно. Написал вопрос на Stackoverflow и в техподдержку. В итоге после длительной переписки с техподдержкой, и предоставления им логов, они мне сообщили что могут воспроизвести ситуацию и это баг на их стороне.
Факт признания бага меня удовлетворил только морально, но мне хотелось запустить механизм в работу, и при этом не платить деньги за левые запросы. Особенно учитывая что я нормально так заморочился чтобы максимально снизить количество запросов и тем самым стоимость.
В техподдержке мне посоветовали подождать с запуском а спустя пару недель написали что баг исправлен, но когда будет релиз с исправлением — неизвестно. Предложили включить логирование и работать так, а после релиза запросить компенсацию в Microsoft. Собственно, в таком режиме это пока и работает. Я ежедневно запускаю миграцию небольшого количества объектов и жду релиза.
Azure
Azure предлагает BLOB-storage с тремя уровнями хранилища: Hot, Cool и Archive. Цены на всех уровнях разные. В общих словах, чем горячее — тем дешевле чтение\запись и дороже ежемесячная плата за хранение, и наоборот. На Hot — выгодно много писать\читать и удалять, но дорого долго хранить. А на Archive дешево хранить но дорого читать\писать. Также на архивном и холодном уровнях есть плата за раннее удаление — это означает что если я удаляю (или перевожу на другой уровень) объект раньше чем определенный срок, то с меня все-равно возьмут плату как за весь этот срок. Для архивного уровня — это 180 дней, для холодного — 30.
Я сравнил со стоимостью в Amazon и Google, получается что в Azure дешевле.
| Azure | Amazon (S3) | ||
| Hot | $0.0196 | $0.024 | $0.026 |
| Cool | $0.01 | $0.01 | $0.01 |
| Archive | $0.0023 | $0.0045 | $0.007 |
Помимо стоимости хранения необходимо учитывать стоимость операций — они тоже на всех уровнях разные. Цены приводятся за 10 000 операций.
Azure: Blob storage
Blob Storage в Azure – это сервис, позволяющий хранить неструктурированные данные в облаке, обеспечивая простой доступ к ним из любого ресурса Azure – VM, Wep App и т.д. Кроме того – к любому ресурсу (блобу) в хранилище можно получить доступ по HTTP/HTTPS, используя Access keys.
Структура хралилища состоит из трех основных компонентов:
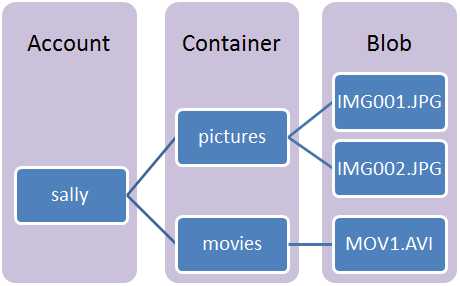
Подробнее о типах можно почитать тут>>>.
Правила имен в хранилищах
Вы сможете получить доступ к хранилищу с помощью URL примерно такого вида:
Правила имен контейнеров
Правила имен блобов
Создание Blob аккаунта
Перед тем, как создавать аккаунт – необходимо выбрать его тип.
Azure предлагает несколько типов, которые различаются типом репликации – LRS, ZRS, GRS, RAGRS, PLRS. Подробнее можно почитать тут>>>, а мы используем тип по умолчанию – RAGRS.
Кроме того – важно обращать внимание на локацию, в которой создается хранилище: на его основе будет выбрана вторичная локация, в которую будет выполняться репликация.
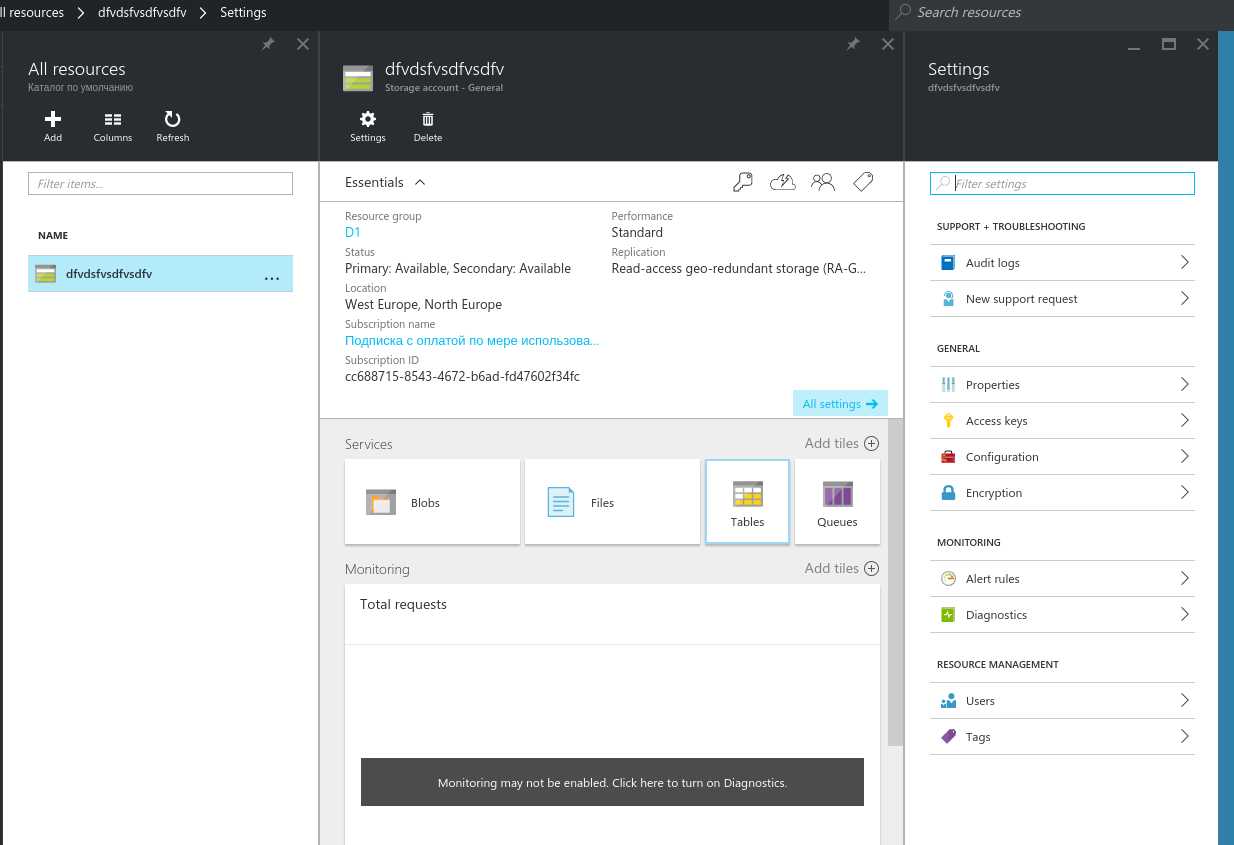
Из Azure Portal
Из Azure Portal можно создать аккаунт, перейдя в New > Data + Storage > Storage account:


C помощью Azure CLI
Находим нужную подписку и переключаемся на нее:
Примечание: Люблю Azure. Подписка 97214f99-*, которая в CLI отображается как “Free Trial” – на самом деле Pay-As-You-Go. Почему так отображается – непонятно.
Создаем группу ресурсов:
Создаем аккаунт хранилища:
Для дальнейшей работы – потребуется Access key:
Ключи генерируются автоматически при создании аккаунта. Вторичный ключ создается для того, что бы пользователь имел возможность обновить их, не прерывая работу приложений. Подробнее – тут>>>.
Теперь, используя ключ или строку подключения – можно задать одну из двух переменных окружения.
При использовании Access key:
При использовании Connection string:
А в переменной AZURE_STORAGE_ACCOUNT можно указать имя аккаунта, что бы не указывать его каждый раз вручную.
Создание контейнеров и блобов
Добавляем контейнер, в котором будем хранить объекты:
Открываем общий доступ:
Загрузим файл в контейнер:
в документации есть, но на деле у меня приводит к ошибке:
Можно загрузить объект из контейнера на локальную машину с помощью azure storage blob download :
А удалить объект – с помощью azure storage blob delete :



