Мониторинг Microsoft SQL Server «на коленке»
Когда я устроился на новую работу, передо мной была поставлена первая задача — разобраться, почему один из экземпляров SQL очень сильно нагружает диски. И предпринять необходимые действия для устранения этой ужасной проблемы. Я еще не сказал, что дисковый пул был всего один, и что при нагрузке на диски страдали все экземпляры сиквела? Так вот это было так. Что самое главное, как оказалось, мониторинг в лице Zabbix не собирал необходимые метрики, а на добавление оных нужно было заводить заявку и ждать. Ждать и смотреть, как «горит» дисковый массив. Или…
Было решено отправить заявку в путешествие сквозь шестерни бюрократического механизма и делать свой, временный мониторинг.
Для начала создадим БД и объекты, необходимые для сбора метрик производительности SQL-сервера.
Для простоты, я не стал в скрипте указывать опции создания БД:
Значения счетчиков производительности будем забирать из системного представления sys.dm_os_performance_counters. В скрипте описаны самые популярные и жизненно необходимые счетчики, естественно, список можно расширить. Хотелось бы пояснить по поводу CASE’ов. Счетчики, которые измеряются в «что-то»/секунду — инкрементальные. Т.е. SQL сервер каждую секунду прибавляет текущее значение счетчика к уже имеющемуся. Чтобы получить среднее текущее значение нужно значение в представлении делить на аптайм сервера в секундах. Узнать аптайм можно запросом:
Т.е. найти разницу между текущим моментом и временем создания tempdb, которая, как известно, создается в момент старта сервера.
Метрику Granted Workspace Memory (KB) сразу перевожу в мегабайты.
Процесс сбора оформим в виде процедуры:
Далее создадим процедуру, которая будет выбирать данные из нашей логовой таблицы. Параметры end и start задают временной интервал, за который мы хотим увидеть значения. Если параметры не заданы, выводить информацию за 3 последних часа.
Завернем sp_insert_perf_counters в задание SQL-агента. С частотой запуска — раз в минуту.
Скрипт создания джоба я пропущу, чтобы не захламлять текст. В конце выложу все в виде одного скрипта.
Забегая вперед, скажу что дело было в том числе и из-за банальной нехватки оперативной памяти, поэтому сразу приведу скрипт, позволяющий посмотреть «борьбу» БД за буфферный пул. Создадим табличку, куда будем складывать данные:
Cоздадим процедуру, которая будет выводить использование буфферного пула каждой отдельной базой данных:
Грязные страницы = измененные страницы. Эту процедуру заворачиваем в джоб. Я поставил выполняться раз в три минуты. И создадим процедуру для селекта:
Отлично, данные собираются, историческая база копится, осталось придумать удобный способ просмотра. И тут нам на помощь приходит старый добрый Excel.
Я приведу пример для счетчиков производительности, а для использования буфферного пула можно будет настроить по аналогии.
Открываем Excel, заходим в «Данные» — «Из других источников» — «Из Microsoft Query».
Создаем новый источник данных: драйвер — SQL Server или ODBC для SQL Server или SQL Server native Client, нажимаем «связь» и прописываем свой сервер, выбираем нашу БД в параметрах, в пункте 4 выбираем любую таблицу (она нам не понадобится).
Кликаем на наш созданный источник данных, нажимаем «Отмена» и на вопрос «Продолжить изменение запроса в Microsoft Query?» нажимаем «Да».
Выбираем, куда поместить результаты. Рекомендую оставить две строки сверху для параметров.
Идем в «Данные» — «Подключения», заходим в свойства нашего подключения. Переходим на вкладку «Определение» и там, где текст команды пишем exec sp_select_perf_counters.
Нажимаем ОК и Excel предлагает нам выбрать, из каких ячеек ему брать эти параметры. Указываем ему эти ячейки, ставим галки «использовать по умолчанию» и «автоматически обновлять при изменении ячейки». Лично я эти ячейки заполнил формулами:
Параметр1 =ТДАТА()-3/24 (текущие дата и время минус 3 часа)
Параметр2 =ТДАТА() (текущие дата и время)
Далее кликаем на нашей таблице и идем в «Вставка» — «Сводная таблица» — «Сводная диаграмма».
Настраиваем сводную таблицу:
Поля легенды — counter_name,
Поля осей — collect_time,
Значения — value.
Вуаля! Получаем графики метрик производительности. Рекомендую изменить тип диаграммы на «График». Осталась еще пара штришков. Переходим на страницу с нашими данными, опять заходим в свойства подключения и выставляем в «Обновлять каждые X мин» значение по желанию. Думаю, логично выставить частоту равную частоте выполнения задания на SQL сервере.
Теперь данные в таблице обновляются автоматически. Осталось заставить обновляться график. Переходим во вкладку «разработчик» — «Visual Basic».
Кликаем слева на лист с исходными данными и вписываем следующий код:
«Своднаятаблица» — имя листа со сводной таблицей. То имя, что указано в скобках в VB редакторе.
«СводнаяТаблица1» — имя сводной таблицы. Можно посмотреть, кликнув на сводной таблице и зайдя в раздел «Параметры».
Теперь наш график будет обновляться каждый раз, когда обновляется исходная таблица. Пример такого графика:
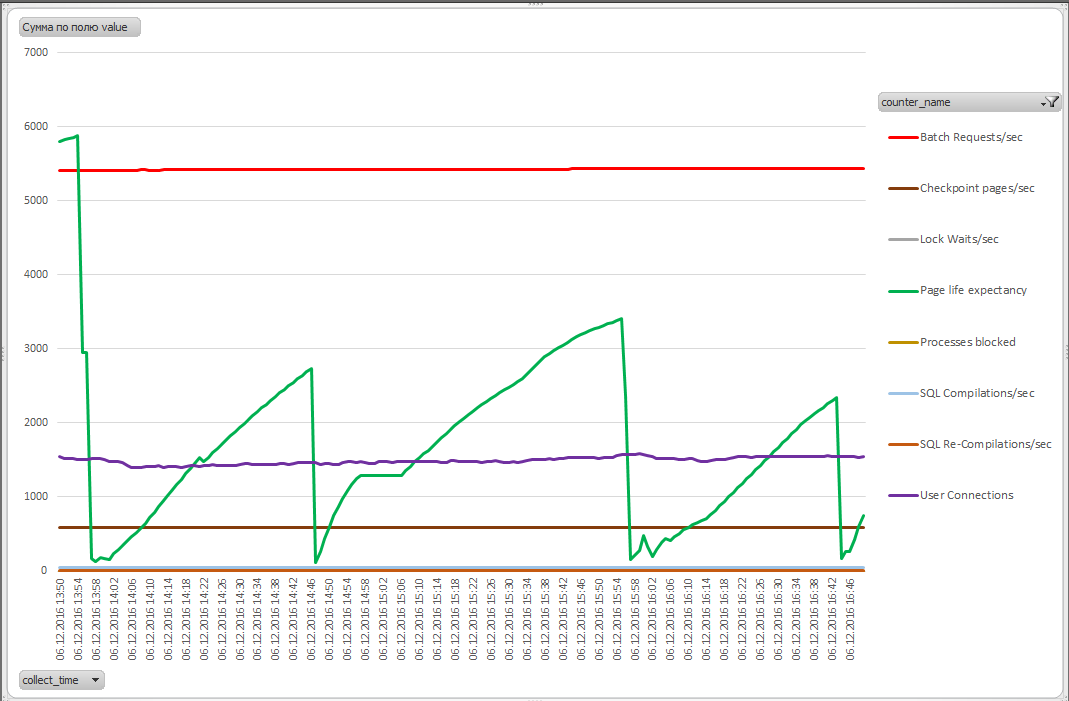
Для клонирования файла достаточно в свойствах нашего подключения в Excel изменить строку подключения, вписав новое имя сервера.
Касательно «борьбы» баз за буфферный пул и вычисления рекомендуемого количества оперативной памяти, для минимизации этой борьбы можно использовать следующий скрипт. Вычисляет максимальное использование оперативной памяти каждой БД, а также средний процент размера буфферного пула относительно общего размера оперативной памяти, выделенной серверу и на основании этих данных вычисляет «идеальный» размер оперативки, требуемой серверу:
Стоит заметить, что данные вычисления имеют смысл только если вы уверены, что запросы, работающие на сервере оптимизированы и не делают full table scan при каждом удобном (и не очень) случае. Также следует убедиться, мониторя метрику Maximum Granted Workspace, что у вас на сервере нет запросов, отъедающих часть буфферного пула под сортировку и hash-операции.
Пример войны баз за буфферный кэш (имена замазал):
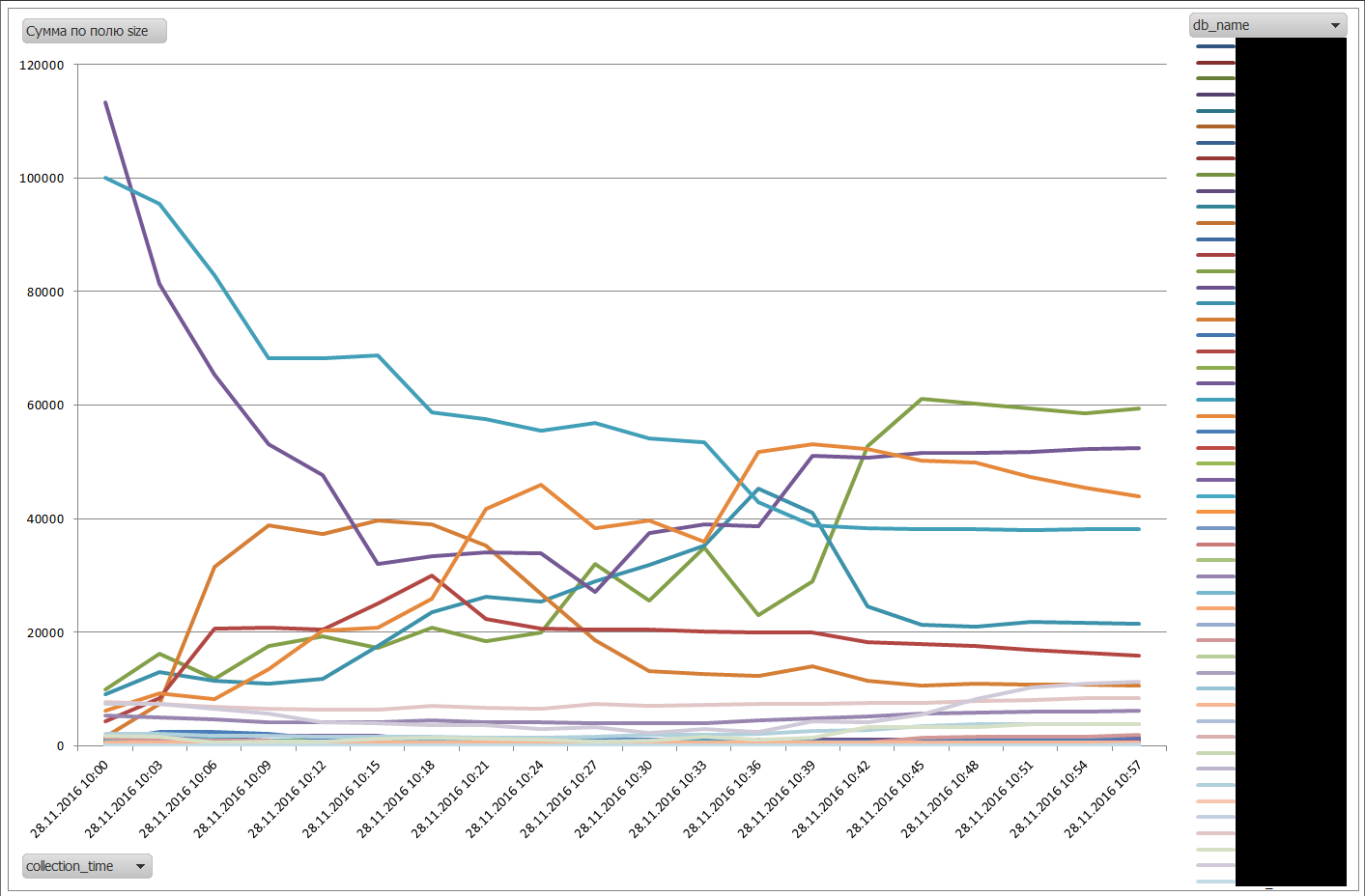
Кстати, оказалось, что этот метод работает намного быстрее нашего заббикса, так что я оставил его себе на вооружение.
SQLShack

SQL Server performance counters (Batch Requests/sec or Transactions/sec): what to monitor and why
When maintaining SQL Server, it is essential to get an accurate perception of how busy it is. Two metrics that are often considered as indicators of how busy SQL Server is are Batch Requests/sec and Transaction/sec. When those metrics trend higher, they often affect all other metrics and make them go higher as well. While they could look similar, they are using a different type of starting point for measurement; the batches and transactions. So, to correctly understand those important metrics, lets first try to understand what the batches and transactions in SQL Server are and what are the differences between the two
SQL Server statement batches
When executing multiple SQL Server statements as a group of statements, or when executing a single SQL statement that consists of a group of multiple SQL statements, it is considered as a SQL Server batch. That practically means that the result is returned after the entire batch statement executes. The advantage of such approach is that execution is more efficient compared to executing each containing statement independently. One aspect of better efficiency lies in the fact that network traffic is reduced in most cases, the second aspect is that targeted data source can often optimize execution of the statements in a SQL Server batch
Some facts about SQL batches:
SQL Server Open Database Connectivity (ODBC) API supports three types of batches
Explicit batches – this is when two or more SQL statements are combined in the single batch script and separated by semicolons (;)
All statements in the previous batch example are separated with the semicolon (highlighted) except the last statement in the batch
Stored procedures – every stored procedure that contains more than one SQL statement is considered by SQL Server as a batch of included SQL statements. The difference here is that the stored procedure contains the statements that are specific to SQL Server. Stored procedures do not use semicolons for separating statements. It is because the SQL Server specific CREATE PROCEDURE statement handles the statements within the stored procedure and therefore it does not need statement separators
It is important to understand that the CREATE PROCEDURE statement itself is not a batch statement, but the resulting procedure executes as a batch of SQL statements that it contains. So when executing the Test stored procedure from the example above, the two SELECT SQL statements will be executed as a batch of SQL statements
Arrays of parameters – When parametrized statements are used by the application, having an array of parameters is an effective way of to perform the execution of a single statement multiple times as a batch execution
In the above example, using question marks (?) or the properly called parameter marker means that they are bound to application variables. So, when application provides parameters to the SQL statement, it allows inserting multiple rows of data in a single execution. For data sources that do not support arrays of parameters, the ODBC driver can emulate the arrays thus passing the set by set of values to the statement. In that case, the statement executes as a batch of individual statements for each set of values
SQL Transaction
A SQL transaction is a SQL Server unit of work performed on a SQL database. Each SQL Server transaction consists of multiple operations, where each operation can consist of multiple SQL statements, executed in a specified order. The main characteristic of SQL transaction is that it can be either fully completed or completely failed. So, when a SQL transaction starts, it starts with executing the first SQL Statement in a transaction, and it can complete with all SQL Statements contained within transaction committed or if any of the SQL Statements fails, the complete SQL transaction changes are rolled back (all changes made on the SQL Server are undone). SQL Server transactions must fully comply with SQL Server atomicity, consistency, isolation and durability (ACID) concept, established to ensure database data integrity. The SQL Server ACID concept considers that each and every transaction has to comply with those four requirements:
At its elemental level, a SQL Server transaction is essentially the SQL batch with a “cancel with rollback” option
SQL Server supports the following transaction modes:
Both, SQL transactions and SQL batches are more complex concepts with lots of variations, but this is all that needs to be known about the SQL batch/transaction implementation concepts to correctly understand the batches/sec and transactions/sec metrics and the rest of the article.
Now, let’s focus on the metrics itself.
Batch Requests/sec metric
The Batch Requests/sec (in some literature referred as Batch Requests per Second) metric is SQL Server performance that provides information about the number of SQL batches SQL Server received in one second. For a DBA that knows their server well, this is probably the first metric to look for when slow query execution issue is reported. However, the Batch Requests/sec metric itself should not be looked in isolation from other metrics. It is important to track and put in correlation the CPU and I/O performance to get the correct and comprehensive insight of how the SQL Server is performing. The metric itself is not something that is a direct representation of an issue, and there are few things to understand before jumping to a conclusion:
Batch Requests/sec value is high – the tricky part here is to determine what the high value of this metric is. The ability of the SQL Server to process SQL statements depends on hardware factors such as CPU, I/O, memory, etc., but also on the “software” factors such as the design of stored procedures, tables, and indexes. Therefore, it is essential to look at this metric holistically and determine/know what number of SQL statements SQL Server is capable of processing on a regular basis without affecting the performance. That magical number could be 500, 2,000, 5,000, 10,000 or even more, but the DBA must know that number to understand and interpret the metric.
The metric value doesn’t mean anything by itself. Having high Batches Requests/sec values is a good thing as long as the server performance is not affected. What’s more, the goal of any SQL Server design is to accomplish the highest possible Batch Requests/sec while maintaining the resources such as CPU, I/O or Memory to an acceptable level, meaning that SQL Server is well optimized. To illustrate this with an example: having 5,000 Batches Requests/sec measured on SQL Server means nothing unless the DBA knows that the value during the normal day is 500.
Having said that, it is vital not to jump into conclusion that something wrong happens just because the Batch Requests/sec value is “high”. To summarize:
Another important point when monitoring Batch Requests/sec is that regardless of how many statements contained in a single SQL batch are executed, the Batch Request/Sec registers that as a single batch and adds the value of 1. So, if we have a situation where three complex stored procedures with multiple statements each are executed simultaneously, the value for Batch Requests/sec will be 3, regardless of how many statements those three procedures executed. Therefore, for SQL Servers that are based on significant and complex SQL batches, Batch Requests/sec metric is probably not the best way to determining how busy SQL Server is
The Batch Requests/sec metric is part of the SQLServer:SQL Statistics (MSSQL$ :SQL Statistics for a named instance) performance object
To monitor this counter, open performance monitor (PerfMon) and click on the Add counters button. In the Add counters dialog, locate the SQLServer:SQL Statistics performance object and expand it

Locate the Batch Requests/sec metric and add it for monitoring

After the OK button is pressed, Batch Requests/sec monitoring starts

Transactions/sec performance metric
The Transactions/sec (in some literature referred as Transactions per Second) performance metric is a database level metric designed to track down SQL Server statements folded inside a SQL transaction. All explicit transactions (statement explicitly started BEGIN TRAN) as well as all implicit transactions INSERT/UPDATE/SELECT) in SQL Server are treated as a transaction, and the transactions/sec metric will log all transactions except some related to row versioning and in-memory tables. While the Transactions/sec metric is officially measurement of transactions started for the particular database, but the way it is counted if a bit different and the metric value depends on another two factors: metric reading frequency and duration of the transaction. To explain that more precisely, it practically means that if the metric reading frequency is 1 second and the transaction running for 10 seconds, the metric will return the value of 10. Therefore, it means that the metric can count the single transaction multiple time if transaction duration is longer than the period of metric reading. Transaction per second is the so-called calculated metric, as SQL Server cumulatively counts SQL transactions, and the value is a difference between the last and the precious reading divided with the period of reading
Transactions/sec= (Last transaction number – Previous transaction number)/Number of seconds between two readings
When transferred into numbers:
Last transaction number = 1000
Previous transaction number = 500
Number of seconds between two readings = 5
Transactions/sec= (1000-500)/5 = 100
The number of SQL Server transactions depend significantly on global system performance but also on some system resources such as a number of connected users, the system I/O capacity, available memory cache, and statements complexity.
Transactions/sec metric is not one of those where determining that value is too high or too low is possible using some rule of thumb. The value that this metric return is of a relative nature, which mean that proper interpretation of the metric value would be a “(much) higher than yesterday or last week” or a “(much) lower than yesterday or last week.”. Having a high value of the Transactions/sec metric is only an indication SQL Server activity amount, not necessarily an indication of a problem. So, the best practice in monitoring this metric is establishing the baseline that could then be used to determine when the metric have oddly high or low values
The Transactions/sec metric is part of the SQLServer:Databases (MSSQL$ :Databases for a named instance) performance object
To monitor this counter, open performance monitor (PerfMon) and click on the Add counters button.

In the Add counters dialog, locate the SQLServer:Databases performance object and expand it. Locate the Transactions/sec metric, then select the database instance to be measured and then add the metric for monitoring


Batch Requests/sec vs. Transactions/sec
When it comes to maintaining SQL Server, it is essential for a DBA to know what the amount of throughput that the SQL Server is capable of processing. More precisely, what number of SQL queries and SQL transactions can the SQL Server process. While both metrics are essential indicators of SQL Server workload (amount of work that SQL Server performs), they are often misinterpreted due to insufficient knowledge of the very essence of metrics. As most database-related metrics do not see a many of stuff that occurs on SQL Server, Transactions/sec is no exemption.
Most experienced DBAs first instinct is to inspect the Batch Request/sec metric as a primary indicator of the workload, and that is not by accident. The Batch Requests/sec is a preferred metric as it can, in most cases, provide more reliable information about the SQL Server workload. All squares are parallelograms, but not all parallelograms are squares; a similar analogy could be established for those two metrics as much higher number of statements qualifies as batches than as transactions. Because of that, Transactions/sec has a “blind spot,” and that will be elaborated with a practical example
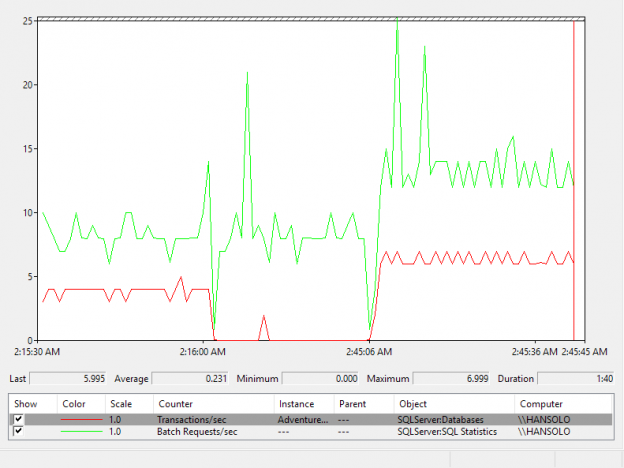
To demonstrate this, perform a test using a few simple queries and Performance monitor:
Use the AdventureWorks database for this demonstration
Start the Performance Monitor and add Batch Requests/sec and Transactions/sec (for AdventureWorks database) metrics

Run SQL Server Management Studio (SSMS) and connect to SQL Server. Open the new query tab and set the query context to AdventureWorks database. Use the query below
[ELMA3] Рекомендации по обслуживанию и настройке серверов MSSQL Server
Данная статья содержит в себе следующую информацию:
1. Обновление экземпляра MSSQL Server
Необходимо постоянно контролировать и обновлять экземпляр MSSQL Server для закрытия уязвимостей и обновления движка Database Engine. Для этого необходимо выполнить ряд действий.
1. Уточнить установленную редакцию и версию экземпляра сервера, установленного у нас:

2. Перейти на сайт https://technet.microsoft.com/ru-ru/sqlserver/ff803383.aspx и просмотреть доступные обновления для установленной версии экземпляра сервера. В большей степени нас интересуют:
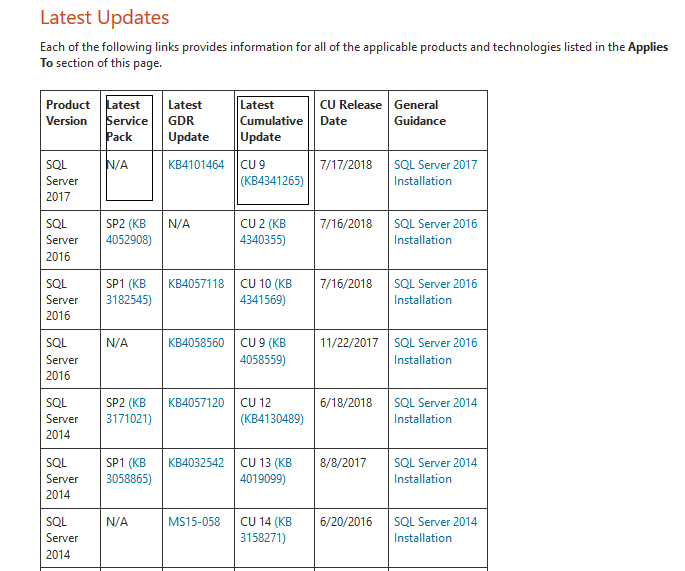
3. Если таковые доступны, то необходимо скачать и установить их. Процесс установки стандартный: требуется запустить exe-файл и установить обновления для выбранного экземпляра MSSQL Server.
2. Плановые работы по обслуживанию индексов (реорганизация/перестроение) и обновлению статистики
Для поддержания производительности Базы данных необходимо проводить плановую периодическую реорганизацию/перестроение индексов. В противном случае можно получить «performance degradation» (падение производительности) для базы в целом.
Для начала необходимо проверить наличие и степень фрагментации индексов в используемой базе. Для этого требуется выполнить следующий код:
Результат выполнения кода представлен на рисунке ниже:
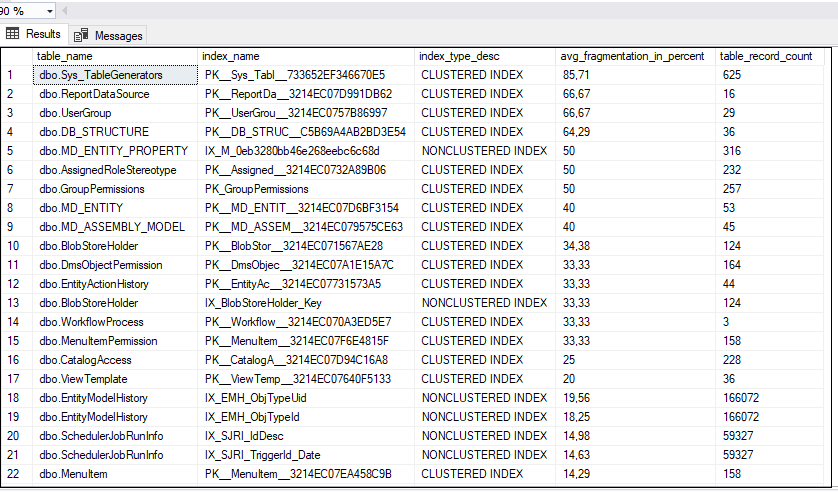
Где: table_name – имя таблицы, index_name – имя индекса, index_type_desc – тип индекса, avg-fragmentation_in_percent – степень фрагментации индекса, table_record_count – количество записей в таблице.
Дальше следует на постоянной основе обслуживать индексы и следить за их фрагментацией. В этом случае можно воспользоваться штатными средствами MSSQL Server (Создать план обслуживания – доступен для редакций Standart, Enterprise, но недоступен для редакции Express). Создать план обслуживания с необходимыми задачами по проверке целостности базы и реорганизации/перестроению индексов, там же назначить время и периодичность выполнения для данных задач.
Также можно воспользоваться прекрасным средством – скриптами https://ola.hallengren.com/, получившими мировое признание и использующимися большинством DBA в своей повседневной работе по обслуживанию БД. Для этого необходимо:
1. Скачать с официально сайта необходимый нам скрипт.
2. После скачивания запустить его и выполнить в среде Management Studio. Скрипт инициализируется и создает несколько необходимых нам хранимых процедур.
После этого нам остается настроить необходимые нам «джобы» (job – задание) и поставить в них время выполнения и периодичность, либо создать план обслуживания, в котором указать созданные джобы.
Скрипты ola.hallengren.com позволяют автоматизировать процесс реорганизации/перестроения индексов. При этом при выполнении задания автоматически проверяется степень фрагментации индексов: если она составляет 15-30%, делается реорганизация; если больше 30%, то перестроение (при этом регулируется нагрузка на БД).
Также с помощью уже других скриптов можно проверять целостность базы данных, а также настраивать автоматическое резервное копирование, что тоже очень полезно и просто необходимо. Все параметры можно гибко конфигурировать в самом скрипте.
Ниже приведен небольшой пример создания задания.
Создаем Job (задание) в MSSQL Server.
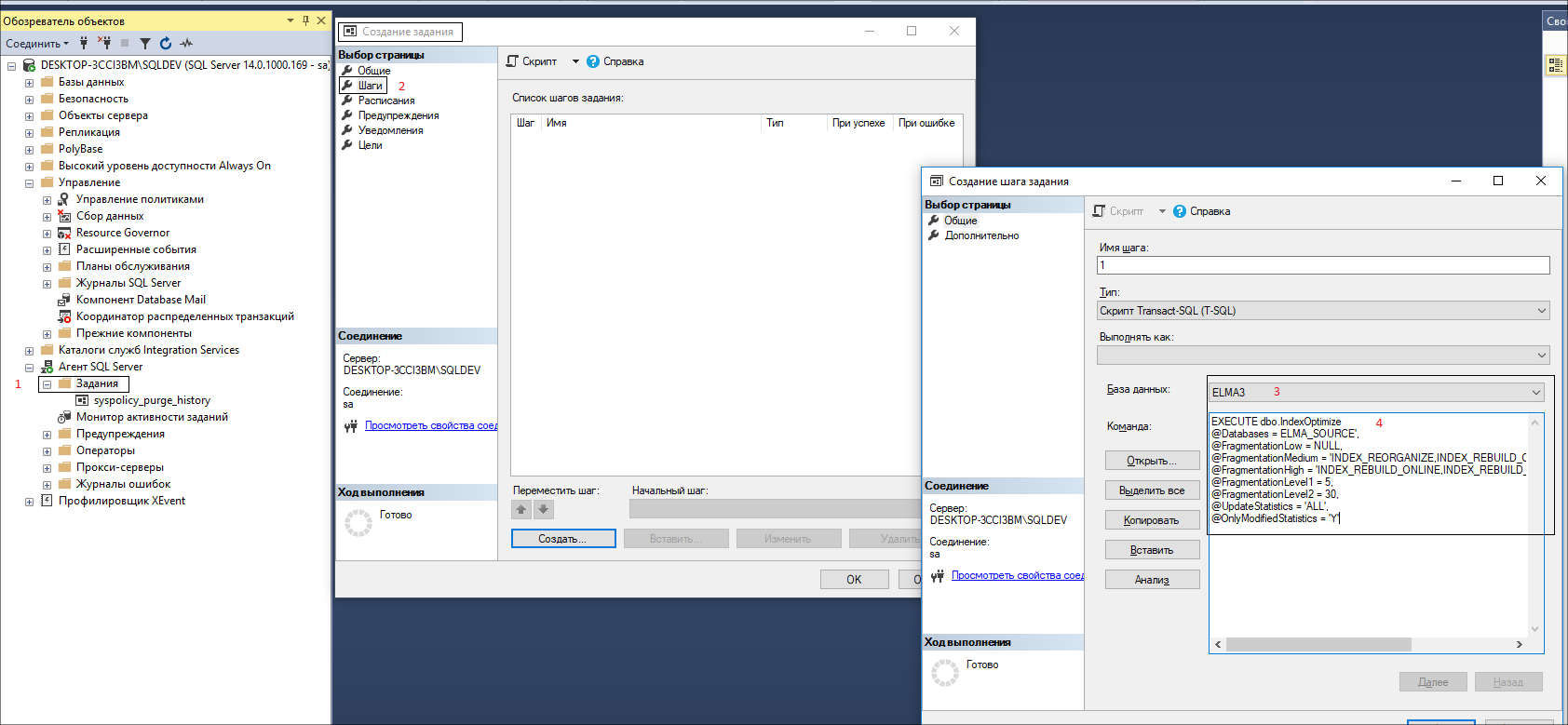
Мы создали задание и написали скрипт для реорганизации/перестроения индексов.
То же самое можно написать для проверки целостности базы данных.
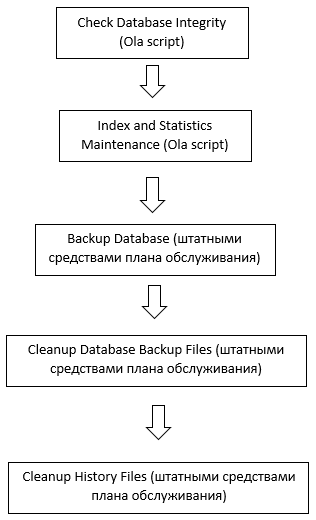
То же самое можно сделать и для резервного копирования. Примеры скриптов доступны на сайте ola.hallengren.com. После этого необходимо запустить задание, поставить для него время и периодичность выполнения, либо использовать план обслуживания, где выбирать созданные задания и сохранить их. Например, может быть использован следующий план, созданный с помощью плана обслуживания еженедельно по воскресеньям.
3. Советы по тонкой настройке и оптимизации баз данных MSSQL Server
В процессе установки экземпляра MSSQL Server необходимо устанавливать только те компоненты, которые действительно необходимы. Здесь можно действовать по принципу – чем меньше, тем лучше, недостающие компоненты всегда можно установить дополнительно.
Путь к папке с экземпляром сервера требуется оставлять по умолчанию, как и место хранения системных баз данных (master, model, msdb). Например:
С:\Program Files\Microsoft SQL Server\MSSQL14.SQLEXPRESS\MSSQL\DATA\
где папка MSSQL14.SQLEXPRESS является папкой экземпляра сервера.
Пользовательские базы данных необходимо переносить на другой диск. Хорошим тоном является создание 3 логических дисков, на каждом из которых помещается основной файл базы данных, на другом – файл журнала транзакций, на 3 – база данных tempDB.
Если позволяют системные ресурсы, в идеальной ситуации файл базы данных, журнал транзакций и база данных tempDB должны находится на разных физических дисках для увеличения производительности.
Для самого экземпляра MSSQL Server по возможности следует выделять отдельный сервер! Либо, если используется виртуализация, выделять отдельную виртуальную машину.
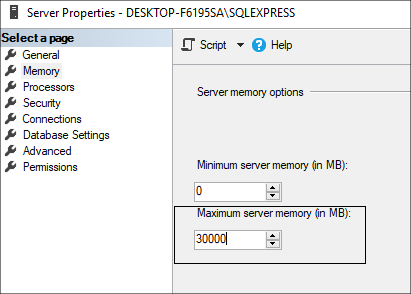
У установленного экземпляра MSSQL Server в настройках сервера обычно задается предел Maximum server memory, а не оставляется динамическое значение по умолчанию. Например, если сервер выделен под экземпляр MSSQL Server и на нем установлено 32 Гб оперативной памяти, можно поставить фиксированное значение в 30 Гб и 2 Гб оставить под операционную систему с антивирусными программами.
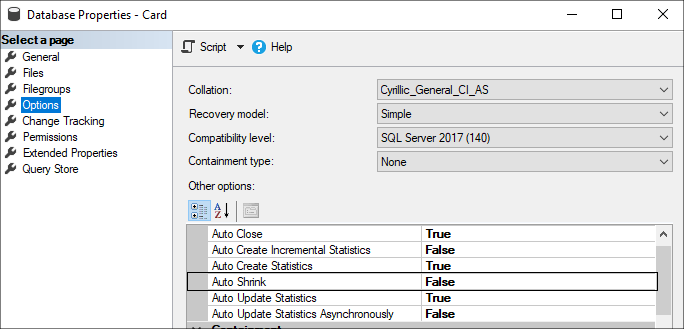
Также необходимо обязательно следить за тем, чтобы в настройках Базы данных была отключена опция Автоматического сжатия файла базы данных (Auto Shrink), которая может оказать серьезное воздействие на производительность базы в целом.
Также необходимо контролировать лог журнала транзакций, который, в свою очередь, может оказывать воздействие на падение производительности. Когда размер журнала транзакций больше размера файла данных, это уже плохо и нужно предпринимать меры.
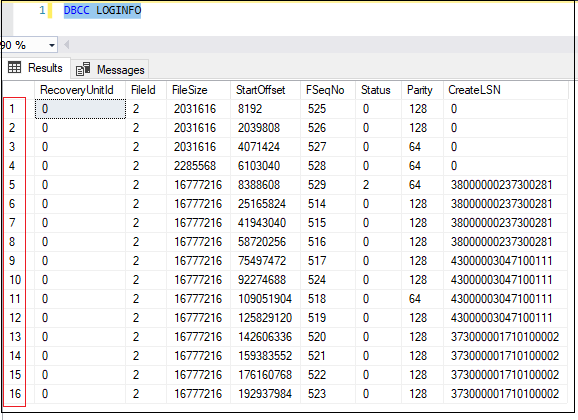
Любой журнал транзакций содержит в себе файлы виртуальных журналов транзакций, так называемые VLF. Чем больше VLF, тем хуже для журнала транзакций. По «Best Practice» количество VLF не должно превышать 50. В случае, если журналы транзакций превышает 1000 и более VLF необходимо предпринимать меры для уменьшения и последующего поддержания виртуальных файлов журналов транзакций в норме, не допуская выхода за границы. Посмотреть текущее количество файлов виртуальных журналов транзакций можно командой DBCC LOGINFO.
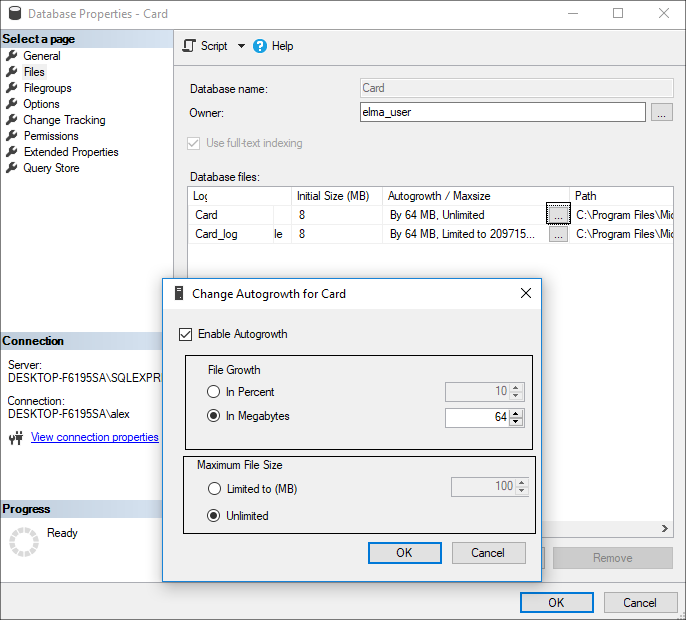
Причиной также может быть маленький размер автоприращения файла лога журнала транзакций, вследствие чего при записи данных в лог журнала транзакций создаются новые порции виртуальных журналов транзакций. Изменить размер автоприращения можно в свойствах базы данных на вкладке Файлы.
Либо Transact SQL инструкциями:
В данном случае задано приращение в 1 ГБ. Также приращения и размеры лучше задавать предельным значением, а не процентами.
4. Работа со счетчиками производительности Performance Counter для выявления и устранения проблем, связанных с производительностью экземпляра сервера
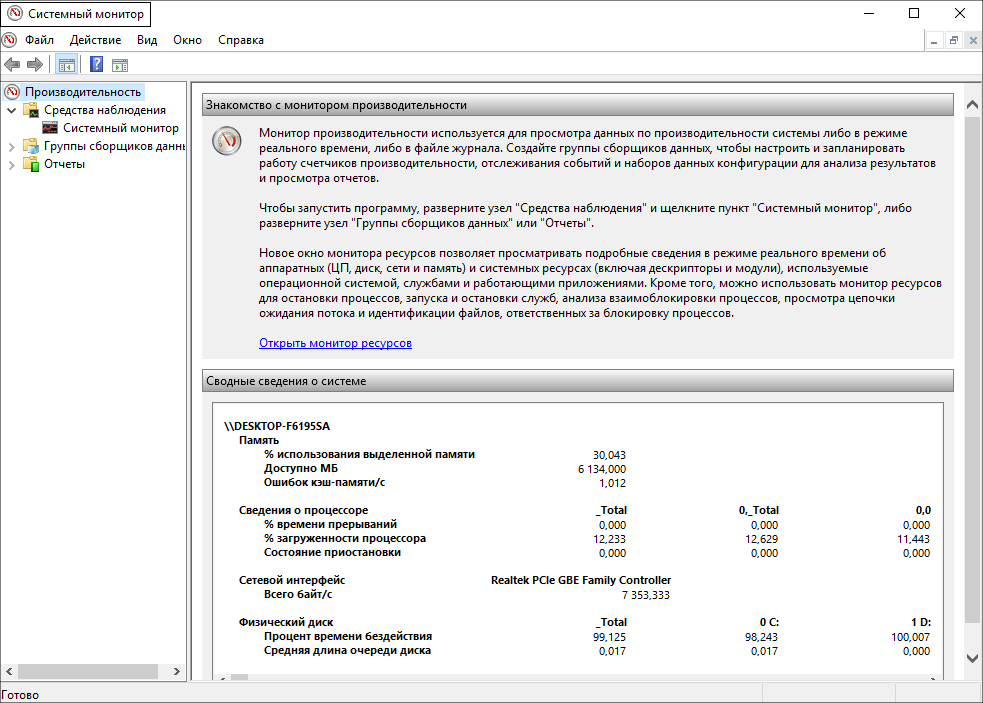
Одну из главных ролей стабильной работы MSSQL сервера является постоянный мониторинг и выявление причин падения производительности (performance degradation) и поиска узких мест (bottlenecks). В решении этих проблем помогают счетчики производительности Performance Counter (доступны по умолчанию в Windows). Счетчики производительности позволяют собирать информацию в виде графиков с историей хранения значений, позволяют отслеживать значения в режиме реального времени, а также смотреть историю значений, делать сопоставления, возвращаться к архивным данным. Для более удобной работы со счетчиками производительности можно использовать сторонние системы мониторинга, например, Zabbix.
Стандартные счетчики Windows доступны по умолчанию и помогают отслеживать такие важные показатели, как загрузку процессора, использование памяти и загрузку дисковой системы, своевременно выявлять узкие места в работе сервера. При установке экземпляра MSSQL Server также добавляются специализированные счетчики MSSQL Server, необходимые для мониторинга самого MSSQL Server.
Посмотрим на примере.
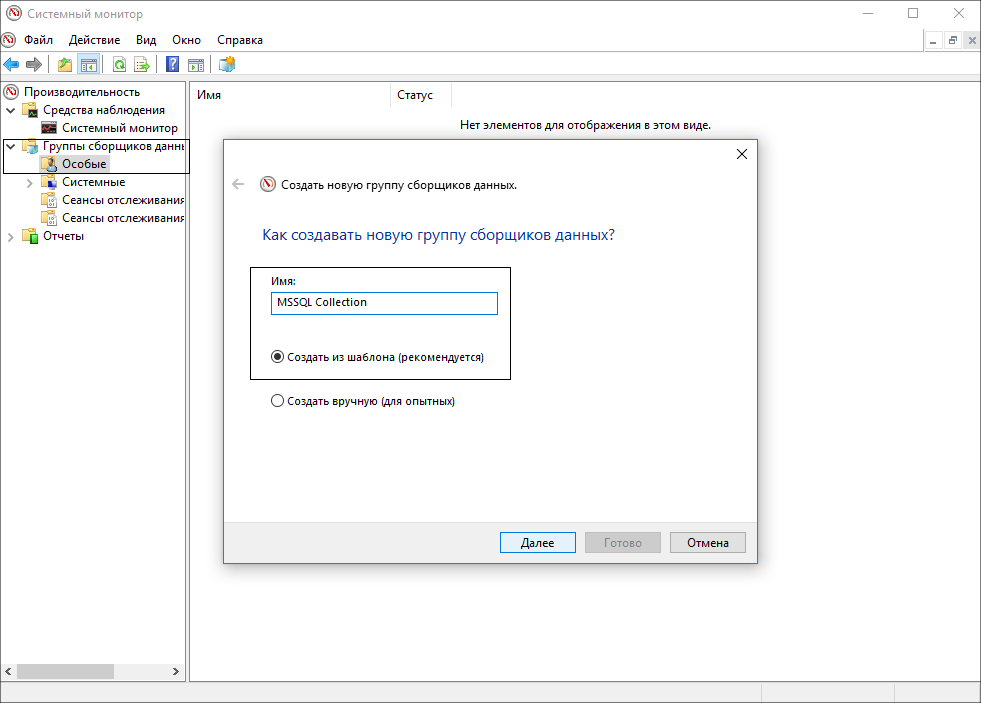
Добавляем необходимые счетчики для отслеживания.
В данном случае они выглядят так: системные + счетчики MSSQL Server. В идеальном случае нужно, чтобы счетчики отображались по-английски, все названия, рекомендованные значения – тоже представлены на английском языке. Русские названия могут вызвать путаницу.
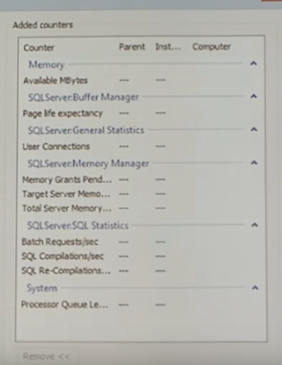
Ниже приведены «Best Practice» счетчиков производительности, которые были использованы для мониторинга систем:
Свободная память в мегабайтах. Когда данный счетчик показывает значение меньше 200 Мегабайт, нужно задуматься о том, что есть проблемы с памятью.
Avg.Disc sec/Read _Total
Avg.Disc sec/Write _Total
Счетчик производительности PhysicalDisk(_Total) \Avg. Disk sec/Read (Время в секундах, в среднем затрачиваемое на одну операцию чтения данных с диска. Показывает среднее время выполнения операции чтения с диска).
Предельно допустимые значения не должны превышать 15-20 Миллисекунд.
Счетчик производительности PhysicalDisk(_Total) \Avg. Disk sec/Write (Среднее время записи на диск в секундах — это время, в среднем затрачиваемое на одну операцию записи данных на диск).
Предельно допустимые значения не должны превышать 15-20 Миллисекунд.
%Processor Time _Total
Среднее время загрузки процессора (как в общем, так и по ядрам в отдельности). Смотрим, на сколько загружен у нас процессор, и определяем, является ли он узким местом в работе всего сервера.
SQLServer Buffer Manager
Page life expectancy
Buffer Cache Hit Ratio
Счетчик производительности SQL Server: Buffer Manager: Buffer Cache hit ratio (Доля страниц, обнаруженных в буферном кэше без чтения с диска). Эталонное значение > 90 (опять же указывает на проблемы с памятью).
Счетчик производительности SQL Server: Buffer Manager: Page life expectancy (указывает среднее время жизни страниц в буферном кэше). Чем больше, тем лучше. Предельное значение – 300. PLE именно тот счетчик, за которым надо следить, но его показания имеют смысл, если они падают значительно ниже нормы ( 2, может свидетельствовать о перегруженности процессора.
Список основных счетчиков производительности и их рекомендованные значения можно посмотреть также на сайте Microsoft, либо в независимых источниках.
После создания и запуска сборщика данных, следует собрать показания счетчиков, параллельно в системном мониторе можно просматривать отчеты по всем счетчикам, либо для лучшего наглядного представления перевести все на систему мониторинга – Zabbix.
Еще одной особенностью и несомненным плюсом является то, что собранные метрики, находящие по пути c:\PerfLogs\Admin\MSSQL Collection\DESKTOP-F6195SA_20180802-000001\Счетчик производительности.blg, можно наложить на собранные трассировки MSSQL Server Profiler. Это дает возможность сопоставить запросы или хранимые процедуры с графической составляющей сборщика данных для понимания того, какие ресурсы использовались и с какой степенью загрузки при выполнении запроса или хранимой процедуры. Выглядит это следующим образом:



