Avx 512 что это
Специалисты ряда компьютерных изданий и рядовые обладатели новеньких Intel Core i7-11700K продолжают делиться с широкой общественностью результатами тестирования новинки в ряде прикладных и игровых приложений: так, буквально несколько часов назад стало известно о достаточно посредственных результатах представителя семейства Rocket Lake-S в ряде популярных игр, а также неоднозначных достижениях новинки в нескольких известных бенчмарках в сравнении с его главным конкурентом в лице AMD Ryzen 7 5800X, а уже сейчас свой вклад в освещение всех тонкостей касательно уровня производительности новой модели решили внести специалисты тестового пакета SiSoftware.
реклама
Источник изображения: Intel
Исследователи ресурса отмечают, что, помимо ряда архитектурных улучшений, наиболее значимым нововведением для десктопных моделей 11-го поколения стала поддержка набора инструкций AVX-512, в результате чего уровень производительности новинок в ряде задач существенно увеличился.
Действительно, если в арифметическом тесте процессора, в котором применяются операции с целыми числами и вычисления с плавающей запятой, Core i7-11700K всего лишь на 7-13 % быстрее представителя семейства Coffee Lake Refresh в лице Core i9-9900K и медленнее своего соперника из стана AMD, представленного 8-ядерным 16-поточным Ryzen 7 5800X, на 7-16 %, то в дисциплинах с задействованием AVX-512 новинка приближается вплотную или даже обходит оппонента «красной команды», что влияет и на итоговый результат, основанный на достижениях CPU во всех тестах (Aggregated CPU Score): новая модель Intel уступает процессору AMD всего лишь 1.5 % и обгоняет Core i9-9900K на впечатляющие 37.8 %.
Приемы использования масочных регистров в AVX512 коде
Массив len2mask используется для преобразования числа в соответствующее число битов подряд. И вместо скалярного цикла, мы получаем всего один if, который в-принципе тоже не обязателен, поскольку в случае маски состоящей из одних нулей, чтение и запись не будут осуществляться.
Для достижения максимальной производительности рекомендуется выравнивать данные на ширину кэш линии, а загрузки осуществлять по выровненному на ширину регистра адресу. В Skylake ширина кэш линии по прежнему 64 байта, поэтому, в нашем коде мы можем добавить такое выравнивание по pDst опять же с помощью масочных операций, но только до основного цикла.
Код стал выглядеть короче, и при достаточно длинной последовательности вычислений, затраты на вычисление маски в каждой итерации на таком фоне могут оказаться незначительными.
Пример 2. Маска как непосредственная часть реализуемого алгоритма.
Функция ищет минимальный по величине пиксель внутри квадрата 3×3. Входная маска pMask представляет собой массив из 3×3=9 байтов. Если значение байта не равно нулю, то входной пиксель из квадрата 3×3 участвует в поиске, если равно, то не участвует.
Вначале формируется массив масок __mmask msk[9]. Каждая маска получается заменой байта из pMask на бит (0 на 0, все другие значения на 1) и этот бит размножается на 16 элементов. Основной цикл загружает по этой маске 16 элементов. Причем, если элемент не участвует в поиске, то он и не будет загружен. В данном коде также с помощью масок обрабатывается и хвост, мы просто выполняем операцию & над маской операции морфологии и маской хвоста.
Конечно, продемонстрированый код не совсем оптимален, однако он демонструет саму идею, а усложнение кода привело бы к потере наглядности.
Пример 3. Инструкции семейства expand/compress
Еще в первом 256 битном наборе инструкций AVX регистры были разделены барьером на 2 части, называемые lane. Большинство векторных инструкции независимо обрабатывают эти части. Выглядит это как 2 параллельные SSE инструкции. В avx512 регистр разделяется уже на четыре 128-битные части по четыре float/int элемента. А во многих алгоритмах обработки изображений используются три канала и объединение их по 4 довольно проблематично. В этом случае можно рассмотреть возможность использования инструкций вида expand/compress
__m512 _mm512_mask_expandloadu_ps (__m512 src, __mmask16 k, void const* mem_addr)
void _mm512_mask_compressstoreu_ps (void* base_addr, __mmask16 k, __m512 a)
Инструкция _mm512_mask_expandloadu_ps загружает из памяти непрерывный блок float данных длиной равной количеству единичных бит в маске. Таким образом может быть загружен блок длиной от 0 до 16 элементов. В регистр-приемник данные помещаются следующим образом. Начиная с самого младшего бита маски проверяется, если бит равен 1, то элемент из памяти записывается в регистр, если 0, то переходим к рассмотрению следующего бита и того же самого элемента, рис. 3.1
Рис. 3.1 Демонстрация работы _mm512_mask_expandloadu_ps
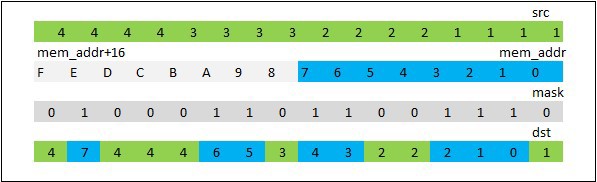
Видно, что область памяти как бы “растягивается” (expand) по всему 512 битному регистру. Инструкция _mm512_mask_compressstoreu_ps работает в противоположную сторону — “сжимает”(compress) регистр по маске и записывает в непрерывную область памяти.
Итак, допустим нам необходимо перейти из цветового пространства RGB в XYZ.
С помощью _mm512_mask_expandloadu_ps мы помещаем 4 пикселя в разные lane, после чего последовательно формируем r3r3r3r3 … r0r0r0, …g0g0g0, b0b0b0 и умножаем на коэффициенты преобразования. Для проверки переполнения также используются операции с масками _mm512_mask_max/min_ps. Запись преобразованных данных обратно в память выполняется командой _mm512_mask_compressstoreu_ps. В этой функции для обработки хвоста также можно использовать маски, в зависимости от длины хвоста.
Пример 4. Векторизация ветвления
Таких if в реализуемом алгоритме может быть несколько, для них можно завести новые маски до тех пор пока код будет быстрее скалярного.
В действительности, компилятор icc вполне способен векторизовать код 4.1 Для этого достаточно всего лишь добавить ключевое слово restrict к указателям pSrc1 и pDst и ключ –Qrestrict.
Напомню, что модификатор restrict указывает компилятору, что доступ к объекту осуществляется только через этот указатель и таким образом вектора pSrc1 и pDst не пересекаются, что и делает возможной векторизацию.
Измерения на внутреннем симуляторе CPU с поддержкоий avx512 показывают, что производительность практически равна производительности нашего avx512 кода. Т.е компилятор тоже умеет эффективно использовать маски
Казалось бы на этом все. Но посмотрим, что будет если мы слегка модицифируем нашу функцию и внесем в нее зависимость между итерациями.
Функция также осуществляет интерполяцию по соседним пикселям, и если разница по вертикали и горизонтали одинакова, то используется то направление интерполяции, которое было в предыдущей итерации. На алгоритмах такого рода снижается эффект от механизма out of order, реализованных в современных cpu из-за того, что образуется длинная последовательность зависимых операций. Компилятор также теперь не может векторизовать цикл и производительность стала в 17 раз медленее. Т.е. как раз примерно на ширину в 16 float элементов в AVX512 регистре. Теперь попробуем как-то модифицировать и наш avx512 код, чтобы получить хоть какое то ускорение.
Введем в рассмотрение следующие бинарные маски-переменные
mskV(n) – для n-го элемента V разница минимальна
mskE(n) – для n-го элемента V и H разницы одинаковы
mskD(n) – для n-го элемента использована V интерполяция.
Теперь построим таблицу истинности, как формируется mskD(n) в зависимости от mskV(n),mskE(n) и предыдущей использованой маски – mskD(n-1) 
Из таблицы следует, что
mskD(n) = mskV(n) | (mskE(n)&mskD(n-1)),
что в общем-то и так было очевидно. Итак наш avx512 код будет выглядеть следующим образом.
1.7X раз быстрее чем С-шный. Ну хотя бы что-то удалось получить. Следующая возможная оптимизация заключается в том, что можно предварительно просчитать все комбинации масок. На каждой итерации по 16 элементов у нас есть 16 бит mskV, 16 бит mskE, и 1 бит от предыдущей итерации. Итого 2^33 степени вариантов для mskD. Это много. А что если обрабатывать не по 16, а по 8 элементов за итерацию? Получаем 2^(8+8+1)=128кбайт таблицу. А это вполне вменяемый размер. Создаем функцию инициализации.
4.1X раз быстрее. Можно добававить обработку по 16 элементов, но к таблице придется обратиться дважды за итерацию.
5.6X по сравнению с изначальным С кодом, что очень даже неплохо для алгоритма с обратной связью. Таким образом комбинация масочного регистра и предварительно вычисленной таблицы позволяет получить существенный прирост производительности. Код такого рода вовсе не является специально подобранным для статьи и встречается к примеру в алгоритмах обработки фотографий, при конвертации изображения из RAW формата. Правда там используются целочисленные значения, но такой табличный метод вполне можно применить и для них.
«Пусть Intel начнёт решать реальные проблемы, вместо создания магических инструкций». Создатель Linux раскритиковал Intel
За поддержку AVX-512
Набор инструкций AVX-512 иногда рассматривают, как преимущество некоторых процессоров Intel. Однако в большинстве случаев, особенно, если речь идёт об обычных потребительских CPU, поддержка AVX-512 не имеет особого смысла.

Создатель Linux Линус Торвальдс (Linus Torvalds) и вовсе считает, что Intel должна прекратить реализовывать AVX-512 в своих процессорах, сконцентрировавшись на более важных направлениях.
Я надеюсь, что AVX-512 умрёт мучительной смертью, и Intel начнёт решать реальные проблемы, вместо того, чтобы пытаться создавать магические инструкции, чтобы затем создавать тесты, на которых они могут хорошо выглядеть.
Я надеюсь, что Intel вернется к основам и сконцентрируется на обычном коде, который не нацелен на HPC (High Performance Computing) или какие-то другие бессмысленные особые случаи.
У AVX-512 есть свои минусы. Я бы предпочел, чтобы транзисторный бюджет использовался для других вещей, которые гораздо более актуальны. Даже если это все еще математика FP (в GPU, а не AVX-512). Или просто дайте мне больше ядер (с хорошей однопоточной производительностью, но без мусора вроде AVX512), как делает AMD.
Я думаю, что AVX-512 — совершенно неправильная вещь. Это моя любимая мозоль. Это яркий пример того, что Intel сделала неправильно, отчасти просто увеличив фрагментацию рынка.
Данное высказываение Торвальдс написал на фоне слухов о том, что в процессорах Intel линейки Alder Lake поддержки AVX-512, судя по всему, не будет. К слову, сам Торвальдс недавно впервые за 15 лет сменил процессор Intel на продукт AMD.
Даунклокинг Ice Lake AVX-512

Это короткий пост об исследовании поведения AVX2 и AVX-512 в связи с лицензионным даунклокингом новых чипов Intel Ice Lake.
Лицензионный даунклокинг 1 — это малоизвестный эффект, при котором пределы частот опускаются ниже номинальных в случае выполнения определённых SIMD-инструкций, особенно тяжёлых инструкций с плавающей запятой или инструкций с 512-битной шириной.
Информация по ссылкам написана в контексте Skylake-SP (SKX, серверной архитектуры Intel Skylake, включающей в себя Skylake-SP, Skylake-X и Skylake-W), которые стали первым поколением чипов с поддержкой AVX-512.
Какова же ситуация с Ice Lake — с самыми новыми чипами, поддерживающими как инструкции AVX-512 из SKX, так и имеющими совершенно новый набор инструкций AVX-512? Нам придётся смотреть на эти новые инструкции издалека, и мы никогда не сможем воспользоваться ими из-за даунклокинга?
Прочитайте статью, чтобы разобраться, или просто перейдите к разделу «Итоги».
AVX-Turbo
Мы будем использовать утилиту avx-turbo для измерения зависимости частот от количества ядер и набора инструкций. Этот инструмент работает просто: выполняет заданный набор инструкций на заданном количестве ядер, измеряя частоту, достигнутую во время теста.
Суммарно мы используем пять тестов для проверки каждого сочетания лёгких и тяжёлых 256-битных и 512-битных инструкций, а также скалярных инструкций (128-битный SIMD ведёт себя так же, как и скалярные инструкции), введя в командной строке:
Результаты Ice Lake
Я запускал avx-turbo описанным выше образом на Ice Lake i5-1035G4 — клиентском процессоре Ice Lake среднего диапазона мощности, работающего с частотой до 3,7 ГГц. Полные результаты скрыты в gist, а здесь я представлю самые важные результаты по полученным частотам (все значения указаны в ГГц):
| Набор инструкций | Активные ядра | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| Скалярные/128-битные | 3,7 | 3,6 | 3,3 | 3,3 |
| Лёгкие 256-битные | 3,7 | 3,6 | 3,3 | 3,3 |
| Тяжёлые 256-битные | 3,7 | 3,6 | 3,3 | 3,3 |
| Лёгкие 512-битные | 3,6 | 3,6 | 3,3 | 3,3 |
| Тяжёлые 512-битные | 3,6 | 3,6 | 3,3 | 3,3 |
Как и ожидалось, максимальное падение частоты происходит при увеличении количества активных ядер, но просмотрите вниз каждый столбец, чтобы оценить влияние на категории инструкций. Вдоль этой оси почти никакого даунклокинга не происходит! Только при одном активном ядре возникает снижение при широких инструкциях, и всего лишь на жалкие 100 МГц: с 3 700 МГц до 3 600 МГц при использовании любых 512-битных инструкций.
Во всех остальных случаях, в том числе и при нескольких активных ядрах, а также тяжёлых 256-битных лицензионный даунклокинг равен нулю: всё работает так же быстро, как и со скалярными инструкциями.
Виды лицензий
Здесь существует и ещё одно изменение. В архитектуре SKX есть три лицензии, или категории инструкций, относящихся к даунклокингу: L0, L1 и L2. Здесь, в клиентском ICL, их всего две 3 и они неточно соответствуют трём категориям в SKX.
Лицензии в SKX соответствуют ширине и тяжести инструкций следующим образом:
В частности, обратите внимание на то, что тяжёлые 256-битные инструкции имеют ту же лицензию, что и лёгкие 512-битные.
В клиентских ICL схема такова:
Ну и что?
Ну и что же из этого?
По меньшей мере, это означает, что нам нужно изменить нашу мысленную модель затратности инструкций AVX-512 относительно частот. Вместо того, чтобы говорить, что они «обычно вызывают значительный даунклокинг», про этот чип Ice Lake можно сказать, что AVX-512 вызывает незначительный или нулевой лицензионный даунклокинг, и я предполагаю, что это справедливо также для других клиентских чипов Ice Lake.
Однако это смена наших ожиданий имеет важный изъян: лицензионный даунклокинг не является единственным источником даунклокинга. Мы также можем столкнуться с ограничениями мощности, тепловыделения или тока. Некоторые конфигурации способны выполнять широкие SIMD-инструкции на всех ядрах только в течение короткого времени, а затем превышают пределы рабочей мощности. В моём случае ноутбук за 250 долларов, на котором проводилось тестирование, имел чрезвычайно плохое охлаждение, и вместо ограничений мощности я столкнулся с пределом тепловыделения (100°C) всего спустя несколько секунд после запуска тяжёлых инструкций на всех ядрах.
Однако эти прочие ограничения качественно отличаются от лицензионных ограничений. В основном 5 они ограничивают по принципу плати за то, что используешь: если вы используете широкие или тяжёлые инструкции (или оба вида), то это вызывает лишь микроскопическое повышение мощности или тепловыделения, связанное только с этими инструкциями. Это непохоже на некоторые лицензионные эффекты, при которых возникают изменения частот в пределах ядра или целого чипа, значительное время влияющие последующее выполнение, не связанное с такими типами инструкций.
Итоги
Вот, какие выводы я сделал.
Обсуждения и общение
Этот пост можно обсудить на on Hacker News.
Если у вас есть вопросы или другая обратная связь, то можете оставить комментарий к оригиналу поста. Мне были бы также интересны результаты на других чипах ICL, например, на версиях i3 и i7: дайте мне знать, если у вас они есть, и мы сможем получить результаты.
AVX-512, инструкции Intel SIMD для искусственного интеллекта и мультимедиа
Инструкции AVX были впервые реализованы в процессорах Intel, заменив старые инструкции SSE. С тех пор они стали стандартными инструкциями SIMD для процессоров x86 в двух вариантах, 128-битном и 256-битном, которые также были приняты AMD. С другой стороны, если говорить об инструкциях AVX-512, ситуация иная, и они используются только в процессорах Intel.
Что такое SIMD-модуль?
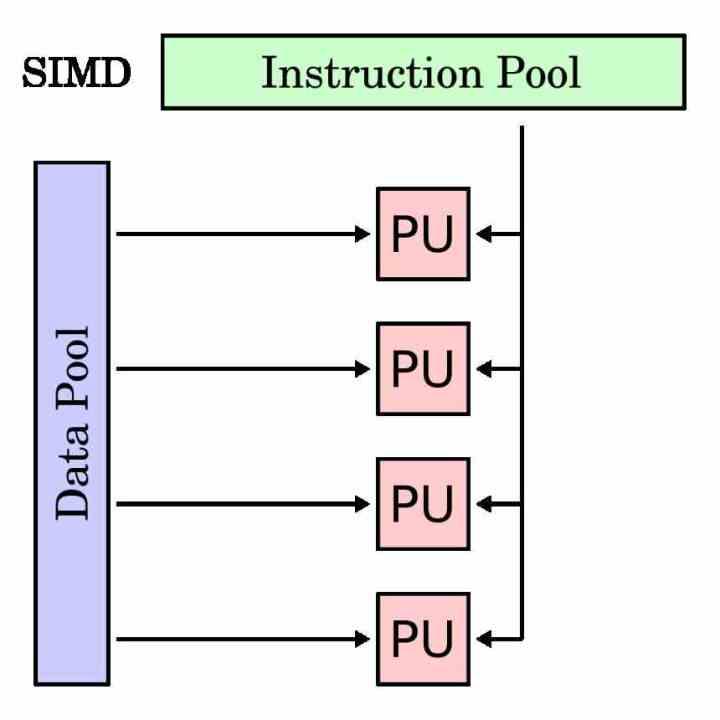
Блоки SIMD традиционно использовались для ускорения так называемых мультимедийных процессов, в которых необходимо манипулировать различными данными в соответствии с одними и теми же инструкциями. Блоки SIMD позволяют распараллеливать выполнение программы в этих частях и ускорить время выполнения.
В каждом процессоре, чтобы отделить исполнительные блоки SIMD от традиционных, они имеют собственное подмножество инструкций, которое обычно является зеркалом скалярных инструкций или с одним операндом. Хотя есть случаи, которые невозможно сделать со скалярным модулем и они относятся исключительно к модулям SIMD.
История AVX-512

Инструкции AVX, Advanced Vector eXtensions, находятся внутри процессоров Intel в течение многих лет, но происхождение инструкций AVX-512 отличается от остальных. Причина? Его источником является проект Intel Larrabee, попытка Intel в конце 2000-х годов создать GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР которые в конечном итоге стали ускорителями Xeon Phi. Серия процессоров, предназначенных для высокопроизводительных вычислений, выпущенная Intel несколько лет назад.
Архитектура Xeon Phi / Larrabee включает специальную версию инструкций AVX с размером регистра накопителя 512 бит, что означает, что они могут работать с 16 32-битными данными. Причина такой суммы связана с тем фактом, что типичное соотношение операций на тексель для графического процессора обычно составляет 16: 1. Не будем забывать, что инструкции AVX-512 взяты из неудачного проекта Larrabee и были перенесены оттуда в Xeon Phi.
По сей день Xeon Phi больше не существует, причина в том, что то же самое можно сделать с помощью традиционного графического процессора для вычислений. Это заставило Intel передать эти инструкции своей основной линейке процессоров.
Тарабарщина в виде инструкций AVX-512
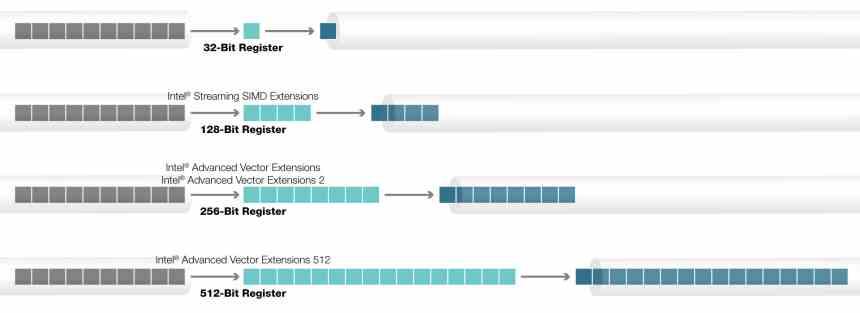
Инструкции AVX-512 не являются однородным блоком, который реализован на 100%, а скорее имеют различные расширения, которые, в зависимости от типа процессора, были добавлены или нет. Все процессоры называются AVX512F, но есть дополнительные инструкции, которые не являются частью исходного набора команд и которые Intel со временем добавила.
Почему AMD еще не реализовала это на своих процессорах?

Причина этого очень проста: AMD стремится к комбинированному использованию своих ЦП и ГП при ускорении определенных типов приложений. Давайте не будем забывать происхождение AVX-512 в вышедшем из строя графическом процессоре от Intel и AMD. Благодаря своим графическим процессорам Radeon им не нужны инструкции AVX-512.
Вот почему инструкции AVX-512 являются эксклюзивными для процессоров Intel, не для полной исключительности, а потому, что AMD не заинтересована в использовании этого типа инструкций в своих ЦП, поскольку она намерена продавать свои графические процессоры, особенно недавно выпущенный AMD Instinct. высокопроизводительные вычисления с архитектурой CDNA.
Есть ли будущее у инструкций AVX-512?

Что ж, мы не знаем, это зависит от успеха Intel Xe, особенно Xe-HPC, который даст Intel архитектуру GPU на уровне AMD и NVIDIA. Это означает конфликт между инструкциями Intel Xe и AVX-512 для решения тех же проблем.
Проблема с AVX-512 заключается в том, что активация части процессора, которая его использует, в конечном итоге влияет на тактовую частоту процессора, снижая ее примерно на 25% в программе, которая использует эти инструкции в определенные моменты. Кроме того, его инструкции предназначены для высокопроизводительных вычислений и приложений искусственного интеллекта, которые не важны в том, что является домашним процессором, а появление специализированных блоков делает его пустой тратой транзисторов и пространства.
На самом деле ускорители или процессоры для конкретной области медленно заменяют блоки SIMD в ЦП, поскольку они могут делать то же самое, занимая меньше места и с незначительным энергопотреблением по сравнению.



