Spring — Bean Post Processors
Интерфейс BeanPostProcessor определяет методы обратного вызова, которые вы можете реализовать, чтобы обеспечить собственную логику создания экземпляров, логику разрешения зависимостей и т. Д. Вы также можете реализовать некоторую настраиваемую логику после того, как контейнер Spring завершит создание, настройку и инициализацию компонента, подключив один или несколько Реализации BeanPostProcessor.
BeanPostProcessors работают с экземплярами компонента (или объекта), что означает, что контейнер Spring IoC создает экземпляр компонента, а затем интерфейсы BeanPostProcessor выполняют свою работу.
ApplicationContext автоматически обнаруживает любые bean-компоненты, определенные с помощью реализации интерфейса BeanPostProcessor, и регистрирует эти bean-компоненты как постпроцессоры, которые затем будут соответствующим образом вызываться контейнером при создании bean-компонента.
пример
В следующих примерах показано, как писать, регистрировать и использовать BeanPostProcessors в контексте ApplicationContext.
Давайте создадим рабочую среду Eclipse и предпримем следующие шаги для создания приложения Spring:
Вот содержимое файла HelloWorld.java —
Это очень простой пример реализации BeanPostProcessor, который печатает имя компонента до и после инициализации любого компонента. Вы можете реализовать более сложную логику до и после инициализации компонента, поскольку у вас есть доступ к объекту компонента внутри обоих методов постпроцессора.
Вот содержимое файла InitHelloWorld.java —
Ниже приведен файл конфигурации Beans.xml, необходимый для методов init и destroy:
Как только вы закончили создавать файлы конфигурации исходного кода и bean-компонента, давайте запустим приложение. Если с вашим приложением все в порядке, оно напечатает следующее сообщение:
Русские Блоги
Введение в Spring’s BeanPostProcessor (постпроцессор)
Чтобы прояснить структуру Spring, нам необходимо выяснить роль соответствующих основных интерфейсов соответственно.Эта статья знакомит с интерфейсом BeanPostProcessor.
BeanPostProcessor
Этот интерфейс также называется постпроцессором, и его функция заключается в добавлении нашей собственной логики до и после метода инициализации вызова дисплея после создания экземпляра объекта Bean и внедрения зависимости. Обратите внимание, что он запускается после создания экземпляра Bean и завершения внедрения зависимости. Исходный код интерфейса выглядит следующим образом
| метод | Описание |
|---|---|
| postProcessBeforeInitialization | Создание экземпляра и внедрение зависимости завершены, Перед вызовом отображаемой инициализации выполните некоторые индивидуальные задачи инициализации. |
| postProcessAfterInitialization | Выполнить, когда создание экземпляра, внедрение зависимостей и инициализация завершены |
1. Демонстрация пользовательского постпроцессора
1. Пользовательский процессор
заметка : Два метода в интерфейсе не могут возвращать null. Если он возвращает null, то последующий метод инициализации сообщит об исключении нулевого указателя или объект экземпляра bena не может быть получен с помощью метода getBean (), потому что постпроцессор извлекает объект экземпляра bean из контейнера Spring IoC Больше не помещать в контейнер IoC
2. класс Pojo
3. Регистрация файла конфигурации
4. Тест
С помощью оператора вывода мы также можем видеть, что оператор вывода метода postProcessBeforeInitialization выполняется после создания экземпляра bean-компонента и внедрения атрибута и выполняется перед пользовательским методом инициализации (указанным в init-method). Метод postProcessAfterInitialization выполняется после выполнения пользовательского метода инициализации.
Тестовый код выглядит следующим образом
Два, несколько постпроцессоров
Мы можем добавить несколько классов реализации интерфейса BeanPostProcessor (постпроцессор) в файл конфигурации Spring.По умолчанию контейнер Spring будет вызывать их последовательно в соответствии с порядком, в котором определены постпроцессоры.
В-третьих, отобразить указанный порядок
Результат тестового вывода
Чем выше значение, тем ниже приоритет, поэтому вывод A отстает.
Что ж, благодаря этой статье каждый должен лучше понять роль интерфейса BeanPostProcessor.
Интеллектуальная рекомендация
Gensim Skip-Gram модель для Word2Vec

Встраиваем VSCode в OpenCV IDE (C ++, window10 1803)
Каталог статей вступление окружение шаг 1. Конфигурация Visual Studio Code 2. Конфигурация OpenCV 3. Конфигурация MinGw 4. Конфигурация cmake 5. Конфигурация проекта 6. Ссылка на ссылку В конце концов.

Интеграция и инструменты fastDFS + spring + maven

Основы Linux
Пользователи Linux делятся на два типа: Пользователь суперадминистратора: root, хранится в каталоге / root Обычные пользователи: хранятся в каталоге / home Каталог Linux /: [*] Корневой каталог. Как п.
Spring изнутри. Этапы инициализации контекста

Доброго времени суток уважаемые хабравчане. Уже 3 года я работаю на проекте в котором мы используем Spring. Мне всегда было интересно разобраться с тем, как он устроен внутри. Я поискал статьи про внутреннее устройство Spring, но, к сожалению, ничего не нашел.
Всех, кого интересует внутреннее устройство Spring, прошу под кат.
На схеме изображены основные этапы поднятия ApplicationContext. В этом посте мы остановимся на каждом из этих этапов. Какой-то этап будет рассмотрен подробно, а какой-то будет описан в общих чертах.
1. Парсирование конфигурации и создание BeanDefinition
Цель первого этапа — это создание всех BeanDefinition. BeanDefinition — это специальный интерфейс, через который можно получить доступ к метаданным будущего бина. В зависимости от того, какая у вас конфигурация, будет использоваться тот или иной механизм парсирования конфигурации.
Xml конфигурация
Для Xml конфигурации используется класс — XmlBeanDefinitionReader, который реализует интерфейс BeanDefinitionReader. Тут все достаточно прозрачно. XmlBeanDefinitionReader получает InputStream и загружает Document через DefaultDocumentLoader. Далее обрабатывается каждый элемент документа и если он является бином, то создается BeanDefinition на основе заполненных данных (id, name, class, alias, init-method, destroy-method и др.). Каждый BeanDefinition помещается в Map. Map хранится в классе DefaultListableBeanFactory. В коде Map выглядит вот так.
Конфигурация через аннотации с указанием пакета для сканирования или JavaConfig
Конфигурация через аннотации с указанием пакета для сканирования или JavaConfig в корне отличается от конфигурации через xml. В обоих случаях используется класс AnnotationConfigApplicationContext.
Если заглянуть во внутрь AnnotationConfigApplicationContext, то можно увидеть два поля.
ClassPathBeanDefinitionScanner сканирует указанный пакет на наличие классов помеченных аннотацией @Component (или любой другой аннотацией которая включает в себя @Component). Найденные классы парсируются и для них создаются BeanDefinition.
Чтобы сканирование было запущено, в конфигурации должен быть указан пакет для сканирования.
Groovy конфигурация
Данная конфигурация очень похожа на конфигурацию через Xml, за исключением того, что в файле не XML, а Groovy. Чтением и парсированием groovy конфигурации занимается класс GroovyBeanDefinitionReader.
2. Настройка созданных BeanDefinition
После первого этапа у нас имеется Map, в котором хранятся BeanDefinition. Архитектура спринга построена таким образом, что у нас есть возможность повлиять на то, какими будут наши бины еще до их фактического создания, иначе говоря мы имеем доступ к метаданным класса. Для этого существует специальный интерфейс BeanFactoryPostProcessor, реализовав который, мы получаем доступ к созданным BeanDefinition и можем их изменять. В этом интерфейсе всего один метод.
Метод postProcessBeanFactory принимает параметром ConfigurableListableBeanFactory. Данная фабрика содержит много полезных методов, в том числе getBeanDefinitionNames, через который мы можем получить все BeanDefinitionNames, а уже потом по конкретному имени получить BeanDefinition для дальнейшей обработки метаданных.
Давайте разберем одну из родных реализаций интерфейса BeanFactoryPostProcessor. Обычно, настройки подключения к базе данных выносятся в отдельный property файл, потом при помощи PropertySourcesPlaceholderConfigurer они загружаются и делается inject этих значений в нужное поле. Так как inject делается по ключу, то до создания экземпляра бина нужно заменить этот ключ на само значение из property файла. Эта замена происходит в классе, который реализует интерфейс BeanFactoryPostProcessor. Название этого класса — PropertySourcesPlaceholderConfigurer. Весь этот процесс можно увидеть на рисунке ниже.
Давайте еще раз разберем что же у нас тут происходит. У нас имеется BeanDefinition для класса ClassName. Код класса приведен ниже.
Если PropertySourcesPlaceholderConfigurer не обработает этот BeanDefinition, то после создания экземпляра ClassName, в поле host проинжектится значение — «$
Соответственно в эти поля проинжектятся правильные значения.
Для того что бы PropertySourcesPlaceholderConfigurer был добавлен в цикл настройки созданных BeanDefinition, нужно сделать одно из следующих действий.
Для XML конфигурации.
PropertySourcesPlaceholderConfigurer обязательно должен быть объявлен как static. Без static у вас все будет работать до тех пор, пока вы не попробуете использовать @ Value внутри класса @Configuration.
3. Создание кастомных FactoryBean
На первый взгляд, тут все нормально и нет никаких проблем. А что делать если нужен другой цвет? Создать еще один бин? Не вопрос.
А что делать если я хочу каждый раз случайный цвет? Вот тут то и приходит на помощь интерфейс FactoryBean.
Создадим фабрику которая будет отвечать за создание всех бинов типа — Color.
Добавим ее в xml и удалим объявленные до этого бины типа — Color.
Теперь создание бина типа Color.class будет делегироваться ColorFactory, у которого при каждом создании нового бина будет вызываться метод getObject.
Для тех кто пользуется JavaConfig, этот интерфейс будет абсолютно бесполезен.
4. Создание экземпляров бинов
Созданием экземпляров бинов занимается BeanFactory при этом, если нужно, делегирует это кастомным FactoryBean. Экземпляры бинов создаются на основе ранее созданных BeanDefinition.
5. Настройка созданных бинов
Интерфейс BeanPostProcessor позволяет вклиниться в процесс настройки ваших бинов до того, как они попадут в контейнер. Интерфейс несет в себе несколько методов.
Процесс донастройки показан на рисунке ниже. Порядок в котором будут вызваны BeanPostProcessor не известен, но мы точно знаем что выполнены они будут последовательно.
Для того, что бы лучше понять для чего это нужно, давайте разберемся на каком-нибудь примере.
При разработке больших проектов, как правило, команда делится на несколько групп. Например первая группа разработчиков занимается написанием инфраструктуры проекта, а вторая группа, используя наработки первой группы, занимается написанием бизнес логики. Допустим второй группе понадобился функционал, который позволит в их бины инжектить некоторые значения, например случайные числа.
На первом этапе будет создана аннотация, которой будут помечаться поля класса, в которые нужно проинжектить значение.
По умолчанию, диапазон случайных числе будет от 0 до 10.
Затем, нужно создать обработчик этой аннотации, а именно реализацию BeanPostProcessor для обработки аннотации InjectRandomInt.
Код данного BeanPostProcessor достаточно прозрачен, поэтому мы не будем на нем останавливаться, но тут есть один важный момент.
BeanPostProcessor обязательно должен быть бином, поэтому мы его либо помечаем аннотацией @Component, либо регестрируем его в xml конфигурации как обычный бин.
Первая группа разработчиков свою задачу выполнила. Теперь вторая группа может использовать эти наработки.
В итоге, все бины типа MyBean, получаемые из контекста, будут создаваться с уже проинициализированными полями value1 и value2. Также тут стоить отметить, этап на котором будет происходить инжект значений в эти поля будет зависеть от того какой @ Scope у вашего бина. SCOPE_SINGLETON — инициализация произойдет один раз на этапе поднятия контекста. SCOPE_PROTOTYPE — инициализация будет выполняться каждый раз по запросу. Причем во втором случае ваш бин будет проходить через все BeanPostProcessor-ы что может значительно ударить по производительности.
Полный код программы вы можете найти тут.
Хочу сказать отдельное спасибо EvgenyBorisov. Благодаря его курсу, я решился на написание этого поста.
Также советую посмотреть его доклад с JPoint 2014.
Руководство по Spring. Интерфейс BeanPostProcessor.
Интерфейс BeanPostProcessor имеет всего два метода:
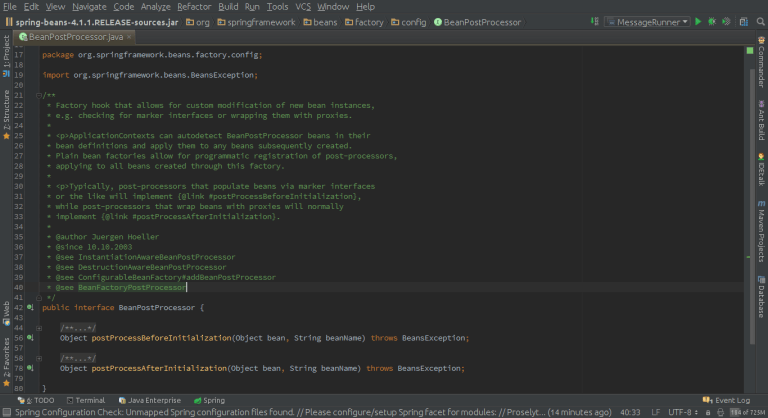
Они позволяют разработчику самому имплементировать некоторые методы бинов перед инициализацией и после уничтожения экземпляров бина.
Имеется возможность настраивать несколько имплементаций BeanPostProcessor, и определить порядок их выполнения.
Данный интерфейс работает с экземплярами бинов, а это означает, что Spring IoC создаёт экземпляр бина, а затем BeanPostProcessor с ним работает.
ApplicationContext автоматически обнаруживает любые бины, с реализацией BeanPostProcessor и помечает их как “post-processors” для того, чтобы создать их определённым способом.
Чтобы лучше понять, что это такое на практике, рассмотрим пример.
Пример:
Исходный код проекта можно скачать по ЭТОЙ ССЫЛКЕ.

Конфигурационный файл post-processor-config.xml

Результат работы программы:
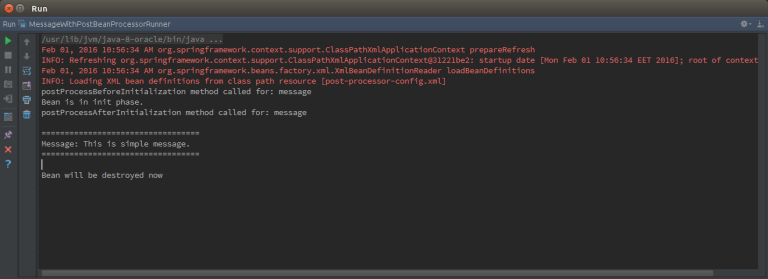
Сегодня мы изучили основы интерфейса PostBeanProcessor и написали простое приложение с использованием его имплементации.
Spring Boot + BeanPostProcessor или как обернуть ответ контроллеров часть 2
Введение
Вспоминаем, что готово на данный момент
Предлагаю вспомнить, что мы сделали в прошлой статье. Код на GitHub на ветке master.
Немного про то, что уже было создано
Мы создали стартер, в котором присутствует 2 аннотации: @DisableResponseWrapper и @EnableResponseWrapper, а также 2 интерфейса: IWrapperModel и IWrapperService, используя которые мы можем обернуть все необходимые ответы контроллеров в новый класс.
Для реализации такого функционала, в стартере мы создали класс, реализующий интерфейс ResponseBodyAdvice и аннотированный с помощью @ControllerAdvice(annotations = EnableResponseWrapper.class)
Аннотация @ControllerAdvice(annotations = EnableResponseWrapper.class) указывает, что методы данного компонента будут использоваться сразу несколькими контроллерами. Также указываем, что наши методы будут обрабатывать только те контроллеры, которые помечены @EnableResponseWrapper.
Класс реализует интерфейс ResponseBodyAdvice<>, который позволяет настраивать ответ, после его возвращения методом @ResponseBody или контроллером ResponseEntity, но до того, как тело будет записано с помощью HttpMessageConverter.
В классе необходимо было реализовать 2 метода:
— метод обработки точки входа контроллера. Вернуть в методе необходимо объект, который будет возвращен api.
Этот механизм мы положили в стартер и написали демо-проект под данный функционал.
Представленный в статье механизм возможно использовать и для иных задач, связанных с обработкой ответов контроллеров. Подобный подход используется для обработки исключений в контроллерах. (Хорошая статья об обработки исключений https://habr.com/ru/post/528116/)
С помощью использования ControllerAdvice+ResponseBodyAdvice и аннотаций вы можете более гибко настроить обработку любых ответов контроллеров с использованием большого количества информации о методе, контроллере, запросе и ответе контроллера.
Внедрение коллекции
Мы хотим в результате получить возможность реализовывать для каждого класса-обертки свой сервис.
Создадим аннотацию для сервисов:
В качестве аргумента будем принимать модель-обертку для дальнейшего получения по ней сервиса из списка.
Небольшие доработки
Сразу сделаем небольшие доработки по проекту для того, чтобы стартер был более гибким.
Добавим generic-и. Интерфейс модели:
Создаем функции-хелперы setBodyHelper и setDataHelper для того, чтобы иметь возможность работать с Wildcard. Подробнее про helper-методы и зачем они нужны можно прочесть в официальной документации.
Аналогично делаем для интерфейса сервиса:
Также для того, чтобы производить обертку на основе данных о запросе, создадим класс данных.
Изменяем ResponseWrapperAdvice
Таким образом spring самостоятельно найдет и соберет в список все классы, реализующие IWrapperService с любыми Body и Data.
Напишем метод получения из списка того сервиса, который относится к конкретно нашему классу-обертке.
С помощью iWrapperService.getClass().getAnnotations() получаем все аннотации для каждого из сервисов и ищем среди них аннотацию @WrapperService. Из нее получаем класс-обертку, которую сравниваем с той, с которой работаем сейчас сами.
Данный подход вполне оптимальный, но не лучший. Во-первых, метод getWrapperService будет вызываться каждый раз при запросе, в чем нет необходимости. Это можно поправить кешированием, например.
Во-вторых, как мне кажется, куда логичнее инжектить не список сервисов и затем по нему искать нужный перебором, а сразу мапу, в которой будет класс-обертка против сервиса.
Полный код проекта с реализацией через внедрение коллекций: GitHub
Немного теории
В спринге присутствуют следующие этапы инициализации контекста, в каждый из которых, при желании, можно вклиниться самому:
Хорошая и подробная статья про этапы инициализации контекста.
Реализация задачи через BeanPostProcessor
Во-первых, для удобства, нам понадобится новая аннотация, которая будет обозначать место для инжекта нашей мапы:
Во-вторых, нам нужен сам класс, реализующий BeanPostProcessor:
Из двух методов интерфейса нам понадобится только один. Выполнять наполнение полей будем до выполнения PostConstruct, тк метод, аннотированный PostConstruct считается инициализирующим, работющим тогда, когда все бины были подключены к классу.
Метод получения мапы класса обертки против сервиса:
Методы инжекта в метод и в переменную:
Вначале получаем все методы/поля класса и фильтруем их по наличию аннотации @InjectWrapperServiceMap.
Для методов вызываем выполнение метода, передавая в него мапу method.invoke(bean, getWrapperServiceMap());
Для поля обязательно устанавливаем доступность для того, чтобы могли в поле что-либо записывать и производим запись field.set(bean, getWrapperServiceMap());
Полный код InjectWrapperServiceMapBeanPostProcessor
Регестрируем BeanPostProcessor
В конфигурационном файле настройки бинов создаем новый бин:
К бину ResponseWrapperAdvice необходимо добавить @DependsOn(value = «responseWrapperBeanPostProcessor») для того, чтобы бин конфигурировался после создания бина BPP.
Для работы @DependsOn необходимо над классом конфигурации поставить аннотацию @ComponentScan(«ru.emilnasyrov.lib.response.wrapper»)
Полный код ResponseWrapperAutoConfiguration
Теперь аннотацию @InjectWrapperServiceMap для инжекта мапы сервисов можем использовать как в внутри нашего стартера, так и снаружи.
Дополняем обработчик контроллеров
В ResponseWrapperAdvice заинжектим мапу:
Используем ее в методе generateResponseWrapper следующим образом:
Полный код ResponseWrapperAdvice
В коде остается нерешенный момент с использованием одного сервиса для разных оберток, что предлагаю, при необходимости, реализовать вам самим. Мне кажется, это довольно редкий кейс и нет необходимости его рассматривать в рамках данной статьи.
А также инжект мапы через конструктор, который, думаю, я рассмотрю в последующих статьях.
Вот и все. Остается только протестировать наш стартер.
Код проекта с реализацией BeanPostProcessor: GitHub
Добавим следующие классы в демо проект:
WrapperServiceImpl остался из прошлой статьи с небольшими аналогичными изменениями
Controller остался таким же, как и в прошлой статье
В данной статье на примере стартера мы рассмотрели использование BeanPostProcessor и то, какие вещи с его помощью можно делать.
Не всегда spring может дать нам то, чего мы хотим, но часто, если нас что-то не устраивает, то есть возможность дополнить spring.
Ссылка на полный код проекта: GitHub



