A Networker’s Log File
I have a wide scope of interests in IT, which includes hyper-v private cloud, remote desktop services, server clustering, PKI, network security, routing & switching, enterprise network management, MPLS VPN on enterprise network etc. Started this blog for my quick reference and to share technical knowledge with our team members.
Wednesday, December 5, 2012
Concept of Cisco Bridge Domain Interfaces (BDI)
Today, I came across a strange configuration on a Cisco ASR router. It’s called «Bridge Domain Interfaces (BDI)». I did a search on Cisco website and the configuration looked simple. But it was short on concept explanation, which simply mentioned
«Bridge domain interface is a logical interface that allows bidirectional flow of traffic between a Layer 2 bridged network and a Layer 3 routed network traffic. Bridge domain interfaces are identified by the same index as the bridge domain. Each bridge domain represents a Layer 2 broadcast domain.«

ip ospf 1 area 0
The physical interface can even join more than 1 bridge domain (up to 4096 per router). For example, connecting to VLAN 200 (also Bridge Domain 200) as well:
11 comments:
![]()
I was not aware of this feature. Good to know and thanks for the info!
Today I m facing this issue..6 sites are down due to one BDI IP not pinging
![]()
Yes, shutting down the physical interface will cause an outage to all service instances (EVC/EFP) attached to that physical interface.
![]()
Really great work to explain it to that simple. Isnt it like creating sub-interfaces and furthermore why we would need to connect a single VLAN with multiple interfaces of same router.
![]()
In our case we have an Isolated network that we are using to migrate systems from one Data Center to the other. Below is the connection.
(Circuit) ASR 3750 Data Migration Switch
Production Switch
As you can see, we have the ASR connected to two different switches on the same VLAN. One 3750 switch is acting as the data migration switch. The other switch is the production core switch. The data migration switch is being used to offload the data traffic from the core. However, the production switch still needs to be connected for device management of both the ASR and the 3750 switch.
These could be /30 layer-3 links instead of layer-2 links but we wanted the flexibility to be able to connect a device to the core for the data transfer if we need to.
Bdi cisco что это
Итак, начнем с определений:
Bridge domain – это некая L2 логическая широковещательная область внутри устройства. Принцип работы такойже как и у коммутатора, а именно передача кадров в соответствии с mac таблицей. Для каждого номера bridge-domain будет свой экземпляр mac таблицы.
Encapsulation – этот параметр в настройках Service instance задает критерий выбора пакетов. Например настройка encapsulation dot1q 20 говорит что будут обработаны только кадры с тегом равным 20 (VLAN 20).
Рассмотрим самый простой пример настройки интерфейса.
Видно, что на физическом интерфейсе создается логический интерфейс так называемый service instance под номером 5, с encapsulation dot1q 20 и bridge-domain 20.
Все пакеты с тегом 20 будут попадать в bridge-domain 20.
В encapsulation dot1q можно указать несколько тегов. Например 10, c 14 по 16.
Если мы хотим принимать нетегированный траффик то в энкапсуляции задаем untagged.
На одном физическом интерфейсе может быть создано несколько service instanse, причем bridge-domain могут совпадать или быть разными.
Принцип работы rewrite ingress tag pop или трансляция vlan на cisco
Одна из ключевых особенностей технологии EVC это её повышенная гибкость, позволяющая с помощью механиза rewrite направлять кадры с разных vlan в нужный нам bridge-domain.
Рассмотрим пример использования rewrite.
В данном примере из всех входящих кадров с тегом 20 (encapsulation dot1q 20) будет удален внешний тег (rewrite ingress tag pop 1 symmetric), а во все исходящие кадры из bridge-domain будет тег (VLAN 20) добавлен.
Bridge Domain Routing или как связать L3 интерфейс с бридж доменом
Продолжим разговор о гибкости технологии EVC. Вот Вам пример: Клиент отдает нам маркированный траффик в VLAN 20. Нам его нужно принять на L3 интерфейсе, но VLAN 20 и соответственно interface vlan 20 у нас уже заняты, например под управление.
Решение данной задачи используя технологию EVC.
Маркированный траффик (VLAN 20) попадает на порт gigabitethernet0/1 service instance 1, далее снимается метка (rewrite ingress tag pop 1 symmetric) перекидывается в bridge-domainc с номером 300, ну и далее траффик попадает на L3 интерфейс.
А вот еще один пример только теперь мы принимаем траффик с двумя тегами от клиента.
Команды мониторинга и диагностики при работе с bridge-domain и service instance
1.Просмотр информации по bridge-domain. Выводит принадлежность bridge-domain к физическому интерфейсу и сервис инстансу.
2.Просмотр mac таблицы в бридже домене.
3.Просмотр всех созданных service instance.
Просмотр детальной информации по Ethernet Flow Point.
Просмотр статистики по Ethernet Flow Point.
На этом все. Мы рассмотрели только малую часть всех возможностей технологии EVC, но этого понимания должно хватить для дальнейшего самостоятельного освоения. Комментируем, подписываемся ну и всем пока:)
1″ :pagination=»pagination» :callback=»loadData» :options=»paginationOptions»>
Общие сведения об интерфейсах BVI и BDI
Параметры загрузки
Об этом переводе
Этот документ был переведен Cisco с помощью машинного перевода, при ограниченном участии переводчика, чтобы сделать материалы и ресурсы поддержки доступными пользователям на их родном языке. Обратите внимание: даже лучший машинный перевод не может быть настолько точным и правильным, как перевод, выполненный профессиональным переводчиком. Компания Cisco Systems, Inc. не несет ответственности за точность этих переводов и рекомендует обращаться к английской версии документа (ссылка предоставлена) для уточнения.
Содержание
Введение:
Этот документ помогает понять концепцию BDI (интерфейс домена моста) и BVI (виртуальный интерфейс группы мостов).
Интерфейсы BVI и BDI являются маршрутизируемыми интерфейсами, которые представляют ряд связанных интерфейсов.
Например, предположим, нужно связать два интерфейса на маршрутизаторе и разместить их в одном домене широковещательной рассылки уровня 2. В этом сценарии интерфейс BVI/BDI действовал бы как маршрутизируемый интерфейс для этих двух связанных мостом физических интерфейсов. Все пакеты, входящие в связанные интерфейсы или исходящие из них, должны будут пройти через интерфейс BVI/BDI.
Предварительные условия
Требования
Концепция виртуальных локальных сетей.
Используемые компоненты
Сведения в этом документе основываются на маршрутизаторе ISR (для BVI) и ASR1K (для BDI).
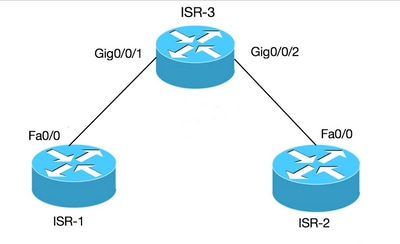
Виртуальный интерфейс мостовой группы: Интерфейс BVI: Для платформ, работающих с IOS
Маршрутизатор не позволяет настраивать два или больше интерфейса уровня 3 в том же домене широковещательной рассылки (два или больше интерфейса в одной подсети). Давайте Давайте Рассмотрим сценарий, в котором нужно подключить два ПК к маршрутизатору и сделать их частью той же подсети в дополнение к доступу к Интернету с обоих ПК.
Этой цели можно достичь с помощью концепции BVI.
bridge 1 protocol ieee
ip address 10.10.10.10 255.255.255.0
ip address 10.10.10.1 255.255.255.0
ip address 10.10.10.2 255.255.255.255
Bridge Domain Interface (BDI): Для платформ, работающих с IOS-XE
Эта концепция очень похожа на BVI, но предназначена для устройств, работающих с IOS-XE.
Ниже приведены некоторые широко используемые термины:
Домен моста представляет домен широковещательной рассылки уровня 2.
Bridge Domain Interface — логический интерфейс, обеспечивающий двунаправленный трафик между сетью с мостовыми подключениями уровня 2 и сетью с маршрутизацией уровня 3.
Виртуальный канал Ethernet (EVC) — сквозное представление единственного экземпляра сервиса уровня 2, предоставляемого заказчику поставщиком. На платформе EVC Cisco домены моста составлены из одного или нескольких интерфейсов уровня 2, известных как экземпляры служб. Экземпляр службы представляет собой экземпляр EVC, созданный по данному порту на данном маршрутизаторе. Экземпляр службы привязан к домену моста на основе конфигурации.
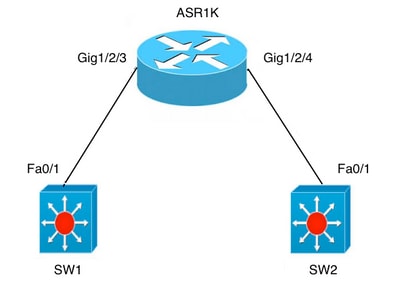
Ниже приведены несколько сценариев, описывающих использование концепции домена моста на платформах IOS-XE:
A) Fa0/1 на обоих коммутаторах являются интерфейсами уровня 3 и находятся в одном домене широковещательной рассылки. Настройка интерфейса BDI на ASR не требуется, если нужно просто установить подключение между двумя коммутаторами.
Configuring Bridge Domain Interfaces
Available Languages
Download Options
Table of Contents
Configuring Bridge Domain Interfaces
The Cisco ASR 1000 Series Aggregation Services Routers support the bridge domain interface (BDI) feature for packaging Layer 2 Ethernet segments into Layer 3 IP.
Finding Feature Information
Your software release may not support all the features documented in this module. For the latest feature information and caveats, see the release notes for your platform and software release. To find information about the features documented in this module, and to see a list of the releases in which each feature is supported, see the Feature Information for Configuring Bridge Domain Interfaces.
Restrictions for Bridge Domain Interfaces
The following are the restrictions pertaining to bridge domain interfaces:
– ![]() IPv4 Multicast
IPv4 Multicast
– ![]() QOS marking and policing. Shaping and queuing are not supported
QOS marking and policing. Shaping and queuing are not supported
– ![]() IPv4 VRF
IPv4 VRF
– ![]() IPv6 unicast forwarding
IPv6 unicast forwarding
– ![]() Dynamic routing such as BGP, OSPF, EIGRP, RIP, ISIS, and STATIC
Dynamic routing such as BGP, OSPF, EIGRP, RIP, ISIS, and STATIC
– ![]() Hot Standby Router Protocol (HSRP) from IOS XE 3.8.0 onwards.
Hot Standby Router Protocol (HSRP) from IOS XE 3.8.0 onwards.
– ![]() Virtual Router Redundancy Protocol (VRRP) from IOS XE 3.8.0 onwards.
Virtual Router Redundancy Protocol (VRRP) from IOS XE 3.8.0 onwards.
– ![]() PPP over Ethernet (PPPoE)
PPP over Ethernet (PPPoE)
– ![]() Bidirectional Forwarding Detection (BFD) protocol
Bidirectional Forwarding Detection (BFD) protocol
– ![]() Netflow
Netflow
– ![]() QoS
QoS
– ![]() Network-Based Application Recognition (NBAR) or Advanced Video Coding (AVC)
Network-Based Application Recognition (NBAR) or Advanced Video Coding (AVC)
Information About Bridge Domain Interface
Bridge domain interface is a logical interface that allows bidirectional flow of traffic between a Layer 2 bridged network and a Layer 3 routed network traffic. Bridge domain interfaces are identified by the same index as the bridge domain. Each bridge domain represents a Layer 2 broadcast domain. Only one bridge domain interface can be associated with a bridge domain.
Bridge domain interface supports the following features:
Prior to configuring a bridge domain interface, you must understand the following concepts:
Ethernet Virtual Circuit Overview
An Ethernet Virtual Circuit (EVC) is an end-to-end representation of a single instance of a Layer 2 service being offered by a provider to a customer. It embodies the different parameters on which the service is being offered. In the Cisco EVC Framework, the bridge domains are made up of one or more Layer 2 interfaces known as service instances. A service instance is the instantiation of an EVC on a given port on a given router. Service instance is associated with a bridge domain based on the configuration.
An incoming frame can be classified as service instance based on the following criteria:
Service instance also supports alternative mapping criteria:
For more information on the EVC architecture, see Configuring Ethernet Virtual Connections on the Cisco ASR 1000 Router chapter in the Carrier Ethernet Configuration Guide located at:
Bridge Domain Interface Encapsulation
Security Group classification includes both Source and Destination Group, which is specified by source SGT and DGT. SGT Based PBR feature provides the PBR route-map match clause for SGT/DGT based packet classification. SGT Based PBR feature supports configuration of unlimited number of tags, but it is recommended to configure the tags based on memory available in the platform.
An EVC provides the ability to employ different encapsulations on each Ethernet flow point (EFP) present in a bridge domain. A BDI egress point may not be aware of the encapsulation of an egress packet because the packet may have egressed from one or more EFPs with different encapsulations.
In a bridge domain, if all the EFPs have different encapsulations, the BDI must be untagged (using the no 802.1Q tag). Encapsulate all the traffic in the bridge domain (popped or pushed) at the EFPs. Configure rewrite at each EFP to enable encapsulation of the traffic on the bridge domain.
In a bridge domain, if all the EFPs have the same encapsulation, configure the encapsulations on the BDI using the encapsulation command. Enabling encapsulation at the BDI ensures effective pushing or popping of tags, thereby eliminating the need for configuring the rewrite command at the EFPs. For more information on configuring the encapsulations on the BDI, see the How to Configure a Bridge Domain Interface.
Assigning a MAC Address
All the bridge domain interfaces on the Cisco ASR 1000 chassis share a common MAC address. The first bridge domain interface on a bridge domain is allocated a MAC address. Thereafter, the same MAC address is assigned to all the bridge domain interfaces that are created in that bridge domain.

Note ![]() You can configure a static MAC address on a bridge domain interface using the mac-address command.
You can configure a static MAC address on a bridge domain interface using the mac-address command.
Support for IP Protocols
Brigde domain interfaces enable the Cisco ASR 1000 Series Aggregation Services Routers to act as a Layer 3 endpoint on the Layer 2 bridge domain for the following IP-related protocols:
Support for IP Forwarding
Bridge domain interface supports the following IP forwarding features:
– ![]() Classification
Classification
– ![]() Marking
Marking
– ![]() Policing
Policing
Packet Forwarding
A bridge domain interface provides bridging and forwarding services between the Layer 2 and Layer 3 network infrastructure.
Layer 2 to Layer 3
During a packet flow from a Layer 2 network to a Layer 3 network, if the destination MAC address of the incoming packet matches the bridge domain interface MAC address, or if the destination MAC address is a multicast address, the packet or a copy of the packet is forwarded to the bridge domain interface.
Note ![]() MAC address learning cannot not be performed on the bridge domain interface.
MAC address learning cannot not be performed on the bridge domain interface.
Note ![]() In a bridge domain, when flooding unknown unicast frames, bridge domain interface is not included.
In a bridge domain, when flooding unknown unicast frames, bridge domain interface is not included.
Layer 3 to Layer 2
When a packet arrives at a Layer 3 physical interface of a router, a route lookup action is performed. If route lookup points to a bridge domain interface, then the bridge domain interface adds the layer 2 encapsulation and forwards the frame to the corresponding bridge domain. The byte counters are updated.
During a Layer 2 lookup on a bridge domain to which the bridge domain interface belongs, the bridge domain forwards the packets to the correct service instance based on the destination MAC address.
Link States of a Bridge Domain and a Bridge Domain Interface
Bridge domain interface acts as a routable IOS interface on Layer 3 and as a port on a bridge domain. Both bridge domain interfaces and bridge domains operate with individual administrative states.
Shutting down a bridge domain interface stops the Layer 3 data service, but does not override or impact the state of the associated bridge domain.
Shutting down a bridge domain stops Layer 2 forwarding across all the associated members including service instances and bridge domain interfaces. The operational state of a bridge domain is influenced by associated service instances. Bridge domain interface cannot be operational unless one of the associated service instance is up.
Note ![]() Because a bridge domain interface is an internal interface, the operational state of bridge domain interface does not affect the bridge domain operational state.
Because a bridge domain interface is an internal interface, the operational state of bridge domain interface does not affect the bridge domain operational state.
BDI Initial State
The initial administrative state of a BDI depends on how the BDI is created. When a BDI is created at boot time in the startup configuration, the default administrative state for the BDI will be up, and will remain in this state unless the startup configuration includes the shutdown command. This behavior is consistent with all the other interfaces. When a BDI is created dynamically by a user at command prompt, the default administrative state is down.
BDI Link State
As with all Cisco IOS interfaces, a BDI maintains a link state that comprises of three states, administratively down, operationally down, and up. The link state of a BDI is derived from two independent inputs, the BDI administrative state set by the corresponding users and the fault indication state from the lower levels of the interface states. defines a BDI link state based on the state of the two inputs.
No faults asserted
At least one fault asserted
Bridge Domain Interface Statistics
For virtual interfaces, such as the bridge domain interface, protocol counters are periodically queried from the QFP.
When packets flow from a Layer 2 bridge domain network to a Layer 3 routing network through the bridge domain interface, the packets are treated as bridge domain interface input packets and bytes. When packets arrive at a Layer 3 interface and are forwarded through the bridge domain interface to a Layer 2 bridge domain, the packets are treated as output packets and bytes, and the counters are updated accordingly.
A BDI maintains a standard set of Layer 3 packet counters as the case with all Cisco IOS interfaces. Use the show interface command to view the Layer 3 packet counters.
The convention of the counters is relative to the Layer 3 cloud, for example, input refers to the traffic entering the Layer 3 cloud from the Layer 2 BD, while output refers to the traffic leaving the Layer 3 cloud to the Layer 2 BD.
Use the show interfaces accounting command to display the statistics for the BDI status. Use the show interface command to display the overall count of the packets and bytes that are transmitted and received.
Creating or Deleting a Bridge Domain Interface
When you define an interface or subinterface for a Cisco IOS router, you name it and specify how it is assigned an IP address.You can create a bridge domain interface before adding a bridge domain to the system, this new bridge domain interface will be activated after the associated bridge domain is configured.
Note ![]() When a bridge domain interface is created, a bridge domain is automatically created.
When a bridge domain interface is created, a bridge domain is automatically created.
When both bridge domain interface and bridge domain are created, the system maintains the required associations for mapping the bridge domain-bridge domain interface pair.
The mapping of bridge domain and bridge domain interface is maintained in the system. The bridge domain interface uses the index of the associated bridge domain to show the association.
Bridge Domain Interface Scalability
Table 14-1 lists the bridge domain interface scalability numbers, based on the type of Cisco ASR 1000 Series Aggregation Services Router’s Forwarding Processors.
Table 14-1 Bridge Domain Interface Scalability Numbers Based on the Type of Cisco ASR 1000 Series Aggregation Services Router’s Forwarding Processor
Сети для Самых Маленьких. Микровыпуск №5. FAQ по сетевым технологиям
Пока весь мир с замиранием ждёт 11-го выпуска СДСМ, посвящённого MPLS BGP L3VPN, я решил сделать вольный перевод неплохой статьи Джереми Стреча с Packetlife.net.
Это подборка небольших FAQ для новичков.
#На каком уровне OSI работает протокол Ч?
Первая вещь, с которой сталкивается любой, кто изучает сети — это модель OSI (Open Systems Interconnection). Это семиуровневая эталонная модель, официально определённая в IOS/IEC 7498-1. Вы встретите её в любой когда либо напечатанной учебной литературе. Это совершенно обычное дело — ссылаться на OSI при обсуждении взаимодействия между протоколами. Так, например, TCP — это протокол четвёртого уровня, и он сидит на шее IP — протоколе третьего уровня.
Но что это значит на самом деле? Кто решает какому уровню принадлежит протокол? Модель OSI была задумана ещё в 70-е годы, как часть семейства протоколов OSI, которая на полном серьёзе позиционировалась как соперник стеку TCP/IP (спойлер: TCP/IP таки выиграл). Если исключить горстку выживших (наверняка, вы слышали про протокол динамической маршрутизации IS-IS), то протоколы OSI сейчас фактически не используются. Однако эталонная модель OSI, описывающая, как они должны были взаимодействовать, живее всех живых. Что, впрочем, заставляет нас привязывать протоколы одного семейства к уровням, определённым для другого.
По большей части всё работает прекрасно: TCP и UDP едут верхом на IP, который в свою очередь передвигается на Ethernet, PPP или чём бы там ни было другом. Но сорокалетняя модель не всегда может удовлетворить нужны современных протоколов. Возьмём для примера MPLS. Часто его относят к уровню 2,5, потому что он работает поверх канального, но ниже сетевого, не осуществляя при этом ни формирования фреймов ни сквозную адресацию (в отличии от IP-адресов, метки MPLS меняются на каждом узле по мере продвижения пакета к точке назначения). Разумеется, добавление нового уровня между двумя другими разрушает стандартную модель.
Строго говоря, ни один протокол из стека TCP/IP не закреплён официально за каким-либо уровнем OSI именно по той причине, что это разные семейства. Яблоки и апельсины. Эталонная модель — это эталон (Прим. переводчика: всё-таки русское название немного не соответствует Reference Model, эталон предполагает свою идеальность и стремление ему соответствовать). OSI помогает иллюстрировать зависимость одних протоколов от других, и кто кем погоняет, но она не может диктовать, как им функционировать.
Но если вдруг кто-то спросит, отвечайте, что MPLS — это протокол третьего уровня.
#Какая разница между маршрутизатором и многоуровневым коммутатором?
В стародавние времена, маршрутизаторы служили для того чтобы передавать пакеты на основе IP-адресов и предоставляли широкий диапазон интерфейсов: Ethernet, E1, Serial, OC-3 итд. В то же время коммутатор передавал пакеты (кадры, прим. для лиги зануд), основываясь на MAC-адресах, и имели только порты Ethernet.
Но в начале 2000-х нашему чёткому пониманию этой разницы пришёл конец — вырисовывались две важные тенденции. Во-первых, появились многоуровневые коммутаторы, которые не просто получили право передавать пакеты, основываясь на IP-адресах, но и участвовать в протоколах динамической маршрутизации, как самые настоящие маршрутизаторы. Во-вторых, операторы начали необратимый процесс миграции с технологий с коммутацией каналов на модерновый Ethernet, предоставляющий высокие скорости за низкую плату. Сегодня совершенно в порядке вещей, если маршрутизатор имеет только Ethernet-интерфейсы, как будто бы он коммутатор.
Где лежит граница между маршрутизатором и многоуровневым коммутатором? Существует ли ещё эта граница?
Фактическая разница между ними сводится к следующим нескольким пунктам:
#Какая разница между forwarding и control planes?
Для новичков это, несомненно, источник путаницы.
Forwarding plane часто называют Data Plane, а по-русски самый удачный вариант — плоскость коммутации. Её задача — доставить пакет из пункта А в пункт Б. Плоскость коммутации коммутирует.
Control plane — плоскость управления — обслуживает функции предписывающие, как должна работать плоскость коммутации. Плоскость управления управляет.
Вот например, у вас есть маршрутизатор с OSPF. Он обменивается маршрутной информацией с соседними маршрутизаторами OSPF, составляет граф всей сети и вычисляет маршруты. Когда таблица маршрутизации (RIB) построена, маршрутизатор инсталлирует лучший маршрут до каждой известной точки назначения в таблицу коммутации (FIB). Это функции control plane.
Когда тот же маршрутизатор получает IP-пакет, он ищет адрес назначения в своей таблице коммутации, чтобы определить интерфейс, в который пакет нужно отправить. Далее пакет передаётся в буфер выходного интерфейса и затем в кабель. Это функции forwarding plane.
Чувствуете различие? Плоскость коммутации отвечает за приём и передачу пакетов, в то время как плоскость управления — за то, как именно принимается решение о передаче пакета.
Плоскость коммутации реализована, как правило, в железе, иными словами выполняется специальными чипсетами (например, Network Processor обращается к TCAM, чтобы быстро извлечь выходной интерфейс из FIB), не требуя обращения к CPU.
Плоскость управления же работает на CPU и в обычной памяти, что очень похоже на работу персонального компьютера. Дело в том, что уровень управления выполняет очень сложные функции, которые с одной стороны не нужны в реальном времени, а с другой их проблематично реализовать в железе. Например, совершенно не важна задержка в несколько миллисекунд, когда маршрутизатор инсталлирует маршрут в таблицу коммутации, в то время как для уровня коммутации это может быть серьёзной деградацией производительности.
#Какая разница между MTU и MSS?
Maximum transmission unit (MTU) говорит о максимальном объёме данных, который может нести один пакет. Обычно мы говорим о MTU в отношении Etherner (хотя другие протоколы, конечно, тоже имеют свои MTU). MTU по умолчанию на большинстве платформ — 1500 байтов. Это означает, что узел может передать кадр, несущий 1500 байтов полезной нагрузки. Сюда не включены 14 байтов заголовка Ethernet (18 в случае 802.1q) и 4 байта поля FSC. Итоговый же размер кадра 1518 байтов (1522 в случае 802.1q). Многие узлы сейчас поддерживают джамбофреймы (jumbo), для этого стандартный MTU увеличивается до 9000+ байтов.
Maximum segment size (MSS) — это величина характерная для TCP, которая показывает максимальную полезную TCP нагрузку в пакете, фактически это MTU для TCP. TCP MSS вычисляется, исходя из значения Ethernet MTU (а, может, и не Ethernet) на интерфейсе. Поскольку TCP должен втиснуться в кадр Ethernet, MSS должен быть меньше, чем MTU. В идеале MSS должен быть максимально возможным: MTU-размер заголовка IP-размер заголовка TCP.
Предположим MTU 1500 байтов, вычитаем из него 20 байтов IPv4 адреса и ещё 20 байтов TCP и получаем MSS 1460 байтов. IPv6 с его удлинённым заголовком оставит для MSS всего 1440 байтов.
TCP MSS определяется один раз в ходе установления соединения. Каждый узел включает свой MSS в опции TCP в первый пакет (тот, что с флагом SYN), и оба узла выбирают наименьшее значение из двух как MSS сессии. Однажды установленный MSS уже не меняется в течение жизни сессии.
#Какая разница между интерфейсами VLAN и BVI?
VLAN-интерфейс, известный также как SVI (Switch Virtual Interface) или RVI (Routed VLAN Interface) — это виртуальный интерфейс на многоуровневом коммутаторе. Он обеспечивает маршрутизацию и часто служит шлюзом по умолчанию для локального сегмента сети. VLAN-интерфейс обычно ведёт себя и настраивается как физический интерфейс маршрутизатора: на него можно назначить IP, он участвует в VRRP, может иметь ACL итд. Вы можете представить себе, что это физический интерфейс внутри коммутатора, а можете, наоборот, вообразить, что это маршрутизирующий интерфейс вне коммутатора, на котором терминируется данный VLAN.
Bridge group Virtual Interface (BVI) служит похожим целям, но существует на маршрутизаторе, на котором нет концепции VLAN, потому что всего его порты обычно работают на L3 (Прим. переводчика: на маршрутизаторах концепция VLAN вполне может присутствовать). Bridge group заставляет два или более портов работать на L2, разделяя между ними широковещательный домен. BVI связывает интерфейсы в Bridge Group и служит виртуальными L3-интерфейсом для всех сегментов, подключенных к нему. Когда маршрутизатор работает одновременно на L2 и L3, его называют Integrated Routing and Bridging (IRB).
В то время, как VLAN-интерфейс — жизненная необходимость многоуровневого коммутатора, IRB — нишевая вещь, которая может использоваться, например, на точках доступа WiFi.
#Как работает туннельный интерфейс?
Многие люди испытывают трудности с пониманием концепции туннельных интерфейсов (Прим. переводчика: действительно?). Туннелирование — это просто инкапсуляция одних пакетов внутрь других при передаче их между двумя точками. Туннельный интерфейс используется для достижения такой инкапсуляции для маршрутизируемых VPN, которые позволяют защититься и абстрагироваться от топологии нижележащей сети. Существует много методов инкапсуляции, включающие IPSec, GRE, MPLS итд.
Несмотря на то, что туннельный интерфейс имеет виртуальную природу, ведёт себя он как и любой другой, когда дело доходит до маршрутизации, с той лишь разницей, что когда пакет выходит через туннельный интерфейс, он упаковывается в новый пакет, для которого снова принимается решение о маршрутизации. Новый беременный пакет отправляется в среду и достигает в конечном счёте точки назначения. На другом конце туннеля внешние заголовки снимаются, и на свет выходит оригинальный пакет, над которым снова принимается решение о маршрутизации.
#Что означают четыре типа адресов в NAT?
Возьмём для примера случай, когда вы с компьютера с приватным адресом 192.168.0.10 хотите зайти по telnet на адрес в Интернете 94.142.241.111. Из пула NAT вам выделен IP-адрес 192.0.2.10.
Вот так будет выглядеть таблица трансляций:
Inside Global — как внутренний узел выглядит извне. Сервер в Интернете действительно видит адрес из вашего пула NAT.
Inside Local — как внутренний адрес выглядит изнутри — приватный адрес компьютера
Outside Local — как внешний адрес выглядит инзнутри — видим его публичный адрес и порт 23.
Outside Global — тут должно быть то, как выглядит внешний адрес извне, но ваш NAT таких трансляций не умеет, поэтому адрес совпадает с Outside Local.
#Могу ли я использовать адрес сети и широковещательный адрес в NAT-пуле?
Во-первых, в контексте пула NAT вообще нет понятий маски адрес сети и широковещательный адрес.
Во-вторых адрес сети и широковещательный адрес определяются маской подсети — без неё они теряют смысл. Поэтому считать ли адрес 192.168.0.255 широковещательным адресом, а 192.168.1.0 адресом сети зависит целиком и полностью от маски: для /23 ответ нет, для /24 и более ответ да, а для /32 снова нет.
Поэтому адрес 192.168.0.255 вы можете не только указать в пуле, но даже настроить на интерфейсе с маской /23.
#Почему нам нужны IP-адреса? Разве нам не хватит MAC-адресации для всего?
Когда новичок начинает изучение MAC-адресов, он видит, что они должны быть уникальными глобально. И возникает закономерный вопрос, почему бы не использовать MAC-адреса для сквозной адресации через весь Интернет, не прибегая вообще к IP? Однако существует несколько достаточно весомых причин привлечь IP.
Во-первых, не все сети имеют MAC-адресацию. Вообще такой тип свойственен только семейству 802. Очень легко забыть об этом в мире, где практически всё — Ethernet или его вариации (например IEEE 802.11 WiFi). Но во времена юности Ethernet несколько десятилетий назад буйствовало беззаконие в сфере протоколов: Token Ring, Ethernet, Frame Relay, ATM боролись за место в маршрутизаторе. И обеспечить взаимодействие узлов из Token Ring с узлами из ATM посредством MAC-адресов было проблематично — нужен был протокол сетевого уровня.
Во-вторых, IP-адреса мобильны — они могут назначаться администраторами или даже выдаваться автоматически, в то время, как MAC-адреса вшиты в сетевой адаптер на веки вечные. Технически MAC-адрес, конечно, тоже можно поменять, но это не предполагалось изначально и сейчас нет никаких средств для удобного управления ими.
Но самая главная причина третья — IP масштабируем и может связывать огромные сети, а Ethernet — удел небольших сегментов. Пространство IP-адресов иерархично, MAC-адресов — плоско. 254 узла одной локальной сети могут быть агрегированы в одну подсеть /24. 8 подсетей /24 могут быть агрегированы в одну /21. Это возможно, потому что блоки адресов обычно располагаются рядом в Интернете. Всё, о чём нужно заботиться в этом случае маршрутизатору — как добраться до подсети.
MAC-адреса же каждый сам по себе, так как назначаются псевдослучайным образом на производстве, и два адреса, различающихся только в последнем бите, могут оказаться в диаметральных концах планеты. Если вдруг кому-то взбредёт в голову использовать MAC-адреса для сквозной адресации в Интернете, он столкнётся с тем, что маршрутизаторам будет нужно знать адрес каждого отдельно взятого узла в глобальной сети. Здравствуй, интернет вещей.
Далее прим. переводчика.
Освещённый в оригинальной статье вопрос на самом деле простой — одного отсутствия масштабирования достаточно для того, чтобы отказаться от этой идеи.
Гораздо интереснее обратный вопрос: Почему нам нужны MAC-адреса? Разве нам не хватит IP-адресации для всего? Тут всё не так однозначно. Почему бы действительно в современном мире, где скоро название стека можно менять на TCP/IP/Ethernet, не отказаться совсем от адресации на L2 и позволить узлам в сегменте взаимодействовать по IP?
ARP больше не нужен — пакет коммутируется по IP (кстати, уже сейчас существуют коммутаторы, которые действительно могут производить IP Learning вместо MAC Learning). Широковещание доступно так же через адрес 255.255.255.255.
При этом, я не предлагаю отказаться от Ethernet или L2 совсем, нет — утот уровень абстракции необходим — сетевой не должен работать напрямую с физическим, заниматься фреймингом, проверкой целостности итд; мы просто убираем адресацию из L2.
Сложность начинается на самом деле при передаче пакета из одной подсети в другую через череду маршрутизаторов. Тут даёт о себе знать широковещательная природа Ethernet. В заголовке IP, адрес назначения фиксирован и не меняется по мере продвижения пакета. Поэтому встаёт вопрос, как правильно переслать пакет между маршрутизаторами. Сейчас как раз для этого используются MAC-адреса Next-Hop. Дело в том, что за Ethernet-интерфейсом маршрутизатора может быть не один соседний маршрутизатор, а два, три, десяток, и здесь придётся добавлять ещё какой-то идентификатор Next-hop.
В реальном мире в 99,9% мы используем P2P линии между маршрутизаторами и тут нет необходимости в добавлении адреса Next-hop в пакет — больше ведь и слать некому — просто отправляем кадр в кабель. Тут можно вспомнить PPP, где хоть формально поле «адрес» и есть, но оно фактически не используется.
Но концепция Ethernet, который изначально планировался только для локальных сегментов с пользовательскими машинами, не предусматривает сценарий P2P отдельно.
В итоге адресацию с уровня Ethernet мы не можем убрать. Однако тут до сих пор остаётся вопрос — зачем MAC-адреса, ведь в заголовке Ethernet мы могли бы указывать IP-адрес Next-Hop, который менялся бы также на каждом узле.
В целом это верно, но такой подход ломает идеологию стека протоколов, предполагающую независимость уровней друг от друга. Сейчас, например, легко можно выкинуть Ethernet и вместо него использовать xDSL или PON или, прости Лейбниц, Frame Relay — сложности лишь административные и финансовые. Также, поверх Ethernet технически вы можете пустить собственный сетевой протокол IPЧ — и это всё будет работать с минимальными изменениями (добавить новый Ethertype).
Замечу, что этот вопрос нельзя обсуждать в отрыве от исторического и административного контекста. Даже если мы возьмём на себя смелость предположить, что мы нашли идеальное сочетание идеальных протоколов IP+Ethernet, и ближайшие 300 лет нам не грозят глобальные изменения, нужно помнить, что 20 лет назад мир был другим, как мы уже говорили выше, и Ethernet был лишь одним из. Мы не могли так жёстко связывать сетевой и канальный уровни. А теперь сети, которые уже работают, и нам для этого как правило не нужно прилагать титанических усилий, никто не будет переделывать просто потому, что кажется избыточным одновременное использование IP и MAC-адресации.
Кстати, возможно, вы будете несколько удивлены, но часть описанных идей войдут в нашу с вами жизнь в лице IPv6 с его концепцией Link-Local адресов.
#Позволяет ли QoS расширить пропускную способность?
Среди новичков иногда существует заблуждение, что QoS — это волшебная технология, позволяющая пропихнуть через линию больше пакетов, чем она может. Это не так. К примеру, если ваш интернет-канал ограничен 10Мб/с, вы никогда не сможете отправить в него больше. Задача QoS — отдавать предпочтения одним типам трафика над другими. Таким образом во время перегрузки на линии (при попытке отправить больше 10 Мб/с) менее важный трафик будет отброшен в пользу свободной передачи более приоритетного.
Обычно QoS применяется для того, чтобы защитить трафик реального времени, такой как голос или видеоконференции от трафика, терпимого к задержкам и потерям — WEB, почта, FTP, Torrent итд. Кроме того QoS поможет избежать оккупирования всей полосы передачей большого объёма трафика, типа резервного копирования серверов.
Рассмотрим ситуацию, когда у вас есть офис, подключенный через два канала E1 с общей пропускной способностью 4Мб/с. По этой линии передаётся и голос и данные. Чтобы во время перегрузки голосовой трафик не испытывал деградацию, с помощью QoS можно выделить гарантированную полосу для него. Оставшаяся часть будет доступна для данных. Однако если после этого трафик с данными заметно ухудшится, то QoS уже не поможет — в этом случае придётся расширять канал.
Переводчик позволил себе некоторые вольности в русскоязычных терминах, которые позволят, как ему кажется, лучше понять смысл.



