Принципы работы протокола BGP
Сегодня мы рассмотрим протокол BGP. Не будем долго говорить зачем он и почему он используется как единственный протокол. Довольно много информации есть на этот счет, например тут.
Итак, что такое BGP? BGP — это протокол динамической маршрутизации, являющийся единственным EGP( External Gateway Protocol) протоколом. Данный протокол используется для построения маршрутизации в интернете. Рассмотрим как строится соседство между двумя маршрутизаторами BGP.
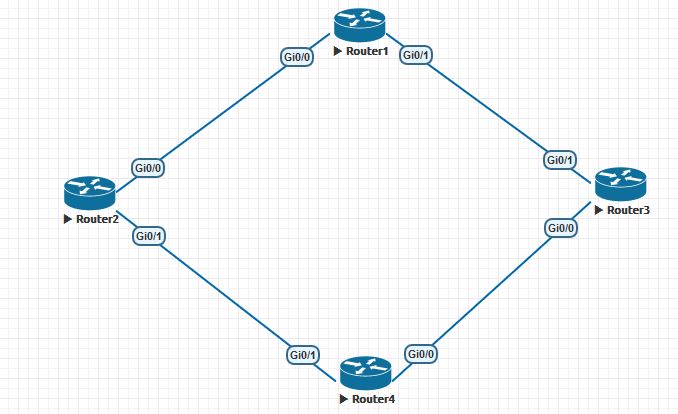
Рассмотрим соседство между Router1 и Router3. Настроим их при помощи следующих команд:
Соседство внутри одной автономной системы — AS 10. После ввода данных на маршрутизаторе, например на Router1, данный маршрутизатор пытается настроить отношения соседства с маршрутизатором Router3. Начальное состояние, когда ничего не происходит называется Idle. Как только будет настроен bgp на Router1, он начнет слушать TCP порт 179 — перейдет в состояние Connect, а когда пытается открыть сессию с Router3, то перейдет в состояние Active.
После того, как сессия установится между Router1 и Router3, то происходит обмен Open сообщениями. Когда данное сообщение отправит Router1, то данное состояние будет называться Open Sent. А когда получит Open сообщение от Router3, то перейдет в состояние Open Confirm. Рассмотрим более подробно сообщение Open:

В данном сообщение передается информация о самом протоколе BGP, который использует маршрутизатор. Обмениваясь Open сообщениями, Router1 и Router3 сообщают друг другу информацию о своих настройках. Передаются следующие параметры:
Для установления соседства необходимо выполнения следующих условий:
Здесь указывают сети, о которых сообщает Router1 и Path attributes, которые являются аналогом метрик. О Path attributes мы поговорим более подробно. Также внутри TCP сессии передаются Keepalive сообщения. Они передаются, по умолчанию, каждые 60 секунд. Это Keepalive Timer. Если в течении Hold Timer-а не будет получено Keepalive сообщение, то это будет означать потерю связи с соседом. По умолчанию, он равен — 180 секундам.
Вроде бы разобрались как маршрутизаторы передают друг другу информацию, теперь попытаемся разобраться с логикой работы протокола BGP.
Чтобы анонсировать какой-нибудь маршрут в таблицу BGP, как и в протоколах IGP, используется команда network, но логика работы отличается. Если в IGP, после указание маршрута в команде network, IGP смотрит — какие интерфейсы принадлежат данной подсети и включает их в свою таблицу, то команда network в BGP смотрит в таблицу маршрутизации и ищет точное совпадение с маршрутом в команде network. При нахождении таких, данные маршруты попадут в таблицу BGP.
Look for a route in the router’s current IP routing table that exactly matches the parameters of the network command; if the IP route exists, put the equivalent NLRI into the local BGP table.
Теперь поднимем BGP на всех оставшихся и посмотрим как происходит выбор маршрута внутри одной AS. После того, как BGP маршрутизатор получит маршруты от соседа, то начинается выбор оптимального маршрута. Здесь надо понять какого вида соседи могут быть — внутренние и внешние. Маршрутизатор по конфигурации понимает является ли сконфигурированный сосед внутренним или внешним. Если в команде:
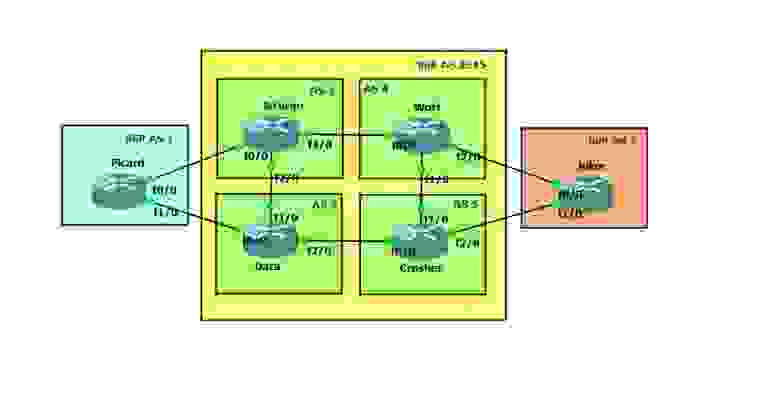
в качестве параметра remote-as указан AS, который сконфигурирован на самом маршрутизаторе в команде router bgp 10. Маршруты, пришедшие из внутренней AS считаются внутренними, а маршруты из внешней соответственно внешними. И по отношению к каждому работает разная логика получения и отправки. Рассмотрим такую топологию:

На каждом маршрутизаторы настроен loopback интрефейс с ip: x.x.x.x 255.255.255.0 — где x номер маршрутизатора. На Router9 у нас есть loopback интерфейс с адресом — 9.9.9.9 255.255.255.0. Его мы будем анонсировать по BGP и посмотрим как он распространяется. Данный маршрут будет передан на Router8 и Router12. С Router8 данный маршрут попадет на Router6, но на Router5 в таблице маршрутизации его не будет. Также и на Router12 данный маршрут попадет в таблицу, но на Router11 его также не будет. Попытаемся разобраться с этим. Рассмотрим какие данные и параметры передается Router9 своим соседям, сообщая об этом маршруте. Пакет внизу будет отправлен с Router9 на Router8.

Информация о маршруте состоит из аттрибутов пути (Path attributes).
Атрибуты пути разделены на 4 категории:
Атрибут Origin — указывает на то, каким образом был получен маршрут в обновлении. Возможные значения атрибута:
Далее, Next-hop. Атрибут Next-hop
Теперь Router6 передал маршрут Router5 и первому правилу Next-hop не изменил. То есть, Router5 должен добавить 9.9.9.0 [20/0] via 192.168.68.8, но у него нет маршрута до 192.168.68.8 и поэтому данный маршрут добавлен не будет, хотя информация о данном маршруте будет храниться в таблице BGP:
Та же самая ситуация произойдет и между Router11-Router12. Чтоб избежать такой ситуации необходимо настроить, чтоб Router6 или Router12, передавая маршрут своим внутренним соседям, подставляли в качестве Next-hop свой ip адрес. Делается при помощи команды:
После данной команды, Router6 отправит Update сообщение, где для маршрутов в качества Next-hop будет указан ip интерфейса Gi0/0 Router6 — 192.168.56.6, после чего данный маршрут уже попадет в таблицу маршрутизации.
Пойдем дальше и посмотрим появиться ли этот маршрут на Router7 и Router10. В таблице маршрутизации его не окажется и мы могли бы подумать, что проблема как в первом с параметром Next-hop, но если мы посмотрим вывод команды show ip bgp, то увидим, что там маршрут не был получен даже с неправильным Next-hop, что означает, что маршрут даже не передавался. И это нас приведет к существованию еще одного правила:
Маршруты, полученные от внутренних соседей не передаются другим внутренним соседям.
Так как, Router5 получил маршрут от Router6, то другому своему внутреннему соседу он передаваться не будет. Для того, чтобы передача произошла необходимо настроить функцию Route Reflector, либо настроить полносвязные отношения соседства ( Full Mesh), то есть Router5-7 каждый будет соседом с каждым. Мы будем в данном случае использовать Route Reflector. На Router5 необходимо использовать данную команду:
Route-Reflector меняет поведение BGP при передаче маршрута внутреннему соседу. Если внутренний сосед указан как route-reflector-client, то данным клиентам будут анонсироваться внутренние маршруты.
Маршрут не появился на Router7? Не забываем также и про Next-hop. После данных манипуляций маршрут должен и на Router7, но этого не происходит. Это нас подводит к еще одному правилу:
Правило next-hop работает только для External маршрутов. Для внутренних маршрутов замена атрибута next-hop не происходит.
И мы получаем ситуацию, в которой необходимо создать среду при помощи статичной маршрутизации или протоколов IGP сообщить маршрутизаторам о всех маршрутах внутри AS. Пропишем статические маршруты на Router6 и Router7 и после этого получим нужный маршрут в таблице маршрутизаторе. В AS 678 же мы поступим немного иначе — пропишем статические маршруты для 192.168.112.0/24 на Router10 и 192.168.110.0/24 на Router12. Далее, установим отношения соседства между Router10 и Router12. Также настроим на Router12 отправку своего next-hop для Router10:
Итогом будет то, что Router10 будет получать маршрут 9.9.9.0/24, он будет получен и от Router7 и от Router12. Посмотрим какой выбор сделает Router10:
Как мы видим, два маршрута и стрелка ( > ) означает, что выбран маршрут через 192.168.112.12.
Посмотрим как происходит процесс выбора маршрута:
Теперь все маршруты от данного соседа будут иметь такой вес. Посмотрим как изменится выбор маршрута после данной манипуляции:
Но как видим один маршрут через Router6. А где же маршрут через Router7? Может и на Router7 его нет? Смотрим:
Странно, вроде все в порядке. Почему же он не передается на Router5? Все дело в том, что у BGP есть правило:
Маршрутизатор передает только те маршруты, которые использует сам.
Router7 используется маршрут через Router5, поэтому маршрут через Router10 передаваться не будет. Вернемся к Local Preference. Давайте зададим Local Preference на Router7 и посмотрим как отреагирует на это Router5:
Итак, мы создали route-map, в который попадаются все маршруты и сказали Router7, чтоб при получение он менял параметр Local Preference на 250, по умолчанию равен 100. Смотрим, что произошло на Router5:
Посмотрим, что произойдет, если допустим Router6 потеряет маршрут 9.9.9.0/24 через Router9. Отключим интерфейс Gi0/1 Router6, который сразу поймет, что BGP сессия с Router8 оборвана и сосед пропал, а значит и маршрут, полученные от него не действительны. Router6 сразу отправляет Update сообщения, где указывает сеть 9.9.9.0/24 в поле Withdrawn Routes. Как только Router5 получит подобное сообщение, отправит его к Router7. Но так как у Router7 есть маршрут через Router10, то в ответ сразу отправит Update c новым маршрутом. Если детектировать падения соседа по состоянию интерфейса не получается, то придеться ждать срабатывания Hold Timer-а.
Если помните, то мы говорили о том, что часто приходится использовать полносвязную топологию. С большим количеством маршрутизаторов в одной AS это может доставить большие проблемы, чтоб избежать этого необходимо использовать конфедерации. Одна AS разбивается на несколько sub-AS, что позволяет работать им без требования полносвязной топологии.
Здесь ссылка на данную лабу, а тут конфигурация для GNS3.
Пришлось бы настраивать Route-Reflector или полносвязые отношения соседства. Разбивая одну AS 2345 на 4 sub-AS ( 2,3,4,5) для каждого маршрутизатора, мы в итоге получаем другую логику работы. Все отлично описано здесь.
102 IX: как мы подключили больше ста точек обмена трафиком и автоматизируем пиринг
Качественный BGP-пиринг — одна из главных причин хорошей связности глобальной сети G-Core Labs, охватывающей пять континентов. Мы присутствуем уже на 102 точках обмена трафиком, работаем с 5000 партнёрами по пирингу и входим в топ-10 сетей мира по количеству прямых пирингов. О том, как нам это удаётся — под катом.

Что такое BGP-пиринг
BGP-пиринг — это обмен интернет-трафиком между автономными системами (AS) напрямую, в обход вышестоящих операторов связи (аплинков).
Он помогает участникам точки обмена трафиком (IX, Internet Exchange) сокращать маршруты передачи данных между сетями, снижать затраты на трафик, а также в большинстве случаев и время отклика (RTT). Через точку обмена трафиком проще соединиться сразу c несколькими участниками: вместо отдельного коннекта к каждому достаточно одного соединения с IX, где все эти участники присутствуют.
Каждый участник IX выигрывает за счёт экономии на каналах и закупке трафика у аплинков. Это выгодно и для конечного пользователя: сокращаются сетевые задержки и время отклика до ресурсов.
Таким образом, чем больше точек обмена трафиком, тем лучше связность интернета и тем он доступнее.
Первые точки обмена трафиком начали появляться с 1994 года в крупных европейских городах: Лондоне (LINX), Франкфурте (DE-CIX), Амстердаме (AMS-IX), Москве (MSK-IX). Сейчас во всём мире работает более 500 IX
 Internet Exchange Map
Internet Exchange Map
Как мы выбираем дата-центры и точки обмена трафиком
Мы подбираем дата-центры по количеству операторов первого (Tier1) и второго (Tier2) уровней и локальных IX.
Публичный пиринг. Выбираем ведущих интернет-провайдеров в каждом регионе и стыкуемся с ними в крупнейших точках обмена трафиком.
Приватный пиринг. У нас более 5000 партнёров по пирингу по всему миру. Это позволяет сохранять локальность трафика в разных регионах, сокращая задержки доставки контента между сетями.
Подробней о нашей сетевой архитектуре можно узнать тут.
Почему пиринг требует нестандартных решений
BGP-пиринг — это не просто наше присутствие на отдельно взятой точке обмена трафика. Здесь требуются комплексный подход и слаженная работа всех команд.
Быть участником IX недостаточно, так как многие eyeball-операторы связи имеют закрытую пиринговую политику (например, Selective или Restrictive). Это означает, что оператор не отдаёт свои сети на Route Server (сетевой сервис, позволяющий упростить пиринговое взаимодействие между участниками IX и сократить количество индивидуальных администрируемых пиринговых сессий).
Поднятие пирингов с такими операторами — это результат долгих переговоров между пиринг-менеджерами, в результате которых появляется сам BGP-пиринг и обмен трафиком происходит напрямую.
Немалую роль здесь играет и автоматизация самого процесса по конфигурации. Когда количество точек обмена трафиком переваливает за 15, а общее количество пиров за 1000, управлять этим вручную силами инженеров становится невозможно. Поэтому мы разработали полностью автоматизированный цикл настройки и управления BGP-сессиями без участия человека. Сетевому инженеру остаётся лишь согласовать пиринг, остальное делает автоматика.
Почему мы не стали использовать готовые решения по автоматизации пиринга
Подходы к автоматизации пиринга от большой четвёрки глобальных операторов (Google, Microsoft, AWS, Cloudflare) нам не подошли.
Google и Microsoft используют Web Peering Portal, к которому непросто получить доступ. К тому же в случае Microsoft надо оформить минимальную подписку на Azure.
После получения доступа вам нужно заполнить информацию о себе (как об операторе), пройти верификацию и только потом получить возможность создавать запросы на пиринг. Для каждого запроса обычно создаётся отдельная задача, где также требуется заполнить информацию и внести (выбрать) параметры для BGP-сессии.
Как правило, на создание одного запроса может уходить до 10 минут. Теперь представим, что нам нужно сделать 200 таких запросов, чтобы поднять все нужные нам сессии по всему миру. И это только для одного оператора. Можно легко посчитать, сколько времени нужно затратить на такую задачу. И это без учёта времени ответа на письма, в которых могут быть дополнительные вопросы. Куда проще послать одно письмо из нескольких слов и в течение суток получить ответ уже с преднастроенной конфигурацией.
С какими проблемами пришлось столкнуться:
Человеческий фактор. Управлять конфигурацией в ручном режиме не представлялось возможным — одной из главных проблем стал бы человеческий фактор. Поскольку как бы ни был хорош сетевой инженер, в таких глобальных масштабах и он может допускать ошибки, которые могут приводить к простою сервиса.
Автоматизация. Мы разработали собственную систему автоматизации с нуля и постоянно её дорабатываем. Ведь важно не только настроить BGP-сессию, но и поддерживать дальнейшее оперирование. Например, по статистике ежедневно мы поднимаем более 40 сессий, а удаляем примерно 20. Если смотреть за месяц, то это примерно 1200 новых сессий и 600–800 удалённых.
Как автоматизирован наш пиринг сегодня
Достаточно послать запрос на noc@gcore.lu с темой Peering и номером ASN, отличным от нашей (199524).
Зачастую наши потенциальные пиринг-партнёры сами направляют запросы на организацию пиринга. Далее эти запросы попадают в оркестратор и система проводит анализ их целесообразности. Если запрос удовлетворяет нашим критериям, система автоматически настраивает соответствующие сессии и высылает конфигурацию участнику.
Мы предпочитаем настраивать пиринг на всех точках обмена трафиком, где у нас есть совпадения с оператором, который запросил пиринг. Такой подход экономит время и для нашего пиринг-партнёра, позволяя добиваться максимальной эффективности. По мере роста сети этот подход оказался самым удобным и для нас, и для партнёров.
Бывают и обратные ситуации, когда мы делаем запрос на пиринг с потенциально интересующим нас партнёром, как правило, с крупным оператором.
Как мы оцениваем целесообразность пиринга:
В первую очередь оценивается количество indirect-трафика (то есть трафика через наши upstream-каналы) за последние 30 дней.
Если значение выше порогового, то в оценку идут другие параметры, например, есть ли сети данного оператора на Route Server в полном составе.
Затем идёт выбор точек обмена трафика наиболее эффективных для нас.
Какие данные мы анализируем
Мы анализируем данные, которые собираются с наших пограничных маршрутизаторов посредством NetFlow/JFlow. Имея эти данные, мы знаем о своём трафике всё до последнего байта.
Как мы оцениваем эффективность пиринга и связность сети
Мы используем телеметрию с наших сервисов. Для этого у нас есть разные продукты, в том числе CDN, насчитывающая уже больше ста точек присутствия и входящая в топ-10 сетей доставки контента в Европе и Азии по данным CDNPerf.
Основные метрики, которые мы берём в расчёт со стороны сети, — это Packet Loss и Round-Trip Time до конечного пользователя.
На скольких IX мы присутствуем
Мы присутствуем уже на 102 точках обмена трафиком по всему миру. Это стало возможным благодаря мощной сетевой инфраструктуре, без которой пирингов быть не может. Ведь чтобы включить точку обмена трафиком нужно локальное присутствие, а это уже подразумевает наличие инфраструктуры, сетевого оборудования и каналов передачи данных.
Internet Exchange Participants Report (Hurricane Electric, август 2021)
Как мы планируем улучшать связность сети
Сейчас в приоритете страны Латинской Америки, Африки и Азии. Это потенциально очень большой и перспективный рынок, над которым мы работаем и будем продолжать работать.
Приглашаем к бесплатному пирингу
G-Core Labs — быстро развивающийся контент-оператор с собственной экосистемой облачных сервисов и глобальной инфраструктурой. В её развитии нам помогают технологии Intel: в апреле 2021 мы одними из первых начали интеграцию Intel Xeon Scalable 3-го поколения (Ice Lake) в серверную инфраструктуру своих облачных сервисов.
Мы сформировали обширную пиринговую сеть и придерживаемся открытой пиринговой политики. Сейчас мы приглашаем всех заинтересованных участников к бесплатному пирингу через точки обмена трафиком.
Фулвью ор нот фулвью: о пользе и вреде полной BGP-таблицы
На любом околосетевом форуме легко найти с десяток веток о выборе оборудования для BGP-пиринга с возможностью «держать две, три, пять, двадцать пять фулвью». Большинство таких веток выливается в холивары на тему Cisco vs. Juniper или еще чего похуже. Офлайновое же их развитие нередко напоминает мультфильм о шести шапках из одной овичины. В общем, бывает смешно.
И крайне редко обсуждается вопрос о необходимости этого самого фулвью.
Немножко «теории»
Не пугайтесь, я не стану рассказывать все с начала. Уверен, что большинству читателей хорошо известно содержимое моей теоретической вводной. Желающие могут смело ее пропустить. Однако же я регулярно сталкиваюсь с некоторой неуверенностью вполне компетентных в практических вопросах людей, когда речь заходит о нижеизлагаемом. Так что все-таки давайте немножко синхронизируем термины, прежде чем обсуждать матчасть.
Все, что впрямую не касается темы интернетной BGP-таблицы, в частности IGP, MPLS, VRF/VPN и т. п., оставим за скобками.
Роутинг и ричабилити
Фулвью — это практически справочник «Желтые страницы» для всего интернета. Только именно «Желтые страницы», а не ваша личная записная книжка. Принципиальная разница тут в том, что помимо разрешения букв в цифры — для чего в интернете служит не фулвью, а DNS — периодические справочники дают нам возможность знать о появлении и исчезновении объектов. Нужно же нам как-то узнавать, что тот или иной адрес вообще есть в интернете. Мало того, если вдруг он для нас доступен только через линк А, а через Б недоступен — мы ведь тоже хотим об этом знать. Это и есть сигнализация доступности (reachability). Не будем слишком глубоко в вдаваться в абстракции, отметим лишь важность осознавать, что ричабилити и роутинг суть разные вещи.
Роутинг (маршрутизация) — нахождение лучшего пути передачи трафика для заданного направления. Этот процесс мало похож на поиск в телефонном справочнике, а скорее имеет отношение к карте города: если один и тот же адрес x.x.x.x доступен нам и через линк А, и через линк Б, нужно принять решение, куда же посылать пакеты.
Предположим, что читатель знаком с протоколом IP и в курсе, что такое префикс, зачем ему длина, и с чем едят правило лонгест мач.
Итак, как видно из показанного выше знаменитого графика c bgp.potaroo.net, полная таблица интернет-маршрутизации (здесь и далее речь в основном об IPv4, хотя почти все кроме цифр справедливо также и для IPv6) нынче содержит почти 350 тысяч записей. Это число растет экспоненциально и довольно быстро. Каждая из записей представляет собой, собственно, маршрут: IP-префикс назначения (подсеть с маской), некстхоп (следующий узел aka «куда посылать») и разные там другие параметры, определяющие ценность этого маршрута. Когда есть два (полученных от разных маршрутизаторов-соседей) маршрута для одного префикса, в ход идут как раз эти атрибуты. Они определяют, какой некстхоп будет использован для передачи.
Здесь показаны три маршрута к префиксу 8.8.8.0/24, полученные от трех разных маршрутизаторов-соседей. По некоторой причине — кстати, в данном случае нетривиальной — первый из них был выбран наилучшим (в примере причина не показана). Пусть вас не смущает и то, что у всех трех маршрутов один и тот же некстхоп: данные сняты с весьма специфического маршрутизатора, не передающего транзитный трафик. И да, маршрутизатор-сосед и некстхоп — это не одно и то же.
Анонсируются маршруты между маршрутизаторами при помощи протокола BGP, который собой являет, ну, практически RSS-трансляцию (да простят меня теоретики за кощунственное сравнение). Собственно, термин Full View — популярен в основном у нас, иностранные коллеги чаще говорят Full BGP, Full Table или Full Feed.
То есть сам протокол ничего сложного из себя не представляет — просто способ автоматизированного обмена данными, обернутыми в лучших программистских традициях в нечто вроде контейнеров, которые стандарт протокола позволяет более-менее гибко расширять по мере необходимости. Механизмы поиска наилучшего пути (роутинга) и контроля связности (ричабилити) у него довольно просты, если не сказать примитивны. В частности BGP считает, что трафик передается не между маршрутизаторами, а между укрупненными сущностями: автономными системами (АС, произносится «а-эс») и почти ничего не знает об их внутренней структуре — путь через две транзитных АС, каждая из которых включает, скажем, десять внутренних хопов (маршрутизаторов), BGP сочтет более выгодным, чем путь через пять АС, каждая из которых внутри имеет два хопа. Кроме того, BGP практически ничего не знает о пропускной способности линков; в нашем приближении можно считать, что этот аспект вообще никак не учитывается при выборе маршрута.
По сравнению с другими протоколами он не слишком быстр в обнаружении изменений связности и, как мы только что убедились, далеко не всегда оптимально ищет лучшие пути. Однако это все — не только минус, но и плюс BGP, т. к. именно благодаря своей относительной прямолинейности и «укрупненности мазков» протокол хорошо приспособлен для передачи большого объема маршрутной информации.
Так вот таблица в 340 тысяч записей с кучей атрибутов — это довольно много. А таблиц таких нужно обычно не меньше двух («мэньше нэ былло смы-исла», но об этом потом). Одно лишь хранение всего этого добра требует многих сотен мегабайт памяти, а кроме передачи и держания в памяти, таблицы нужно «обсчитать», в результате чего получить набор наилучших (активных) маршрутов.
Например. Один маршрутизатор-сосед анонсировал нам, что он знает маршрут, скажем, к Гуглу, и другой сосед — тоже анонсировал. Теперь мы знаем, что Гугл доступен нам через каждого из соседей (ричабилити) и хотим принять решение, какой же из двух маршрутов использовать для передачи пакетов (роутинг). Для этого BGP сравнивает показания (разные атрибуты маршрутов: Local Preference, AS-PATH и другие) и принимает решение (по каким-то там, не имеющим сейчас значения критериям), что, допустим, через первого соседа лучше. И так для каждого префикса. Таким образом из нескольких таблиц (каждая из которых состоит из 340 тыс. записей), полученных от разных соседей, «компилируется» одна таблица на 340 тыс. активных маршрутов:
Или то же самое плюс IPv6 на Juniper:
Конструкция из нескольких еще необсчитанных BGP-фидов (если быть точнее, то не только их, но и данных других протоколов), называется RIB (routing information base). Хранится она как правило в самой обычной оперативной памяти и обрабатывается самым обычным процессором. Соответственно именно к этим двум элементам и предъявляются требования, когда речь идет о количестве полных BGP-таблиц, которые можно впихнуть в RIB. Общее количество записей тут определяется как сумма всех полученных от соседей маршрутов: две фулвью — почти 700 тыс. префиксов, три — за миллион и т. д.
Вывод первый. Грузить фулвью, если у вас только одна сессия с внешним миром — бессмыслица. Обладание этим массивом информации не даст ничего, кроме нагрузки на оборудование, т. к. трафик можно передать только одним способом: «Адам, это Ева, выбирай себе жену». Представьте, что Адам решил бы прежде проанализировать 340 тысяч параметров Евы — где бы мы теперь были? Из данного правила есть редкие исключения, однако если вы не знаете, какие именно, то они — точно не ваш случай.
Памяти под RIB с несколькими фулвью нужно не то чтобы прям очень много, но сотни мегабайт — единицы гигабайт (в зависимости от количества фулвью, реализации и массы других аспектов). Процессору подчас тоже приходится не очень сладко, особенно в реализациях, имеющих BGP-сканер. Например апдаун сессии, через которую передается полная таблица, на иных платформах может приводить к стопроцентной загрузке процессора где-нибудь на полчасика.
Однако же понятно, что гигабайты памяти и гигагерцы процессорной частоты давно перестали быть чем-то особенным. И даже в контексте сетевого оборудования, производители которого славятся умением продавать обычную, как в компьютере, DRAM по цене космических летательных аппаратов, делая вид, что 2 ГБ — вершина прогресса, приведенные цифры не так уж страшно выглядят. Участники упомянутых в начале топика форумных дискуссий довольно часто приходят именно к такому выводу. Мол, главное памяти побольше. Это утверждение, в общем, верно, но к сожалению на нем дело отнюдь не заканчивается.
Давайте посмотрим, что происходит с фулвью дальше. Но прежде еще одно маленькое, но очень важное замечание.
Маршрутная информация всегда передается навстречу трафику, который коммутируется на ее основе. То есть на базе фулвью передается исходящий из вашей АС трафик. Не смотря на всю очевидность этого тезиса, далеко не всегда практическое его значение осознается в полной мере.
Форвадинг
Дальше эта «скомпилированная» таблица активных маршрутов исп
ользуется для передачи трафика. Называется она FIB (forwarding information base), и количество записей в ней, грубо говоря, равно количеству записей в одной фулвью (340 тыс.). С ней все гораздо интереснее.
Лирическое отступление. Вообще говоря, Full View (в отличии от Full BGP Feed) — это как раз FIB. То есть в большинстве случаев правильнее было бы говорить не «мне нужен маршрутизатор, способный держать три фулвью», а «мне нужен маршрутизатор, способный держать три пира с фулвью».
И, кстати, подпись по оси ординат на великой и ужасной картинке, приведенной в начале поста, неправильная. Это не RIB, а FIB. Заголовок на внутренней странице об этом тоже какбе намекает.
Большинство современных маршрутизаторов, способных передавать трафик на скоростях от пары гигабит в секунду и выше, — «аппаратные». Аппаратность их в том, что FIB и ее атрибуты помещается не в обычную, а в специальную, грубо говоря, «быструю» коммутационную память (SRAM, TCAM, RLDRAM и пр.), к которой обращаются специальные же процессоры обработки пакетов. Эта память — едва ли не самый дорогой ресурс в маршрутизаторе. А возможная изощренность работы с ней — уж точно самый главный из факторов, влияющих на цену железа.
Есть также программные коробки (производительностью, грубо говоря, до гигабита-двух), у которых, соответственно, FIB, как и RIB, хранится в обычной оперативке. У них, вообще, частенько слишком много всего в ней хранится, но об этом как-нибудь в другой раз — главное, что она (оперативка) не резиновая. Мало того, программный поиск по массиву с нахождением наилучшего соответствия (longest match) — ну очевидно же, что тем медленнее, чем больше в массиве элементов, каким алгоритмом не ищи.



