Как получить и измерить высокоскоростное соединение по TCP
1) Ограничения TCP
Скорость передачи данных зависит от сетевых и системных характеристик. 
img1 Процесс передачи данных по сети
a) Буферы
Оригинальная конфигурация TCP ограничивает скорость передачи буфером (опция Window Size — «размер окна») и является полем размером в 2^16 байт (до 64 КБайт). Максимальная пропускная способность в данном случае:
Пример: У вас 100 мегабитное соединение к Интернету и до сервера задержка 100 мс.
Стандартным стеком TCP, максимальная скорость передачи данных не превысит 10 Мбит/сек
( 524288 бит / 0.1 сек = 5.24 Мбит/сек не смотря на то что у вас 100 мегабитный линк).
b) Bandwidth-delay product (BDP)
Производительность TCP в принципе не столько зависит от скорости канала, сколько от так называемом «bandwidth*delay product» или BDP (результат пропускная способность*задержка), который представляет собой число байт необходимых отправителю и получателю для максимального заполнения TCP соединения.
Проблемы производительности возникают в случаях так называемых «длинных и широких труб» (LFN «long fat network»), так как BDP в таком случае превышает размер окна TCP, тем самым ограничивая скорость передачи.
img2 Влияние задержки на максимальную пропускную способность TCP
Примером могут служить мобильный интернет или быстрый оптический линк.
Пример расчетов BDP:
a) широкополосный мобильный интернет: 10 Mb/s, 100 ms RTT
B×D = 10^7 b/s × 10^-1 s = 10^6 b, or 1 Mb / 125 kB
b) высокоскоростная наземной сеть: 1 Gb/s, 10 ms RTT
B×D = 10^9 b/s × 10^-2 s = 10^7 b, or 10 Mb / 1.25 MB
Рассчитать BDP можно тут.
”Размер окна” TCP должен превышать BDP для достижение максимальной нагрузки канала.
c) Protocol Overhead
По некоторым оценкам около 95% компьютеров мира подключены через технологию Ethernet.
Ethernet MTU (полезная нагрузка кадра Ethernet) = макс. 1500 bytes.
Если принять во внимание все заголовки Ethernet, IP, TCP, картина будет выглядеть так:
img3 Передача одного Ethernet кадра
Цифры указывают размер (в байтах) заголовка для определенного протокола.
IFG (Interframe gap) — обязательное межкадровое пространство.
Заголовки: preamble, frame delimiter, Ethernet header/FCS – 26 bytes, IFG – 12 bytes, IP header – 20 bytes, TCP header – 20 bytes.
Если исключить VLAN tagging, TCP timestamp и другие опциональные возможности, максимальная полезная нагрузка (Payload) TCP в сетях Ethernet будет:
Max TCP Payload= (MTU–TCP–IP) / (MTU+Ethernet+IFG) = (1500–40) / (1500+26+12) = 94.9 %
d) Задержка и потеря пакетов
Так как речь идет о надежной передачи информации, потеря пакетов в сети вынуждает TCP передавать повторно сегменты и влияет непосредственно на понижение скорости.
Зависимость скорости TCP в соотношении к потери пакетов, определяется формулой Mathis-а:
где: MSS (Maximum segment size) – максимальный размер сегмента TCP (MSS = MTU – packet headers=1460 bytes),
MTU — максимальный размер передаваемого блока нижнего уровня OSI (Ethernet MTU = 1500 bytes),
RTT — время двусторонней задержки (от одного конца к другому и назад, от англ. Round Trip Time)
Ploss — Loss probability (вероятность потерь).
Можно обратить внимание что формула не действительна с Ploss = 0. Это нормально, так как в реальном мире всегда есть потери пакетов.
img4 Влияние задержки и потеря пакетов на максимальную пропускную способность TCP
Большинство провайдеров не будет гарантировать потери менее 0.01% (1 пакет из 10`000).
Проверить статистику по протоколам можно командой “netstat –s”.
2) Оптимизация TCP
a) усовершенствования протокола
В связи с этим были разработаны расширения протокола, описанные в стандарте TCP Extensions for High Performance (RFC1323), которые призваны решить ограничения.
Среди них:
— TCP Window Scale Option: возможность увеличение Размера Окна до 2^30 (1 ГБайт),
— TCP selective acknowledgment (SACK) options: принимающая сторона указывает какие именно пакеты в потоке подтверждены (положительно или отрицательно) (RFC2018),
— TCP timestamps: улучшение замеров RTT (Round Trip Time Measurement — RTTM), предотвращение накладки порядковых чисел ACK (Prevention Against Wrapped Sequence numbers — PAWS),
— Path MTU discovery: определение максимального MTU на всем пути,
— Explicit Congestion Notification (ECN): указывает на перегрузку пути без сбрасывание пакетов (RFC3168).
Проверить текущие настройки TCP/IP компьютера можно здесь.
b) aдаптация oперационных систем
Несмотря на то что документ RFC1323 был опубликован в далеком 1992 году, в ОС-ы внедряли изменения не сразу.
OS Windows
Поддержка RFC1323 появилась начиная с Windows 2000 (XP, Server 2003) и для активации опции необходимо покрутить в реестре.
Системы Windows Server 2008, Vista, 7 включают новую реализацию стека протоколов TCP/IP, известную как стек протоколов TCP/IP нового поколения («Next Generation TCP/IP Stack»). Он спроектирован для того, чтобы обеспечивать сетевые технологии Windows на несколько лет вперед. Среди нововведений:
— aвтонастройка окна получения (Receive Window Auto-Tuning),
— compound TCP: решает проблему низкой производительности в сетях с высокой пропускной способностью с помощью нового алгоритма, вместо алгоритмов, использовавшихся на других платформах,
— усовершенствования для сред с высоким уровнем потерь и еще много чего.
Многие опции включены по умолчанию. Конфигурация через командную строку.
С подробными процедурами настройки для различных ОС (Windows XP, FreeBSD, Linux, Solaris, Mac OS X), можно ознакомится на сайте суперкомпьютерного центра Питтсбурга.
Примечание: Хотя через маршрутизаторы в основном проходит весь трафик (между разными сетями), отношение к оптимизации TCP имеют только косвенное (в некоторых случаях), так как работают на более нижнем уровне сетевой модели OSI и выполняют функцию определение оптимальных маршрутов и лишь доставку пакетов до назначения.
3) Измерения производительности стека TCP/IP
В сети существуют множество методов измерения скорости подключения к Интернету.
Здесь будет рассмотрен случай с использованием утилиты nuttcp («New TTCP»), так как она имеет несколько приятных преимуществ:
— простой и эффективный метод измерения пропускной способности канала через TCP или UDP,
— кроссплатформенная одно-файловая программа (CLI),
— возможность проверки эффективности локального стека TCP/IP (loopback),
— стабильная работа сервера (корректное завершения TCP сессий), без подвисаний и падений
(как в случае с iperf),
— работа клиента из NAT-а.
Немного истории: В 1980 году, Mike Muuss (автор ping-а) создал ttcp («Test TCP») — один из первых инструментов тестирования пропускной способности TCP. Многие изменения с тех пор были созданы в различных реализациях и с новыми возможностями. Nuttcp является одной из них. Последняя бета — апрель 2010.
Тестирования работает по схеме клиент-сервер.
Измеряется payload — полезная нагрузка (без заголовков).
Подключение по порту 5000. Передача данных — 5001 (и выше если указать многопоточный тест).
Пример:
Сервер FreeBSD, клиент Windows XP SP3, FastEthernet (100Mbps).
server-ip# nuttcp –S
опции клиента:
-w128 — TCP receive window size = 128 KB
-r — receiving (прием, для клиента)
-F — устраняет возможные проблемы с соединением если вы в NAT-е
-i5 — показывать результат каждые 5 секунд
-T15 — длительность тестирования (15 секунд).
TX% и RX% являются загрузкой процессора на передатчике и приемнике.
Примеры результатов:
— Intel Core 2 Duo (2 core) @ 1.6 GHz/ 1 GB RAM / Windows XP = 1300/1400 Mbps
— AMD Athlon X2 Dual-Core 4600 @ 2.4 GHz/ 2 GB RAM / Windows 7 = 2000/2100 Mbps
— Intel XEON X5650 (24 cores) @ 2.67GHz/ 8 GB RAM / FreeBSD = 16600/18000 Mbps
168.2676 MB / 15.00 sec = 94.1020 Mbps 3 %TX 10 %RX
1371.1741 MB / 15.00 sec = 766.6703 Mbps 26 %TX 39 %RX 3153 host-retrans 0.29 msRTT
167.2500 MB / 15.12 sec = 92.7664 Mbps 17 %TX 6 %RX
1305.3853 MB / 15.06 sec = 727.0077 Mbps 20 %TX 48 %RX 24478 host-retrans 0.29 msRTT
4) Вместо заключения
200 км/мс),
— дополнительные задержки могут возникнуть в момент перегрузки сети или устройства (сервер, рутер, пк),
— автоматическое понижение скорости при обнаружении потерь пакетов (стандартный механизм TCP предотвращения перегрузок),
— отсутствие других негативных эффектов (минимальное количество ошибок битов на физическом уровне (Bit Error Rate
TCP Bandwidth Delay Product
интегральный показатель задержки передачи
TCP Bandwidth Delay Product Limiting похоже на TCP/Vegas в NetBSD. Оно может быть включено установкой переменной sysctl net.inet.tcp.inflight_enable в 1. Система попытается вычислить задержку пакетов для каждого соединения и ограничить объем данных в очереди сети до значения, требуемого для поддержания оптимальной пропускной способности.
Эта возможность полезна при передаче данных через модемы, Gigabit Ethernet, или даже через высокоскоростные WAN соединения (или любые другие соединения с большой задержкой передачи).
[http://www.morepc.ru/dict/]
Тематики
Смотреть что такое «TCP Bandwidth Delay Product» в других словарях:
Bandwidth-delay product — In data communications, bandwidth delay product refers to the product of a data link s capacity (in bits per second) and its end to end delay (in seconds). The result, an amount of data measured in bits (or bytes), is equivalent to the amount of… … Wikipedia
TCP tuning — techniques adjust some parameters of TCP connection over high bandwidth high latency networks. Well tuned networks can perform up to 1000 times faster in some cases. [ [http://www.psc.edu/networking/projects/hpn ssh/ High Performance Enabled… … Wikipedia
TCP Westwood — (TCPW), is a sender side only modification to TCP NewReno that is intended to better handle large bandwidth delay product paths (large pipes), with potential packet loss due to transmission or other errors (leaky pipes), and with dynamic load… … Wikipedia
TCP Offload Engine — or TOE is a technology used in network interface cards to offload processing of the entire TCP/IP stack to the network controller. It is primarily used with high speed network interfaces, such as gigabit Ethernet and 10 gigabit Ethernet, where… … Wikipedia
TCP window scale option — The TCP window scale option is an option to increase the TCP receive window size above its maximum value of 65,536 bytes. This TCP option, along with several others, is defined in IETF RFC 1323 which deals with Long Fat networks, or LFN.In fact,… … Wikipedia
Compound TCP — (CTCP) is a Microsoft algorithm that was introduced as part of the Windows Vista and Window Server 2008 TCP stack. It is designed to aggressively adjust the sender s congestion window to optimise TCP for connections with large bandwidth delay… … Wikipedia
H-TCP — is another implementation of TCP with an optimized congestion control algorithm for high speed networks with high latency (LFN: Long Fat Networks). It was created by researchers at the Hamilton Institute in Ireland.H TCP is an optional module in… … Wikipedia
интегральный показатель задержки передачи — TCP Bandwidth Delay Product Limiting похоже на TCP/Vegas в NetBSD. Оно может быть включено установкой переменной sysctl net.inet.tcp.inflight enable в 1. Система попытается вычислить задержку пакетов для каждого соединения и ограничить объем… … Справочник технического переводчика
Taxonomy of congestion control — refers to grouping congestion control algorithms according to their characteristics.Example classificationThe following is one possible classification according to the following properties: #The type and amount of feedback received from the… … Wikipedia
Network performance — refers to the service quality of a telecommunications product as seen by the customer. It should not be seen merely as an attempt to get more through the network. The following list gives examples of Network Performance measures for a circuit… … Wikipedia
Network congestion — In data networking and queueing theory, network congestion occurs when a link or node is carrying so much data that its quality of service deteriorates. Typical effects include queueing delay, packet loss or the blocking of new connections. A… … Wikipedia
Внутренние механизмы ТСР, влияющие на скорость загрузки — часть 2
Медленный старт (Slow-Start)
Несмотря на присутствие контроля потока в TCP, сетевой коллапс накопления был реальной проблемой в середине 80-х. Проблема была в том, что хотя контроль потока не позволяет отправителю «утопить» получателя в данных, не существовало механизма, который бы не дал бы это сделать с сетью. Ведь ни отправитель, ни получатель не знают ширину канала в момент начала соединения, и поэтому им нужен какой-то механизм, чтобы адаптировать скорость под изменяющиеся условия в сети.
Например, если вы находитесь дома и скачиваете большое видео с удаленного сервера, который загрузил весь ваш даунлинк, чтобы обеспечить максимум скорости. Потом другой пользователь из вашего дома решил скачать объемное обновление ПО. Доступный канал для видео внезапно становится намного меньше, и сервер, отправляющий видео, должен изменить свою скорость отправки данных. Если он продолжит с прежней скоростью, данные просто «набьются в кучу» на каком-то промежуточном гейтвэе, и пакеты будут «роняться», что означает неэффективное использование сети.
В 1988 году Ван Якобсон и Майкл Дж. Карелс разработали для борьбы с этой проблемой несколько алгоритмов: медленный старт, предотвращение перегрузки, быстрая повторная передача и быстрое восстановление. Они вскоре стали обязательной частью спецификации TCP. Считается, что благодаря этим алгоритмам удалось избежать глобальных проблем с интернетом в конце 80-х/начале 90-х, когда трафик рос экспоненциально.
Чтобы понять, как работает медленный старт, вернемся к примеру с клиентом в Нью-Йорке, пытающемуся скачать файл с сервера в Лондоне. Сначала выполняется трехходовый хэндшейк, во время которого стороны обмениваются своими значениями окон приема в АСК-пакетах. Когда последний АСК-пакет ушел в сеть, можно начинать обмен данными.
Единственный способ оценить ширину канала между клиентом и сервером – измерить ее во время обмена данными, и это именно то, что делает медленный старт. Сначала сервер инициализирует новую переменную окна перегрузки (cwnd) для TCP-соединения и устанавливает ее значение консервативно, согласно системному значению (в Linux это initcwnd).
Значение переменной cwnd не обменивается между клиентом и сервером. Это будет локальная переменная для сервера в Лондоне. Далее вводится новое правило: максимальный объем данных «в пути» (не подтвержденных через АСК) между сервером и клиентом должно быть наименьшим значением из rwnd и cwnd. Но как серверу и клиенту «договориться» об оптимальных значениях своих окон перегрузки. Ведь условия в сети изменяются постоянно, и хотелось бы, чтобы алгоритм работал без необходимости подстройки каждого TCP-соединения.
Решение: начинать передачу с медленной скоростью и увеличивать окно по мере того, как прием пакетов подтверждается. Это и есть медленный старт.Начальное значение cwnd исходно устанавливалось в 1 сетевой сегмент. В RFC 2581 это изменили на 4 сегмента, и далее в RFC 6928 – до 10 сегментов.
Таким образом, сервер может отправить до 10 сетевых сегментов клиенту, после чего должен прекратить отправку и ждать подтверждения. Затем, для каждого полученного АСК, сервер может увеличить свое значение cwnd на 1 сегмент. То есть на каждый подтвержденный через АСК пакет, два новых пакета могут быть отправлены. Это означает, что сервер и клиент быстро «занимают» доступный канал. 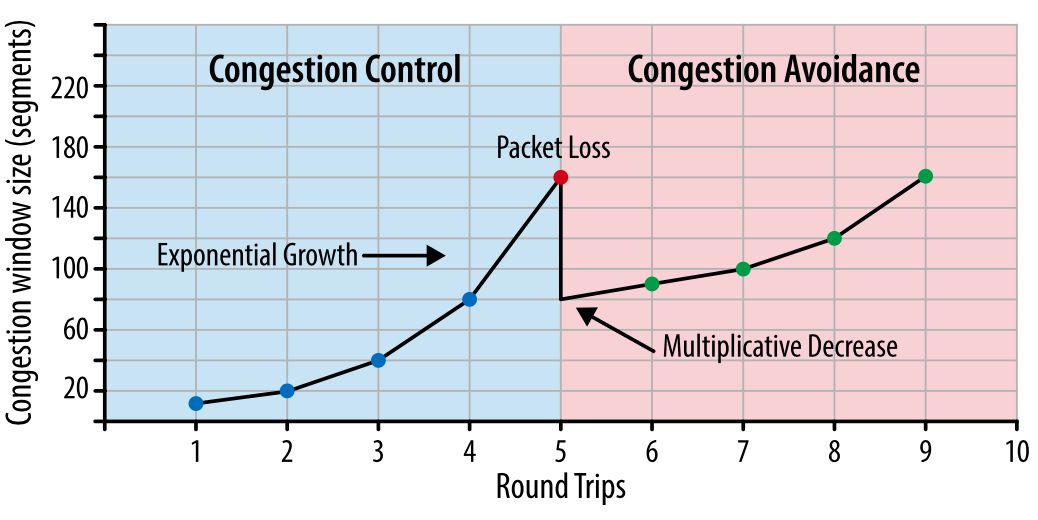 Рис. 1. Контроль за перегрузкой и ее предотвращение.
Рис. 1. Контроль за перегрузкой и ее предотвращение.
Каким же образом медленный старт влияет на разработку браузерных приложений? Поскольку каждое TCP-соединение должно пройти через фазу медленного старта, мы не можем сразу использовать весь доступный канал. Все начинается с маленького окна перегрузки, которое постепенно растет. Таким образом время, которое требуется, чтобы достичь заданной скорости передачи, — это функция от круговой задержки и начального значения окна перегрузки.
Время достижения значения cwnd, равного N.
 Тот факт, что клиент и сервер могут быть способны обмениваться мегабитами в секунду между собой, не имеет никакого значения для медленного старта.
Тот факт, что клиент и сервер могут быть способны обмениваться мегабитами в секунду между собой, не имеет никакого значения для медленного старта.
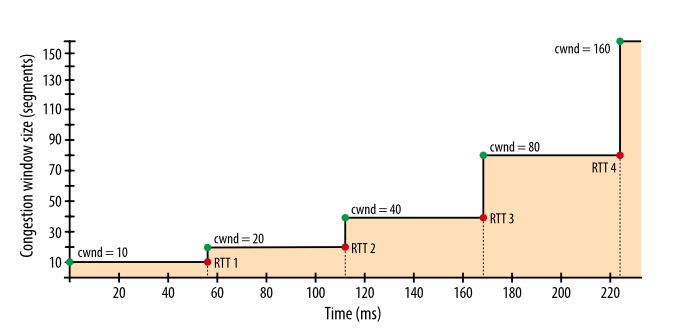 Рис. 2. Рост окна перегрузки
Рис. 2. Рост окна перегрузки
Чтобы уменьшить время, которое требуется для достижения максимального значения окна перегрузки, можно уменьшить время, требуемое пакетам на путь «туда-обратно» — то есть расположить сервер географически ближе к клиенту.
Медленный старт мало влияет на скачивание крупных файлов или потокового видео, поскольку клиент и сервер достигнут максимальных значений окна перегрузки за несколько десятков или сотен миллисекунд, но это будет одним TCP-соединением.
Однако для многих HTTP-запросов, когда целевой файл относительно небольшой, передача может закончиться до того, как достигнут максимум окна перегрузки. То есть производительность веб-приложений зачастую ограничена временем круговой задержкой между сервером и клиентом.
Перезапуск медленного старта (Slow-Start Restart — SSR)
Неудивительно, что SSR может оказывать серьезное влияние на производительность долгоживущих TCP-соединений, которые могут временно «простаивать», например, из-за бездействия пользователя. Поэтому лучше отключить SSR на сервере, чтобы улучшить производительность долгоживущих соединений. На Linux проверить статус SSR и отключить его можно следующими командами:
В обоих случаях тот факт, что клиент и сервер пользуются каналом с пропускной способностью 5 Мбит/с, не оказал никакого влияния на время скачивания файла. Только размеры окон перегрузки и сетевая задержка были ограничивающими факторами. Интересно, что разница в производительности при использовании нового и существующего TCP-соединений будет увеличиваться, если сетевая задержка будет расти.
Как только вы осознаете проблемы с задержками при создании новых соединений, у вас сразу появится желание использовать такие методы оптимизации, как удержание соединения (keepalive), конвейеризация пакетов (pipelining) и мультиплексирование.
Увеличение начального значения окна перегрузки TCP
Предотвращение перегрузки
Предотвращение перегрузки построено на предположении, что потеря пакета является индикатором перегрузки в сети. Где-то на пути движения пакетов на линке или на роутере скопились пакеты, и это означает, что нужно уменьшить окно перегрузки, чтобы предотвратить дальнейшее «забитие» сети трафиком.
После того как окно перегрузки уменьшено, применяется отдельный алгоритм для определения того, как должно далее увеличиваться окно. Рано или поздно случится очередная потеря пакета, и процесс повторится. Если вы когда-либо видели похожий на пилу график проходящего через TCP-соединение трафика – это как раз потому, что алгоритмы контроля и предотвращения перегрузки подстраивают окно перегрузки в соответствии с потерями пакетов в сети.
Стоит заметить, что улучшение этих алгоритмов является активной областью как научных изысканий, так и разработки коммерческих продуктов. Существуют варианты, которые лучше работают в сетях определенного типа или для передачи определенного типа файлов и так далее. В зависимости от того, на какой платформе вы работаете, вы используете один из многих вариантов: TCP Tahoe and Reno (исходная реализация), TCP Vegas, TCP New Reno, TCP BIC, TCP CUBIC (по умолчанию на Linux) или Compound TCP (по умолчанию на Windows) и многие другие. Независимо от конкретной реализации, влияния этих алгоритмов на производительность веб-приложений похожи.
Пропорциональное снижение скорости для TCP
Изначально в TCP применялся алгоритм кратного снижения и последовательного увеличения (Multiplicative Decrease and Additive Increase — AIMD): когда теряется пакет, то окно перегрузки уменьшается вдвое, и постепенно увеличивается на заданную величину с каждым проходом пакетов «туда-обратно». Во многих случаях AIMD показал себя как чрезмерно консервативный алгоритм, поэтому были разработаны новые.
Пропорциональное снижение скорости (Proportional Rate Reduction – PRR) – новый алгоритм, описанный в RFC 6937, цель которого является более быстрое восстановление после потери пакета. Согласно замерам Google, где алгоритм и был разработан, он обеспечивает сокращение сетевой задержки в среднем на 3-10% в соединениях с потерями пакетов. PPR включен по умолчанию в Linux 3.2 и выше.
Произведение ширины канала на задержку (Bandwidth-Delay Product – BDP)
BDP определяет, какой максимальный объем данных может быть «в пути»
Насколько же большими должны быть значения окон приема и перегрузки? Разберем на примере: пусть cwnd и rwnd равны 16 КБ, а круговая задержка равна 100 мс. Тогда: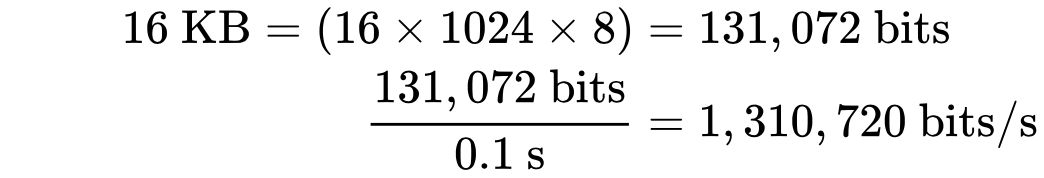 Получается, что какая бы ни была ширина канала между отправителем и получателем, такое соединение никогда не даст скорость больше, чем 1,31 Мбит/с. Чтобы добиться большей скорости, надо или увеличить значение окон, или уменьшить круговую задержку.
Получается, что какая бы ни была ширина канала между отправителем и получателем, такое соединение никогда не даст скорость больше, чем 1,31 Мбит/с. Чтобы добиться большей скорости, надо или увеличить значение окон, или уменьшить круговую задержку.
Похожим образом мы можем вычислить оптимальное значение окон, зная круговую задержку и требуемую ширину канала. Примем, что время останется тем же (100 мс), а ширина канала отправителя 10 Мбит/с, а получатель находится на высокоскоростном канале в 100 Мбит/с. Предполагая, что у сети между ними нет проблем на промежуточных участках, мы получаем для отправителя: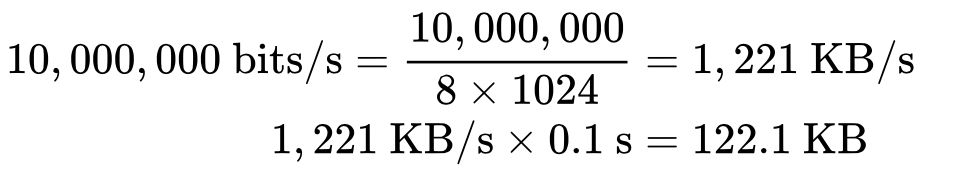 Размер окна должен быть как минимум 122,1 КБ, чтобы полностью занять канал на 10 Мбит/с. Вспомните, что максимальный размер окна приема в TCP равен 64 КБ, если только не включено масштабирование окна (RFC 1323). Еще один повод перепроверить настройки!
Размер окна должен быть как минимум 122,1 КБ, чтобы полностью занять канал на 10 Мбит/с. Вспомните, что максимальный размер окна приема в TCP равен 64 КБ, если только не включено масштабирование окна (RFC 1323). Еще один повод перепроверить настройки!
Хорошая новость в том, что согласование размеров окон автоматически делается в сетевом стэке. Плохая новость в том, что иногда это может быть ограничивающим фактором. Если вы когда-либо задумывались, почему ваше соединение передает со скоростью, которая составляет лишь небольшую долю от имеющейся ширины канала, это происходит, скорее всего, из-за малого размера окон.
BDP в высокоскоростных локальных сетях
Блокировка начала очереди (Head-of-line blocking – HOL blocking)
Каждый TCP-пакет содержит уникальный номер последовательности, и данные должны поступать по порядку. Если один из пакетов был потерян, то все последующие пакеты хранятся в TCP-буфере получателя, пока потерянный пакет не будет повторно отправлен и не достигнет получателя. Поскольку это происходит в TCP-слое, приложение «не видит» эти повторные отправки или очередь пакетов в буфере, и просто ждет, пока данные не будут доступны. Все, что «видит» приложение – это задержка, возникающая при чтении данных из сокета. Этот эффект известен как блокировка начала очереди.
Блокировка начала очереди освобождает приложения от необходимости заниматься упорядочиванием пакетов, что упрощает код. Но с другой стороны, появляется непредсказуемая задержка поступления пакетов, что негативно влияет на производительность приложений. 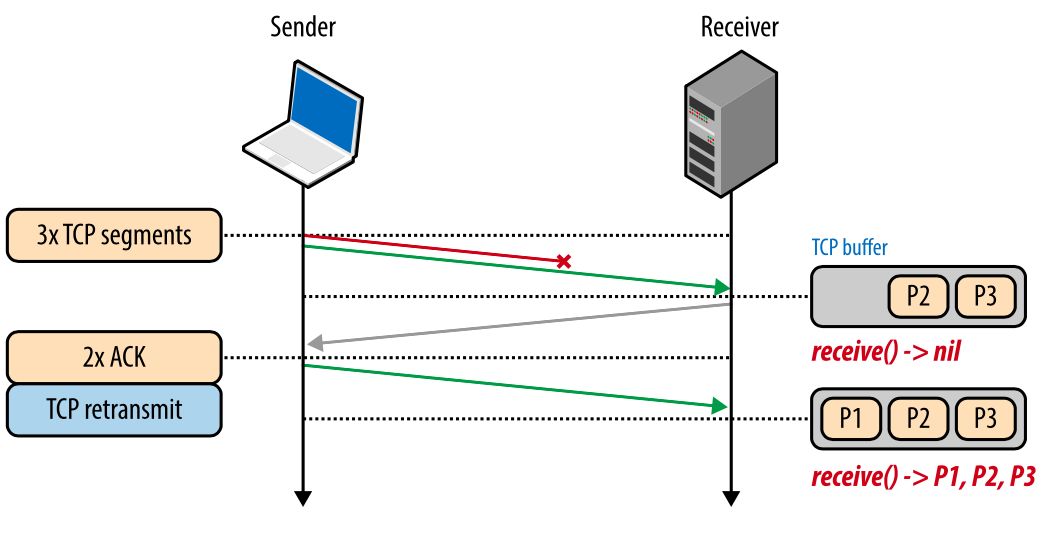 Рис. 6. Блокировка начала очереди.
Рис. 6. Блокировка начала очереди.
Некоторым приложениям может не требоваться гарантированная доставка или доставка по порядку. Если каждый пакет – это отдельное сообщение, то доставка по порядку не нужна. А если каждое новое сообщение перезаписывает предыдущие, то и гарантированная доставка также не нужна. Но в TCP нет конфигурации для таких случаев. Все пакеты доставляются по очереди, а если какой-то не доставлен, он отправляется повторно. Приложения, для которых задержка критична, могут использовать альтернативный транспорт, например, UDP.
Потеря пакетов – это нормально
Некоторые приложения могут «справиться» с потерей пакета: например, для проигрывания аудио, видео или для передачи состояния в игре, гарантированная доставка или доставка по порядку не обязательны. Поэтому WebRTC использует UDP в качестве основного транспорта.
Если при проигрывании аудио произошла потеря пакета, аудио кодек может просто вставить небольшой разрыв в воспроизведение и продолжать обрабатывать поступающие пакеты. Если разрыв небольшой, пользователь может его и не заметить, а ожидание доставки потерянного пакета может привести к заметной задержке воспроизведения, что будет гораздо хуже для пользователя.
Аналогично, если игра передает свои состояния, то нет смысла ждать пакет, описывающий состояние в момент времени T-1, если у нас уже есть информация о состоянии в момент времени T.
Оптимизация для TCP
Требования приложений и многочисленные особенности алгоритмов TCP делает их взаимную увязку и оптимизацию в этой области огромным полем для изучения. В этой статье мы лишь коснулись некоторых факторов, которые влияют на производительность TCP. Дополнительные механизмы, такие как выборочные подтверждения (SACK), отложенные подтверждения, быстрая повторная передача и многие другие осложняют понимание и оптимизацию TCP-сессий.
В результате скорость, с которой в TCP-соединении могут передаваться данные в современных высокоскоростных сетях зачастую ограничена круговой задержкой. В то время как ширина каналов продолжает расти, задержка ограничена скоростью света, и во многих случаях именно задержка, а не ширина канала является «узким местом» для TCP.
Настройка конфигурации сервера
«Обновить ОС на сервере» кажется тривиальным советом. Но на практике многие серверы настроены под определенную версию ядра, и системные администраторы могут быть против обновлений. Да, обновление несет свои риски, но в плане производительности TCP, это, скорее всего, будет самым эффективным действием.
Настройка приложения
Перенос данных поближе к клиентам посредством размещения серверов по всему миру либо с использованием CDN, поможет уменьшить круговую задержку и значительно повысит производительность TCP.
И наконец, во всех случаях, где это возможно, существующие соединения TCP должны использоваться повторно, чтобы избежать задержек, вызванных алгоритмом медленного старта и контроля перегрузки.



